python爬虫学习(二):定向爬虫例子-->使用BeautifulSoup爬取"软科中国最好大学排名-生源质量排名2018",并把结果写进txt文件
在正式爬取之前,先做一个试验,看一下爬取的数据对象的类型是如何转换为列表的:
写一个html文档:
x.html
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title">
<a>The demo python introduces several python courses.</a>
<a href="http://www.icourse163.org/course/BIT-133" class="py1" id="link1">Basic Python</a>
</p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and
<a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>
</p>
</body></html>
# coding:utf-8 from bs4 import BeautifulSoup
import requests
import bs4 soup = BeautifulSoup(open('D:/x.html', encoding='utf-8'), "html.parser")
print(soup.find('body',).children) # .children返回可迭代对象,不是列表,需要用for循环遍历其中的内容 for t in soup.find('body').children: 迭代<body>标签的儿子节点
if isinstance(t, bs4.element.Tag): # 判断子节点是否为Tag对象(因为子节点会包含如换行符之类的节点)
print('body的子标签的内容是:', t) # 查看t变量获得的对象内容,body的子标签为p标签,一组<p></p>表示一个对象
print('t的类型是:', type(t)) # 查看t的类型
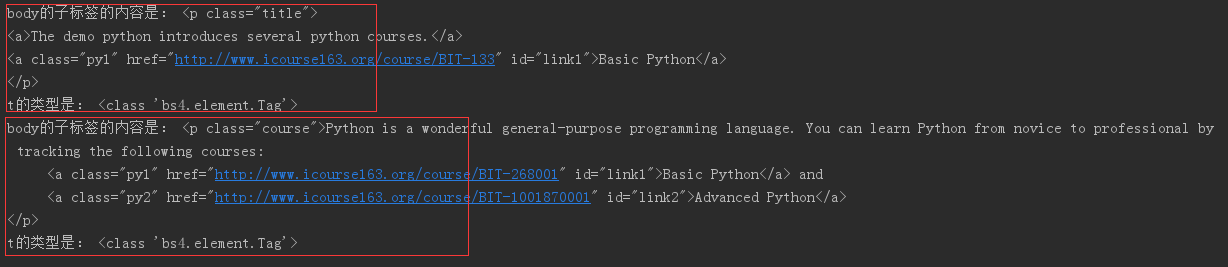
可以看到每个t对象的类型是bs4.element.Tag,也就是标签对象。
那么,如果要从每个t对象中获取a标签的内容,并把所有a标签都保存到一个列表中,该如何做?
可以使用:
list = t('a') # t('a')会生成一个bs4.element.ResultSet类型的数据对象,实际上就是Tag列表
for t in soup.find('body').children:
if isinstance(t, bs4.element.Tag): # 判断子标签是否为Tag对象(因为子节点会包含如换行符之类的节点)
# print('body的子标签的内容是:', t) # 查看t变量获得的对象内容
# print('t的类型是:', type(t)) # 查看t的类型
list = t('a') # 循环获取每个t对象中的所有a标签,并保存到一个列表中
print(list)
print(type(list))
print('每个p标签的第一个a标签的内容:', list[0].string) # a标签保存到列表后,便可以利用列表方法解析出其中的具体每个a标签对象,并利用.string获取标签字符串

接下来就可以正式编写爬虫了:
分析网页源代码
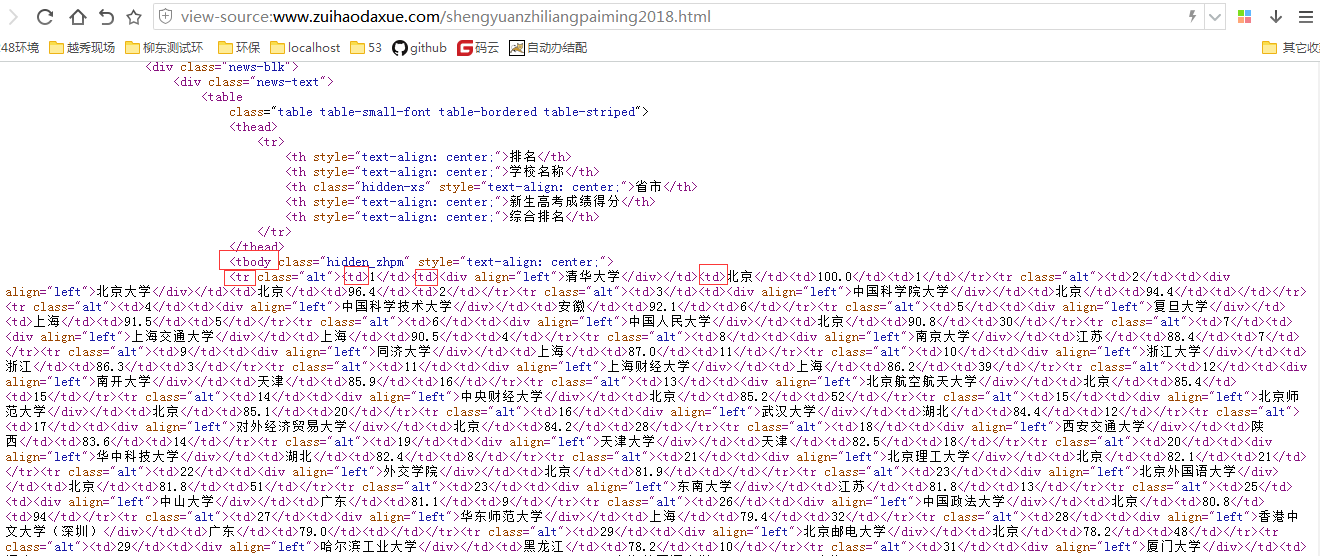
可以看到需要的一些信息如大学排名、大学名称、地址、分数等分别在如图标注的地方,每个大学信息所在的标签结构如下:所有大学信息都在<tbody>标签下,每个大学都在各自的<tr>标签,然后大学自身的排名、名称、地址等信息都分别由一个<td>标签包裹。
思路如下:先找到<tbody>下的所有标签内容,然后再从中找出所有<tr>标签内容(为什么不直接用find_all()找<tr>?因为不只有我们需要的大学信息用到了<tr>标签,<tbody>之外也有用到<tr>标签来包裹内容的)。
