Ambari集群里操作时典型权限问题put: `/home/bigdata/1.txt': No such file or directory的解决方案(图文详解)
不多说,直接上干货!
问题详情
明明put该有的文件在,可是怎么提示的是文件找不到的错误呢?
我就纳闷了put: `/home/bigdata/1.txt': No such file or directory
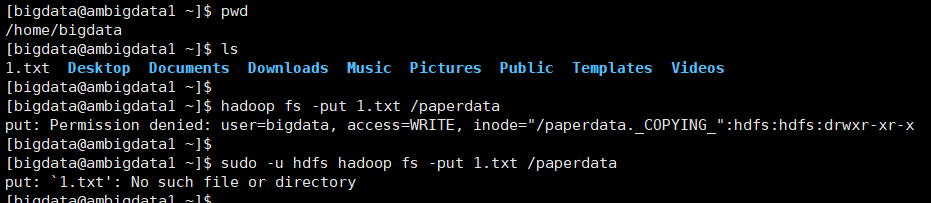
[bigdata@ambigdata1 ~]$ pwd
/home/bigdata
[bigdata@ambigdata1 ~]$ ls
.txt Desktop Documents Downloads Music Pictures Public Templates Videos
[bigdata@ambigdata1 ~]$
[bigdata@ambigdata1 ~]$ hadoop fs -put .txt /paperdata
put: Permission denied: user=bigdata, access=WRITE, inode="/paperdata._COPYING_":hdfs:hdfs:drwxr-xr-x
[bigdata@ambigdata1 ~]$
[bigdata@ambigdata1 ~]$ sudo -u hdfs hadoop fs -put .txt /paperdata
