windows11 安装CUDA Toolkit,Python,Anaconda,PyTorch并使用DeepSeek 多模态模型 Janus-Pro识别和生成图片
一、概述
因为公司网络做了严格限制,必须使用账号登录,才能上网。必须是指定的ip地址和MAC地址设备才可以上网。
windows11开启热点,安装第三方虚拟机软件,开启WSL2虚拟机都是被禁止的,否则账号会被封锁,无法上网。
挺无奈的,那么就只能使用windows 11系统来安装CUDA Toolkit,Anaconda,PyTorch这些组件,使用DeepSeek 多模态模型 Janus-Pro,识别和生成图片了。
二、安装CUDA Toolkit
安装NVIDIA App
NVIDIA App 是 PC 游戏玩家和创作者的必备辅助工具。可以使你的 PC 及时升级到最新的 NVIDIA 驱动程序和技术。在全新的统一 GPU 控制中心内优化游戏和应用,通过游戏内悬浮窗提供的强大录像工具捕捉精彩时刻,并可以轻松发现最新的 NVIDIA 工具和软件。
官方地址:https://www.nvidia.cn/software/nvidia-app/
直接下载安装,他会自动识别你的英伟达显卡型号,并安装最新的驱动。
安装过程很简单,直接下一步,下一步安装即可。
打开NVIDIA App,选择驱动类型GeForce Game Ready,专门为游戏设计的驱动,安装最新版本。

安装CUDA Toolkit
CUDA Toolkit 是NVIDIA 提供的一套开发工具,它包含了用于开发CUDA 应用程序所需的各种工具,如编译器、调试器和库。 因此,CUDA 和CUDA Toolkit 是有关系的,CUDA 是并行计算平台和编程模型,而CUDA Toolkit 是一套开发工具。
查看显卡算力
https://developer.nvidia.com/cuda-gpus