我要把每个学校的“排名、名称、地址、分数”的值都取出来,并且把每组数据都各自装在一个列表中,然后再把每个列表依次加到一个大列表里
(1)直接处理数据
from bs4 import BeautifulSoup
import requests
import bs4 url = 'http://www.zuihaodaxue.com/shengyuanzhiliangpaiming2018.html'
r = requests.get(url) r.encoding = r.apparent_encoding # 转换编码,不然中文会显示乱码,也可以r.encoding = 'utf-8'
html = r.text
soup = BeautifulSoup(html, 'html.parser') # 获取爬取网页的BeautifulSoup对象 for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
td = tr('td')
print(td)
t = [td[0].string, td[1].string, td[2].string, td[3].string] # 把每个学校解析出的数据各自装到一个列表中
print(t)
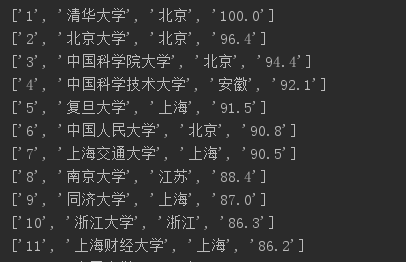
打印td的结果:

打印t的结果如下,其实排名信息已经可以看出来了
然后依次把每个大学信息写入一个文本文档:
from bs4 import BeautifulSoup
import requests
import bs4 url = 'http://www.zuihaodaxue.com/shengyuanzhiliangpaiming2018.html'
r = requests.get(url) r.encoding = r.apparent_encoding # 转换编码,不然中文会显示乱码,也可以r.encoding = 'utf-8'
html = r.text
soup = BeautifulSoup(html, 'html.parser') # 获取爬取网页的BeautifulSoup对象 for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
td = tr('td')
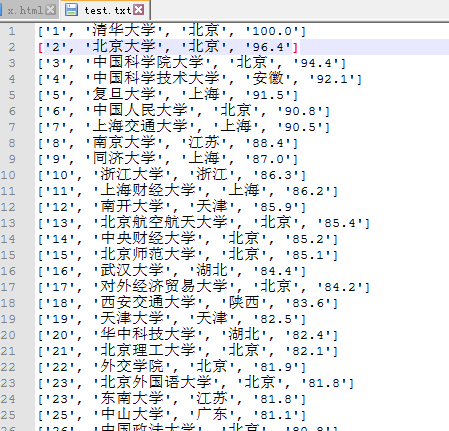
t = [td[0].string, td[1].string, td[2].string, td[3].string] # 把每个学校解析出的数据各自装到一个列表中print(t)
with open('D:/test.txt','a') as data: # 以'a'模式打开文件,即可不停的追加写入而不改变原内容
print(t, file=data)
(2)把代码封装,写到函数中
# coding:utf-8
import requests
import bs4
from bs4 import BeautifulSoup def get_html(url):
"""定义获取网页源码函数"""
try:
r = requests.get(url, timeout=20)
r.encoding = r.apparent_encoding
return r.text
except:
return None def get_data(html, list):
"""定义从网页源码获取数据并处理数据函数"""
soup = BeautifulSoup(html, 'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
td = tr('td')
t = [td[0].string, td[1].string, td[2].string, td[3].string] # 把每个学校解析处的数据各自装到一个列表中