put: `.txt': No such file or directory
[bigdata@ambigdata1 ~]$
问题原因
其实是,权限的问题。
刚开始,我也纳闷,报没有文件错误,经过排查是权限问题,同时,在hdfs用户切换过来也得到了验证。
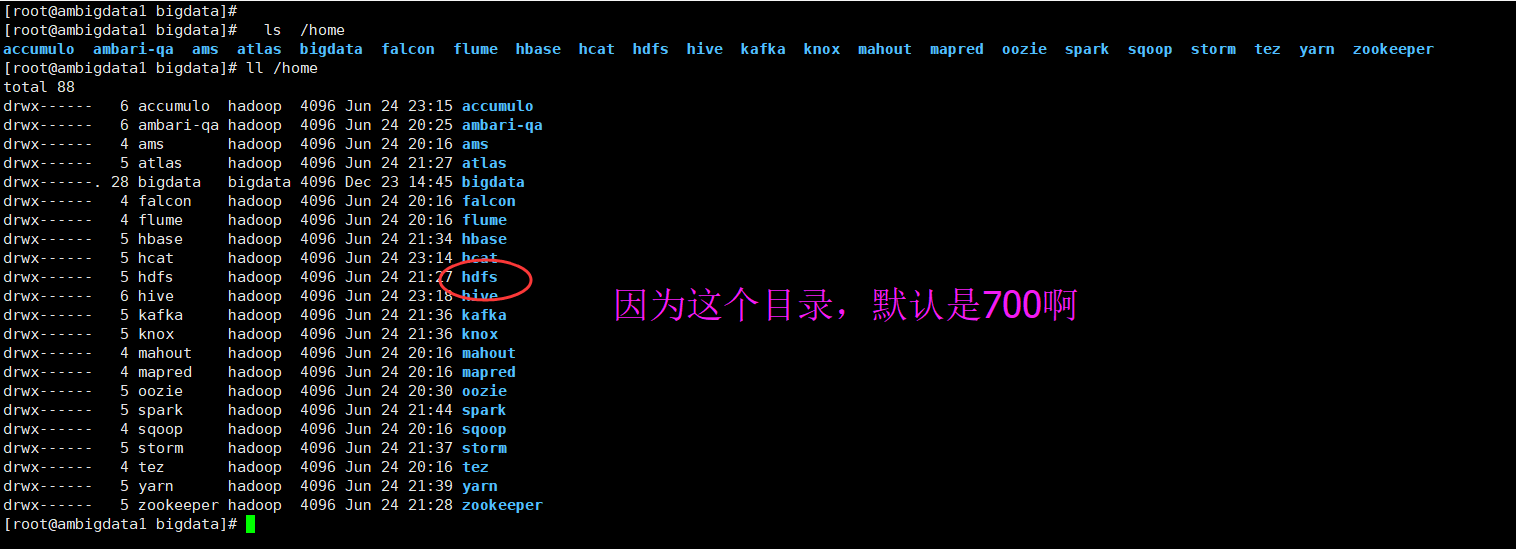
除了自己谁都 操作不了。
bigdata用户是我安装ambari集群时候的用户,是除了自己bigdata这个用户之外,以及root用户,其余全都无法操作。
问题解决办法
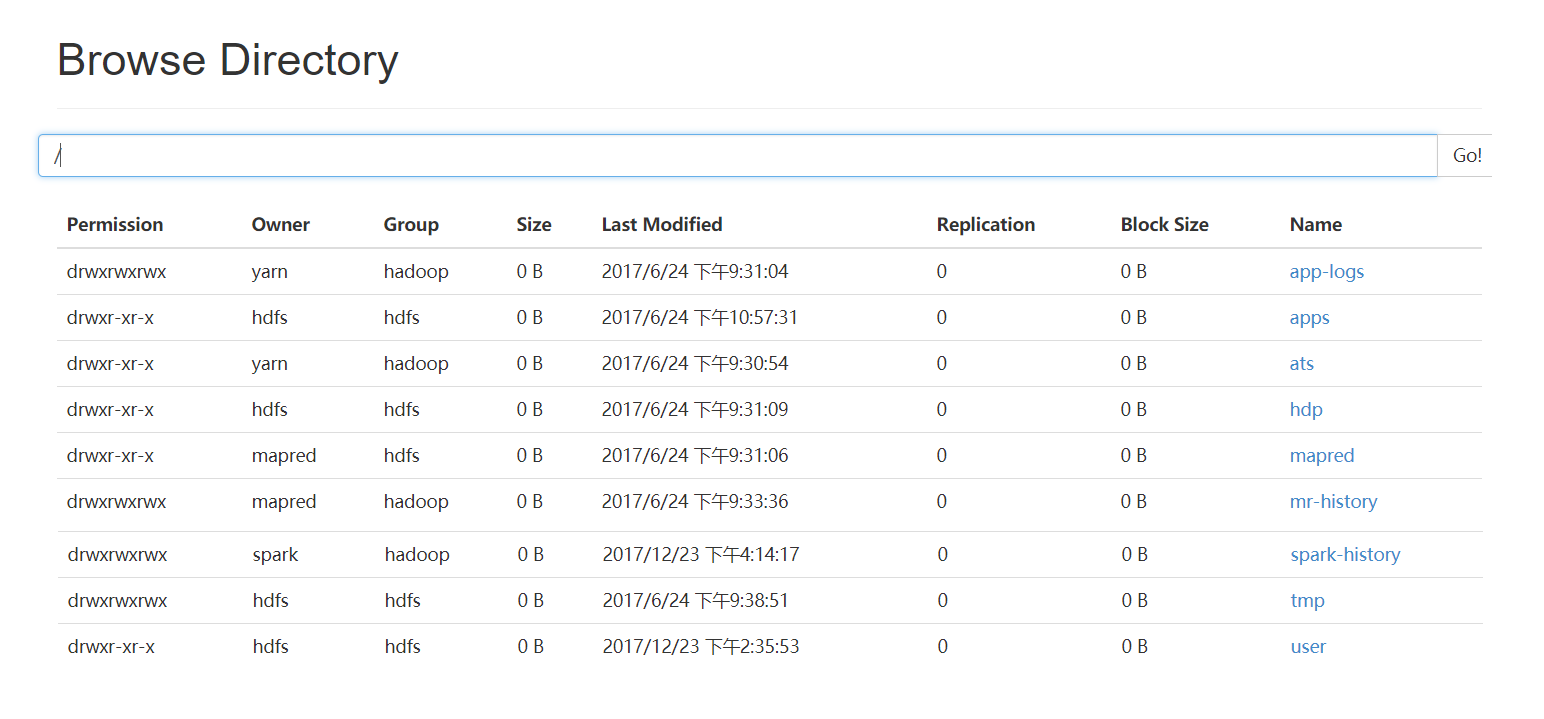
[bigdata@ambigdata1 ~]$ sudo -u hdfs hadoop fs -mkdir /papaerdata
[bigdata@ambigdata1 ~]$ sudo -u hdfs hadoop fs -chmod -R 777 /papaerdata
[root@ambigdata1 ~]# chmod 755 -R /root
[root@ambigdata1 bigdata]# sudo -u hdfs hadoop fs -chmod -R 777 /paperdata
[root@ambigdata1 bigdata]# hadoop fs -put 1.txt /paperdata
成功!
