机器学习——kNN(2)示例:改进约会网站的配对效果
=================================版权声明=================================
版权声明:原创文章 禁止转载
请通过右侧公告中的“联系邮箱(wlsandwho@foxmail.com)”联系我
勿用于学术性引用。
勿用于商业出版、商业印刷、商业引用以及其他商业用途。
本文不定期修正完善。
本文链接:http://www.cnblogs.com/wlsandwho/p/7587203.html
耻辱墙:http://www.cnblogs.com/wlsandwho/p/4206472.html
=======================================================================
这个示例实际上是对kNN的练习,区别是使用来自文件的数据。
=======================================================================
1从文件中读取数据并格式化为指定方式。
文件为file2matrix.py
from numpy import *
'''
def file2matrix1(filename):
f=open(filename)
arrlines=f.readlines()
rows=len(arrlines)
retmat=zeros((rows,3))
vctlabels=[]
index=0 for line in arrlines:
line=line.strip()
list=line.split("\t")
retmat[index,0:3]=list[0:3]
vctlabels.append(int(list[-1]))
index+=1 return retmat,vctlabels mat1,labels1=file2matrix1("datingTestSet2.txt")
print(mat1)
print(labels1)
'''
def file2matrix(filename):
with open(filename) as file:
line1=file.readline()
list1=line1.split()
cols=len(list1)
file.seek(0,0)
lines=file.readlines()
rows=len(lines) index=0
labels=[]
realcol=cols-1
retmat=zeros((rows,realcol))
for line in lines:
list=line.split()
retmat[index,:]=list[0:realcol]
labels.append(int(list[-1])) index+=1
return retmat,labels def file2matrix2(filename):
with open(filename) as file:
line1=file.readline()
list1=line1.split()
cols=len(list1)
file.seek(0,0)
lines=file.readlines()
rows=len(lines) index=0
labels=[]
realcol=cols-1
retmat=zeros((rows,realcol))
for line in lines:
list=line.split()
retmat[index,:]=list[0:realcol]
#labels.append(int(list[-1]))
if("largeDoses"==list[-1]):
labels.append(3)