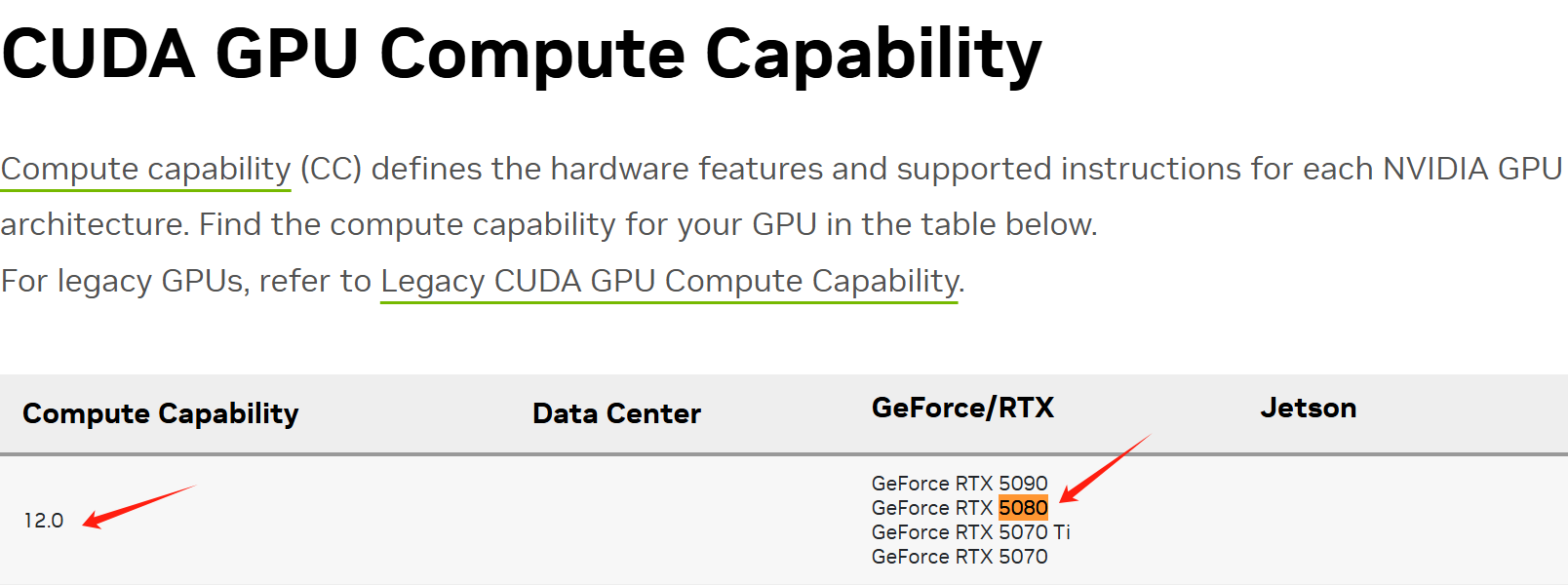
我的显卡是5080,对应的显卡算力是12.0
算力对应的cuda版本
https://docs.nvidia.com/datacenter/tesla/drivers/index.html#cuda-arch-matrix
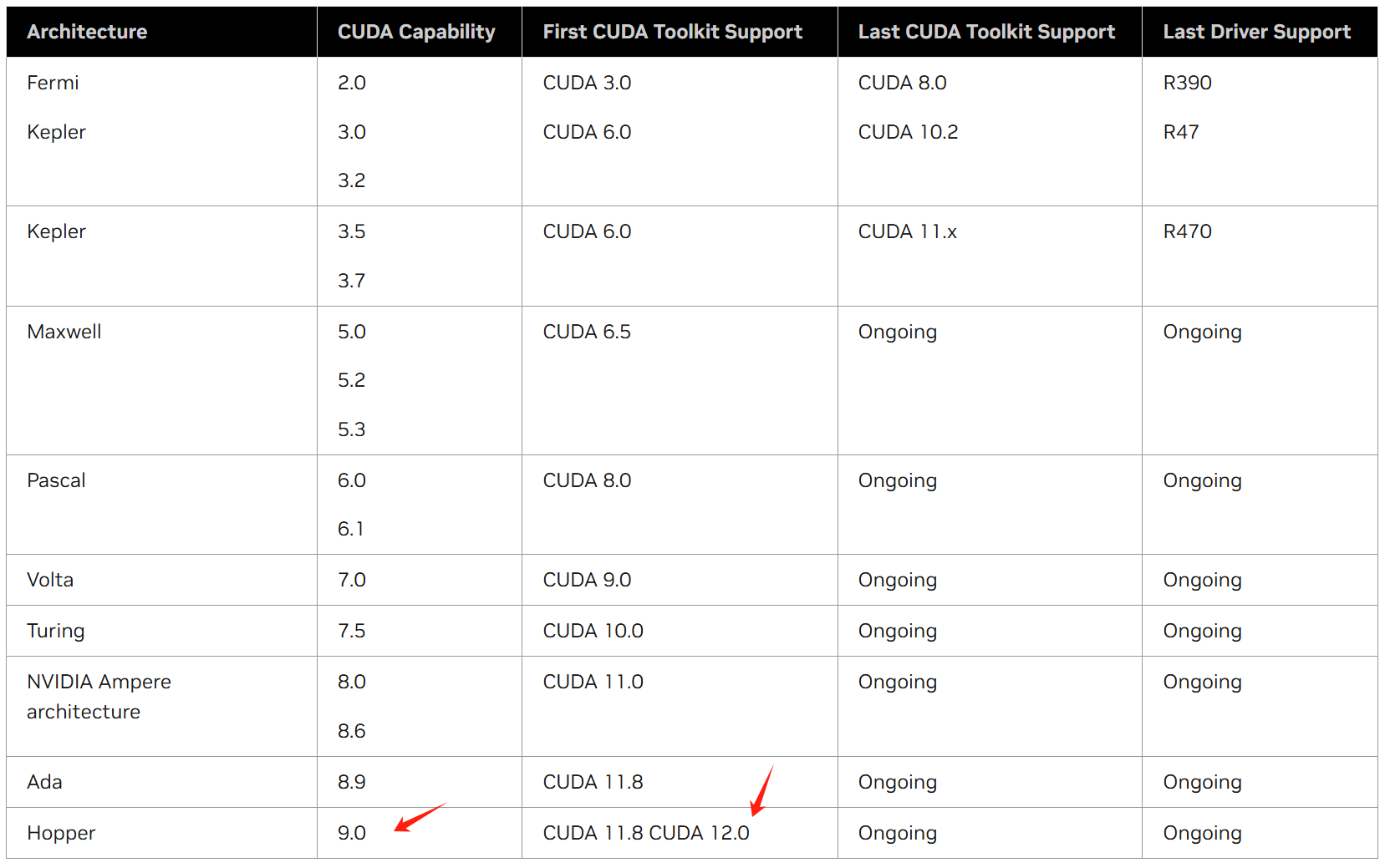
我的显卡算力是12,大于9,所以可以安装CUDA 11.8 CUDA 12.0,都可以。
注意:只能高,不能低。
打开pytorch网页
https://pytorch.org/get-started/locally/
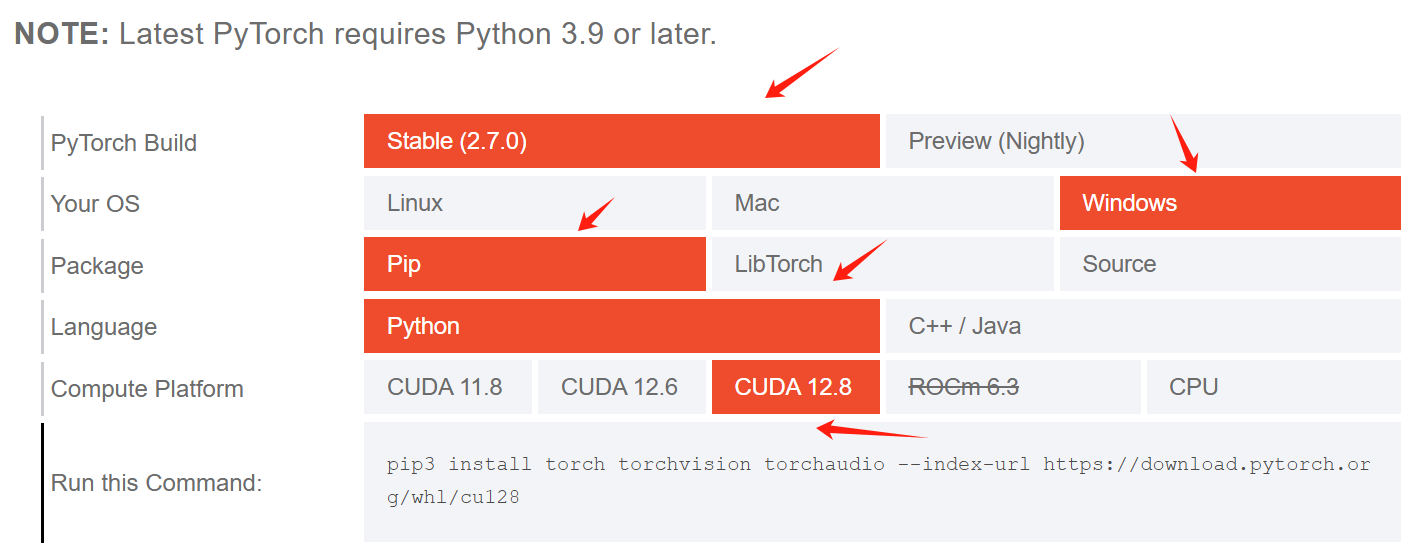
可以看到pytorch目前支持CUDA最高的版本是12.8,那么接下来安装CUDA Toolkit,不能高于12.8