切换到hdfs上验证下(必须得先从)
[bigdata@ambigdata1 ~]$ su root
Password:
[root@ambigdata1 bigdata]# su hdfs
[hdfs@ambigdata1 bigdata]$
[hdfs@ambigdata1 ~]$ touch 2.txt
[hdfs@ambigdata1 ~]$ hadoop fs -put 2.txt /paperdata
[hdfs@ambigdata1 ~]$
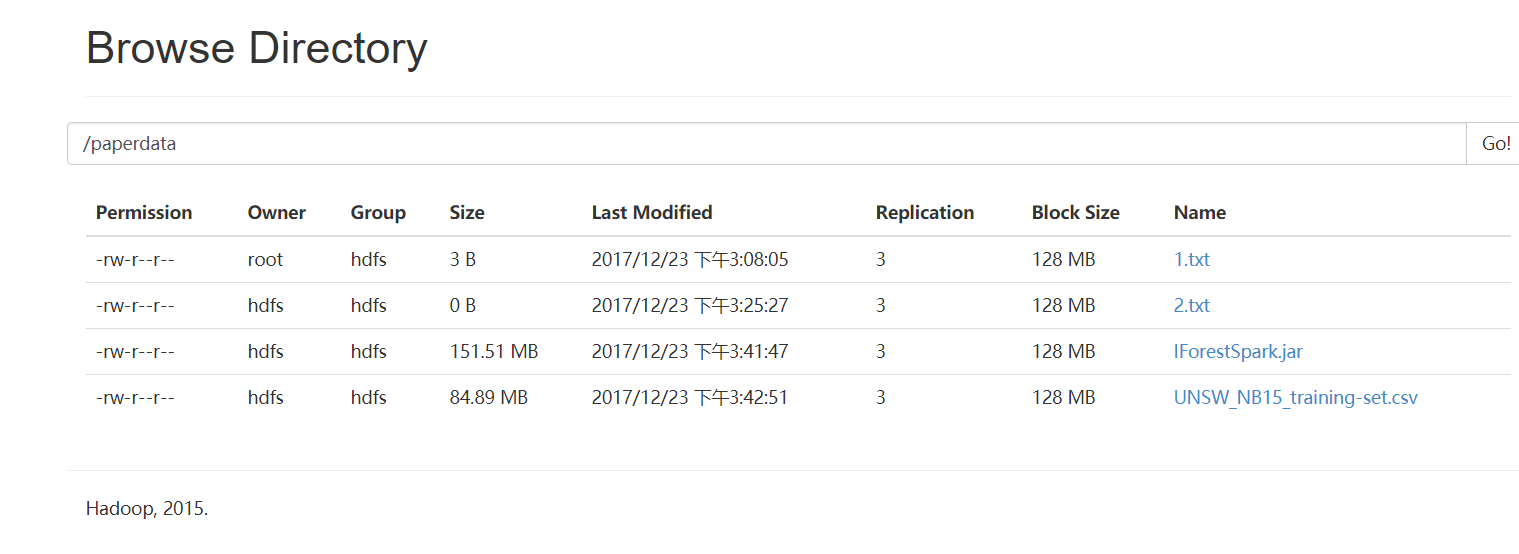
如果想删除,则
[root@ambigdata1 bigdata]# sudo -u hdfs hadoop fs -rm -r /paperdata/1.txt
17/12/23 16:50:18 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 360 minutes, Emptier interval = 0 minutes.
Moved: 'hdfs://ambigdata1:8020/paperdata1.txt' to trash at: hdfs://ambigdata1:8020/user/hdfs/.Trash/Current
[root@ambigdata1 bigdata]#
spark-submit --master yarn-cluster --num-executors 4 --driver-memory 4g --executor-memory 4g --executor-cores 4 --class iforest.TestIF hdfs://ambigdata1:9000/paperdata/IForestSpark.jar hdfs://ambigdata1:9000/paperdata/UNSW-NB15_change.csv hdfs://ambigdata1:9000/paperdata/out
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



Ambari集群里操作时典型权限问题put: `/home/bigdata/1.txt': No such file or directory的解决方案(图文详解)的更多相关文章
- 给Ambari集群里安装可视化分析利器工具Hue步骤(图文详解)
扩展博客 以下,是我在手动的CDH版本平台下,安装Hue. CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz) ...