elif("smallDoses"==list[-1]):
labels.append(2)
elif("didntLike"==list[-1]):
labels.append(1)
index+=1
return retmat,labels
测试一下
文件为test_file2matrix.py
from file2matrix import *
mat,labels=file2matrix("datingTestSet2.txt")
print(mat)
print(labels)
结果(红框是因为我用的虚拟机,不要在意这些细节)
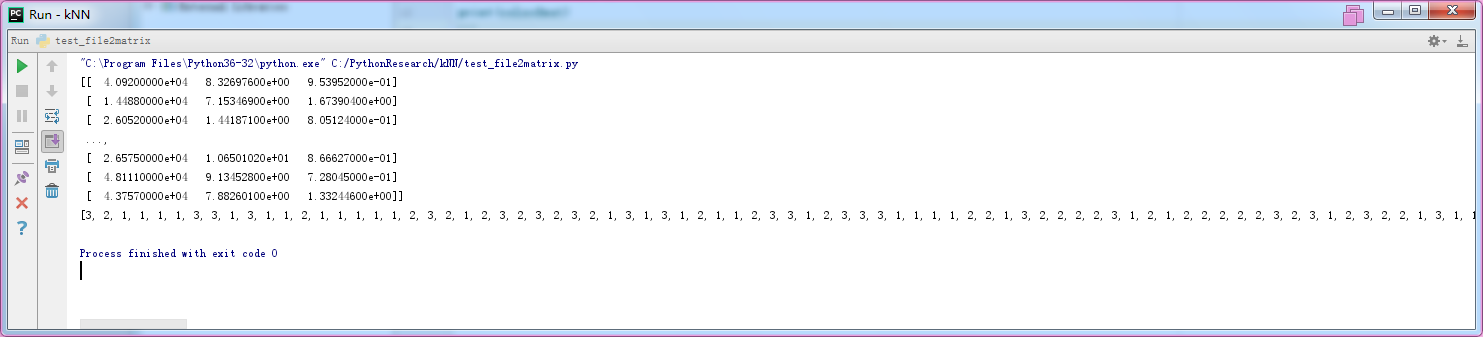
=======================================================================
2 做个图看看相关性/趋势。实际上这里并没有做数学上的讨论,就是画个图看看臆测一下。
文件是drawapicture1.py
import matplotlib
import matplotlib.pyplot as plt
import numpy
from file2matrix import *
mat,labels=file2matrix("datingTestSet2.txt")
nSizeofLabels=len(labels) fig=plt.figure()
ax=fig.add_subplot(111)
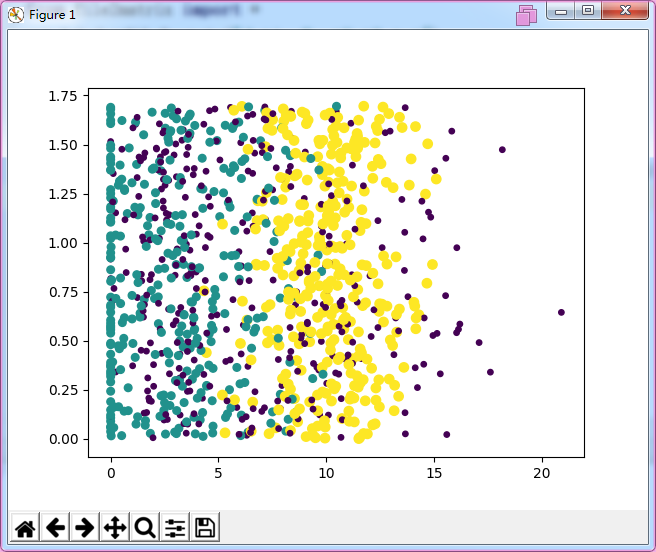
ax.scatter(mat[:,1],mat[:,2],s=15.0*array(labels),c=15.0*array(labels))
plt.show()
结果
文件是drawapicture2.py
import matplotlib
import matplotlib.pyplot as plt
import numpy
from file2matrix import * mat,labels=file2matrix("datingTestSet2.txt")
nSizeofLabels=len(labels)
mat1x=[]
mat2x=[]
mat3x=[]
mat1y=[]
mat2y=[]
mat3y=[]
for i in range(nSizeofLabels):
if labels[i]==1:
mat1x.append(mat[i][0])
mat1y.append(mat[i][1])
elif labels[i]==2:
mat2x.append(mat[i][0])
mat2y.append(mat[i][1])
elif labels[i]==3:
mat3x.append(mat[i][0])
mat3y.append(mat[i][1]) fig=plt.figure()
ax=fig.add_subplot(111)
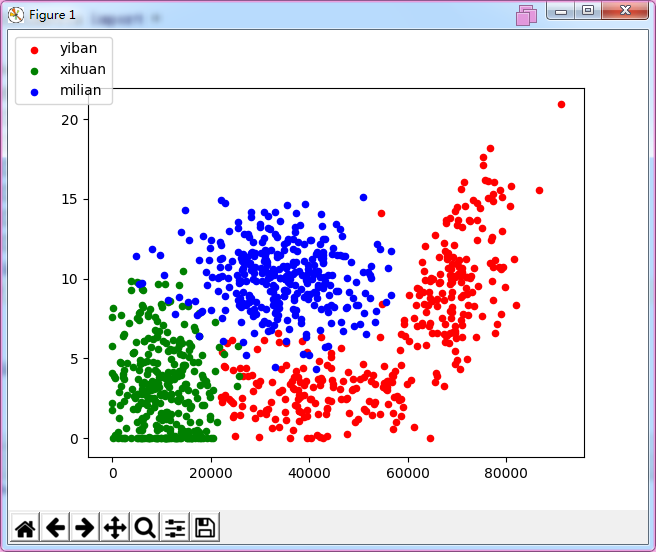
lg1=ax.scatter(mat1x,mat1y,s=20,c='red')
lg2=ax.scatter(mat2x,mat2y,s=20,c='green')
lg3=ax.scatter(mat3x,mat3y,s=20,c='blue')
fig.legend((lg1,lg2,lg3),('yiban','xihuan','milian'),"upper left")
plt.show()
结果是
=======================================================================
3 由于不同意义的数据的取值范围很大,所以需要归一化。