list.append(t) # 把每个学校信息列表都追加到一个大列表中,方便后面写入文件
# return list # 不能加return,造成的后果就是第一次循环时就把结果返回出去了,只取到了第一条数据 def write_data(ulist, num): # num参数,控制提取多少组数据写入文件
"""定义把数据写入文件函数"""
for i in range(num):
u = ulist[i]
with open('D:/test.txt', 'a') as data:
print(u, file=data) if __name__ == '__main__':
list = [] # 我之前是把list=[]放到get_data()函数的for循环里面了,导致每次循环都会先清空列表,然后再追加数据,结果最后遍历完只剩最后一组数据。。。
url = 'http://www.zuihaodaxue.com/shengyuanzhiliangpaiming2018.html'
html = get_html(url)
get_data(html, list)
write_data(list, 20)

把结果输出到屏幕(老师给出的代码)
# coding: utf-8 import requests
from bs4 import BeautifulSoup
import bs4 # def GetHTMLText(url):
# try:
# r = requests.get(url, timeout=30)
# r.raise_for_status()
# r.encoding = r.apparent_encoding
# return r.text
# except:
# return ""
#
#
# def fillUnivList(ulist, html):
# soup = BeautifulSoup(html, "html.parser")
# for tr in soup.find('tbody').children:
# if isinstance(tr, bs4.element.Tag):
# tds = tr('td')
# ulist.append([tds[0].string, tds[1].string, tds[2].string, tds[3].string])
#
#
#
# def printUnivList(ulist, num):
# print("{:^10}\t{:^6}\t{:^10}\t{:^10}".format('排名', '学校名称', '地区', '总分'))
# for i in range(num):
# u = ulist[i]
# print("{:^10}\t{:^6}\t{:^10}\t{:^10}".format(u[0], u[1], u[2], u[3]))
#
#
# def main():
# uinfo = []
# url = 'http://www.zuihaodaxue.com/shengyuanzhiliangpaiming2018.html'
# html = GetHTMLText(url)
# fillUnivList(uinfo, html)
# printUnivList(uinfo, 20)
# return uinfo
#
#
# if __name__ == '__main__':
# t = main()
python爬虫学习(二):定向爬虫例子-->使用BeautifulSoup爬取"软科中国最好大学排名-生源质量排名2018",并把结果写进txt文件的更多相关文章
- python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息 (1)分析网页源码 打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果 从url连接中可以得到搜索商品的关键字是 ...