- 给ambari集群里的kafka安装基于web的kafka管理工具Kafka-manager(图文详解)
不多说,直接上干货! 参考博客 基于Web的Kafka管理器工具之Kafka-manager的编译部署详细安装 (支持kafka0.8.0.9和0.10以后版本)(图文详解)(默认端口或任意自定义端口 ...
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- ambari集群里如何正确删除历史修改记录(图文详解)
不多说,直接上干货! 答:这些你想删除的话得得去数据库里删除,最好别删除 . 现在默认就是使用好的配置 欢迎大家,加入我的微信公众号:大数据躺过的坑 人工智 ...
- CentOS5/6/7系统下搭建安装Amabari大数据集群时出现SSLError: Failed to connect. Please check openssl library versions.错误的解决办法(图文详解)
不多说,直接上干货! ========================== Creating target directory... ========================== Comman ...
- ClouderManger搭建大数据集群时ERROR 2003 (HY000): Can't connect to MySQL server on 'ubuntucmbigdata1' (111)的问题解决(图文详解)
问题详情 相关问题的场景,是在我下面的这篇博客里 Cloudera Manager安装之利用parcels方式(在线或离线)安装3或4节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(Ubun ...
- Spark Mllib里如何将如温度、湿度和风速等数值特征字段用除以***进行标准化(图文详解)
不多说,直接上干货! 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第18章 决策树回归分类Bike Sharing数据集
- 给Clouderamanager集群里安装可视化分析利器工具Hue步骤(图文详解)
扩展博客 以下,是我在手动的CDH版本,安装Hue. CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz)(博主 ...
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
这个很简单,在集群机器里,选择就是了,本来自带就有Impala的. 扩展博客 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
随机推荐
- 20145233计算机病毒实践九之IDA的使用
20145233计算机病毒实践之IDA的使用 PSLIST导出函数做了什么 这个函数是一个export函数,所以在view中选择export 查到后,双击打开这个函数的位置 仔细看这个函数可以发现这个 ...
- 查看JVM
通过jconsole.exe来查看,jconsole.exe所在目录为/%JAVA_HOME%/bin/jconsole.exe 需要配置: -Dcom.sun.management.jmxrem ...
- (zxing.net)一维码Code 128的简介、实现与解码
一.简介 一维码Code 128:1981年推出,是一种长度可变.连续性的字母数字条码.与其他一维条码比较起来,相对较为复杂,支持的字元也相对较多,又有不同的编码方式可供交互运用,因此其应用弹性也较大 ...
- double? int?
C# 值类型加上?表示可空类型(Nullable 结构),就是一种特殊的值类型,它的值可以为null 例: int? float? stirng? double?
- ajaxfileupload插件上传图片功能,用MVC和aspx做后台各写了一个案例
HTML代码 和js 代码 @{ Layout = null; } <!DOCTYPE html> <html> <head> <meta name=&quo ...
- 使用WebService调用第三方服务
场景 某个系统服务由第三方提供,我方要使用到这个这个服务,就可以使用WebService的方式. 什么是WebService 关于什么WebService,官方是这么解释的: Web service是 ...
- docker启动时报错
docker安装成功后,启动时报错. 1.后来排查后发现yum install docker安装的是从test存储库中安装的. 后来我指定了特定的版本后,而且从stable存储库安装的,以后再启动就好 ...
- C语言中printf与i++,C++中的cout
一,printf与i++ 1,C语言中的printf是自右向左输出,. 2,而i++与++i不同的 i++首先取得i的值,下一行时候i = i + 1: ++i,首先i = i + 1,再取得i的值. ...
- 【FAQ】tomcat启动jdk版本不一致
一.tomcat7.exe与startup.bat的区别: 1.这两个都可以启动tomcat,但tomcat7.exe必须安装了服务才能启动,而startup.bat不需要 2.另外一个区别是它们启动 ...
- 推荐 9 个样式化组件的 React UI 库
简评:喜欢 CSS in JS 吗?本文将介绍一些使用样式组件所构建的 React UI 库,相信你会很感兴趣的. 在 React 社区,对 UI 组件进行样式化的讨论逐步从 CSS 模块到内联 CS ...