文件是matrixnormalization.py
from numpy import * def autonorm(mat):
minv=mat.min(0)
maxv=mat.max(0)
diff=maxv-minv
rows=mat.shape[0]
normmat=zeros(shape(mat))
normmat=mat-tile(minv,(rows,1))
normmat=normmat/tile(diff,(rows,1))
return normmat,minv,maxv,diff
测试归一化
文件是test_matrixnormalization.py
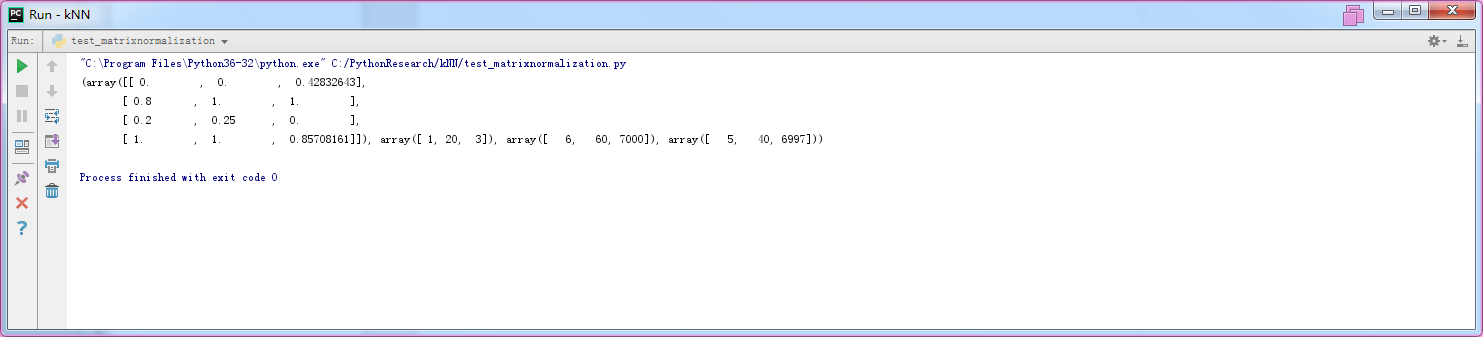
from matrixnormalization import * mat=array([[1,20,3000],[5,60,7000],[2,30,3],[6,60,6000]])
normmat=autonorm(mat)
print(normmat)
结果(不知道为何,跟书上的结果不太一样。)
=======================================================================
4测试一下这个分类器的效果
文件名test_dating.py
from file2matrix import *
from matrixnormalization import *
from kNN import * def testdating():
ratio=0.1
countforerr=0 mat,lab=file2matrix2("datingTestSet.txt") normmat,minv,maxv,diff=autonorm(mat) allrows=normmat.shape[0]
rowsforTest=int(allrows*ratio) for i in range(rowsforTest):
res=classify_kNN(normmat[i,:],normmat[rowsforTest:allrows,:],lab[rowsforTest:allrows],3)
print('the result is',res,'the real is',lab[i])
if (res!=lab[i]):
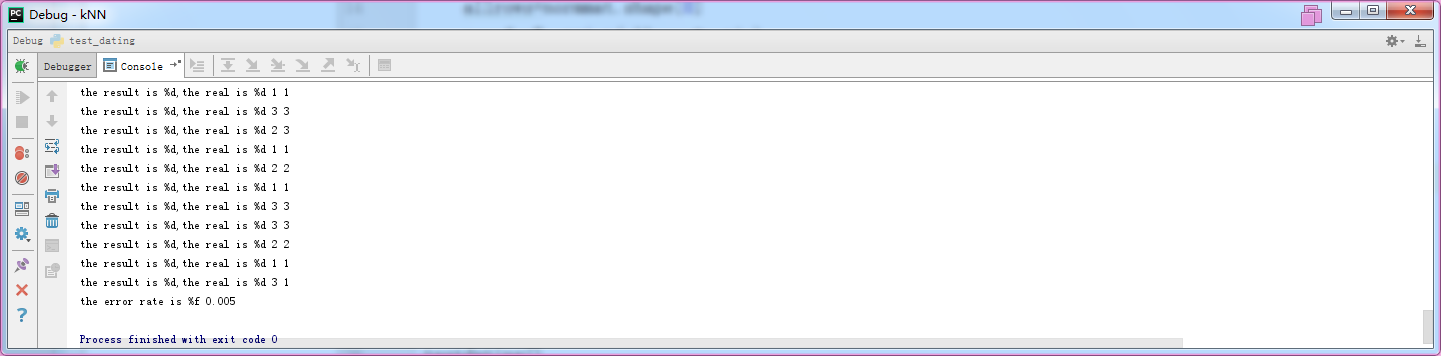
countforerr+=1.0 print("the error rate is", (countforerr/float(allrows))) testdating()
结果
=======================================================================
5支持手工输入
文件名test_dating2.py
from file2matrix import *
from matrixnormalization import *
from kNN import * def testdating():
ratio=0.1
countforerr=0
reslist=["not at all","a little","very well"]
mat,lab=file2matrix2("datingTestSet.txt") normmat,minv,maxv,diff=autonorm(mat) allrows=normmat.shape[0]
rowsforTest=int(allrows*ratio) percenttats=float(input("percentage of time spent playing video games?"))