- Python爬虫学习==>第十章:使用Requests+正则表达式爬取猫眼电影
学习目的: 通过一个一个简单的爬虫应用,初窥门径. 正式步骤 Step1:流程框架 抓取单页内容:利用requests请求目标站点,得到单个页面的html代码,返回结果: 正则表达式分析:根据html ...
- 爬虫学习(九)——登录获取cookie爬取
import urllib.requestimport urllib.parseimport http.cookiejar # http.cookiejar 该包是专门对网页的cookie只进行获取的 ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 转 Python爬虫入门二之爬虫基础了解
静觅 » Python爬虫入门二之爬虫基础了解 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以 ...
- Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识. 1.首先分析要爬取页面结构.可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面. 关键代码思路如下: html = getHtml(& ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- Python基础学习二
Python基础学习二 1.编码 utf-8编码:自动将英文保存为1个字符,中文3个字符.ASCll编码被囊括在内. unicode:将所有字符保存为2给字符,容纳了世界上所有的编码. 2.字符串内置 ...
随机推荐
- 04: vue生命周期和实例属性和方法
1.4 组件的生命周期 1.说明 1. Vue将组件看成是一个有生命的个体,跟人一样,定义了各个阶段, 2. 组件的生命周期:组件的创建过程 3. 组件生命周期钩子函数:当组件处在某个阶段,要执行某个 ...
- Catogory如何添加属性
一,Category结构体 typedef struct category_t { const char *name; //类的名字 classref_t cls; //类 struct method ...
- topcoder srm 679 div1
problem1 link $f[u][0],f[u][1]$表示$u$节点表示的子树去掉和不去掉节点$u$的最大权值. problem2 link 首先预处理计算任意三个蓝点组成的三角形中的蓝点个数 ...
- Oracle使用——oracle 忘记用户密码登录
背景 有时候我们忘记了oracle登录的用户密码,甚至是用户名称都不确定,应该怎么登陆呢 操作系统 CentOS7 Oracle12c 操作步骤 使用sqlplus登录系统:sqlplus / a ...
- 螺旋折线(可能是最简单的找规律)【蓝桥杯2018 C/C++ B组】
标题:螺旋折线 如图p1.png所示的螺旋折线经过平面上所有整点恰好一次. 对于整点(X, Y),我们定义它到原点的距离dis(X, Y)是从原点到(X, Y)的螺旋折线段的长度. 例如dis(0 ...
- 【做题】NOWCODER142A Ternary String——数列&欧拉定理
题意:你有一个长度为\(n\),且仅由012构成的字符串.每经过一秒,这个字符串所有1后面会插入一个0,所有2后面会插入一个1,然后会删除第一个元素.求这个字符串需要多少秒变为空串,对\(10^9+7 ...
- 【Dalston】【第三章】声明式服务调用(Feign)
当我们通过RestTemplate调用其它服务的API时,所需要的参数须在请求的URL中进行拼接,如果参数少的话或许我们还可以忍受,一旦有多个参数的话,这时拼接请求字符串就会效率低下,并且显得好傻.那 ...
- Hierarchical Question-Image Co-Attention for Visual Question Answering
Hierarchical Question-Image Co-Attention for Visual Question Answering NIPS 2016 Paper: https://arxi ...
- (zhuan) Paper Collection of Multi-Agent Reinforcement Learning (MARL)
this blog from: https://github.com/LantaoYu/MARL-Papers Paper Collection of Multi-Agent Reinforcemen ...
- java笔试总结
1. Java的IO操作中有面向字节(Byte)和面向字符(Character)两种方式.面向字节的操作为以8位为单位对二进制的数据进行操作,对数据不进行转换,这些类都是InputStream和Out ...