flymiles=float(input("frequent filer miles earned per year?"))
icecream=float(input("liters of ice cream consumed per year?"))
desarr=array([flymiles,percenttats,icecream])
normdesarr=(desarr-minv)/diff res=classify_kNN(normdesarr,normmat[rowsforTest:allrows,:],lab[rowsforTest:allrows],3)
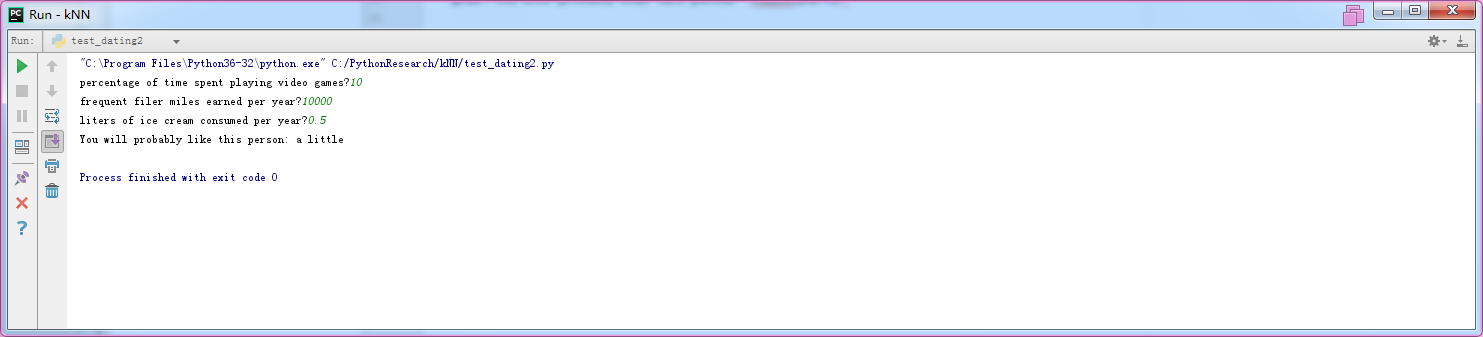
print("You will probably like this person:",reslist[res-1]) testdating()
结果
=======================================================================
这一节更像是用一个小算法领着学习python。
机器学习——kNN(2)示例:改进约会网站的配对效果的更多相关文章
- KNN算法项目实战——改进约会网站的配对效果
KNN项目实战——改进约会网站的配对效果 1.项目背景: 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可 ...
- 机器学习实战1-2.1 KNN改进约会网站的配对效果 datingTestSet2.txt 下载方法
今天读<机器学习实战>读到了使用k-临近算法改进约会网站的配对效果,道理我都懂,但是看到代码里面的数据样本集 datingTestSet2.txt 有点懵,这个样本集在哪里,只给了我一个文 ...
- kNN分类算法实例1:用kNN改进约会网站的配对效果
目录 实战内容 用sklearn自带库实现kNN算法分类 将内含非数值型的txt文件转化为csv文件 用sns.lmplot绘图反映几个特征之间的关系 参考资料 @ 实战内容 海伦女士一直使用在线约会 ...
- k-近邻(KNN)算法改进约会网站的配对效果[Python]
使用Python实现k-近邻算法的一般流程为: 1.收集数据:提供文本文件 2.准备数据:使用Python解析文本文件,预处理 3.分析数据:可视化处理 4.训练算法:此步骤不适用与k——近邻算法 5 ...
- 《机器学习实战》之k-近邻算法(改进约会网站的配对效果)
示例背景: 我的朋友海伦一直使用在线约会网站寻找合适自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现曾交往过三种类型的人: (1)不喜欢的人: (2)魅力一般 ...
- 机器学习读书笔记(二)使用k-近邻算法改进约会网站的配对效果
一.背景 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可以进行如下分类 不喜欢的人 魅力一般的人 极具魅 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 【Machine Learning in Action --2】K-近邻算法改进约会网站的配对效果
摘自:<机器学习实战>,用python编写的(需要matplotlib和numpy库) 海伦一直使用在线约会网站寻找合适自己的约会对象.尽管约会网站会推荐不同的人选,但她没有从中找到喜欢的 ...
- 使用k-近邻算法改进约会网站的配对效果
---恢复内容开始--- < Machine Learning 机器学习实战>的确是一本学习python,掌握数据相关技能的,不可多得的好书!! 最近邻算法源码如下,给有需要的入门者学习, ...
随机推荐
- Vue 组件(component)之 精美的日历
公司的要求,需要开发一个精美的日历组件(IOS , 安卓, PC 的IE9+都能运行),写完后想把它分享出来,希望大家批评(). 先来个截图 代码已经分享到 https://github.com/zh ...
- 接口返回数据Json格式处理
有这样一个页面 , 用来显示用户的账户记录数据,并且需要显示每个月的 收入 支出合计 ,在分页的时候涉及到一些问题,需要对返回的Json格式做处理,处理起来比较麻烦,后端返回的Json数据格式形式如下 ...
- angular4.0项目文件解读
这篇文章我觉得是很有用的,便于我们对ng项目的理解,同时在配置项目时,也能够很快的定位到相应文件. 摘录的别人的文章,首先感谢那个路人兄弟,下面就开始学习吧. File 文件 Purpose 用途 e ...
- chrome调试工具高级不完整使用指南(优化篇)
上一篇文章我们说了chrome调试工具的一些比较基础功能的用法,接下来我们要在这一篇文章中说一说,其他一些chrome调试工具的使用方法 2.1.5 Network模块 在netWork模块中,大致上 ...
- OTCBTC上线币币交易
我们在这里很高兴的宣布,OTCBTC 的币币交易区,即将在 2018/01/11 于 08:00 上线. 这个币币交易区,将会跟所有现有的交易所很不一样,我们将开放用户自主上币,且所有品种不收任何上架 ...
- 用mint ui去实现滚动选择日期并可以关闭拾取器
转发要备注出处哈,么么哒 注释的那些部分都是我在尝试的时候写得,留给自己看得,删除不影响效果哈,希望对你们有帮助,比较忙可能写得很粗糙,不好意思,有空再改了 实例一: <template&g ...
- 深入学习Java8 Lambda (default method, lambda, function reference, java.util.function 包)
Java 8 Lambda .MethodReference.function包 多年前,学校讲述C#时,就已经知道有Lambda,也惊喜于它的方便,将函数式编程方式和面向对象式编程基于一身.此外在使 ...
- hive问题: For direct MetaStore DB connections, we don't support retries at the client level
已经配置好hive,mysql作为元数据的数据库.在hive中执行drop语句出错: drop table mytest; 错误提示如下: FAILED: SemanticException Unab ...
- LeetCode第[4]题(Java):Median of Two Sorted Arrays 标签:Array
题目难度:hard There are two sorted arrays nums1 and nums2 of size m and n respectively. Find the median ...
- C#学习笔记-装饰模式
题目:给顾客打扮,但是需要满足正常的穿衣风格,例如先穿了衬衣再打领带,最后在穿鞋子,这种基本要求. 分析: 现在将具体的衣服裤子和鞋子都分别写在不同的类里面,这样方便以后添加新的衣服,这些全部都属于服 ...