打开官网下载地址:
https://developer.nvidia.com/cuda-toolkit-archive

虽然目前最新版本是12.9.0,但是我不能安装12.9.0,因为pytorch目前支持CUDA最高的版本是12.8
所以我只能安装12.8.1,多一个小数点,问题不大。因为也是12.8系列的。
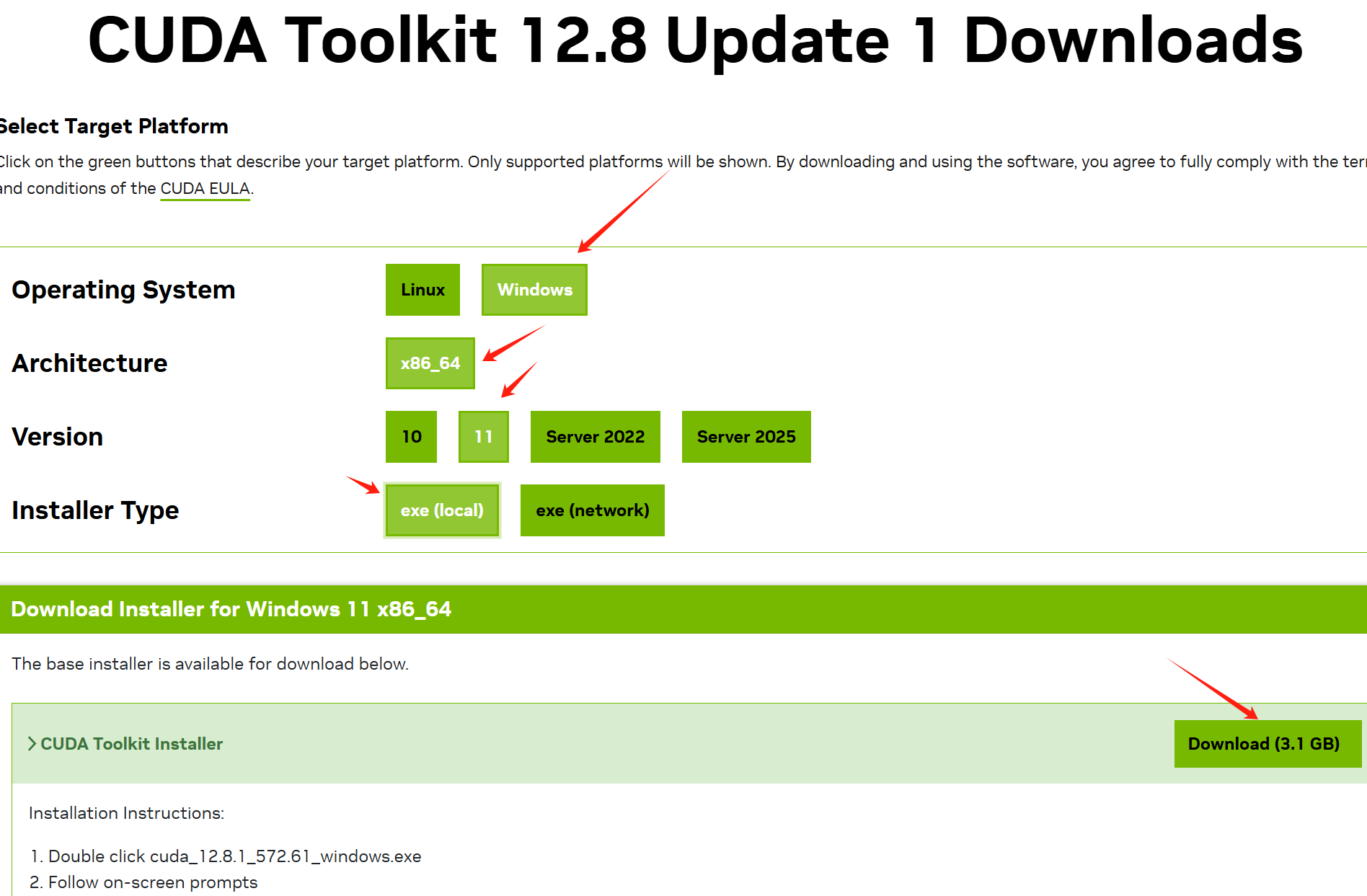
注意:这里必须要根据你的实际情况,进行严格选择
我这里选择的是windows 11版本的
文件比较大,可以开启迅雷下载
下载完成后,点击exe程序安装
临时路径,默认即可,安装完成后,会自动删除的。
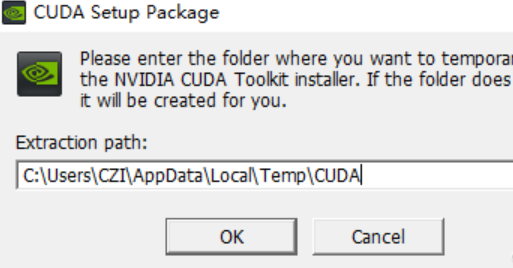
之后,就是下一步下一步安装即可。
三、安装python
官方网址:https://www.python.org/downloads/
下载最新版本
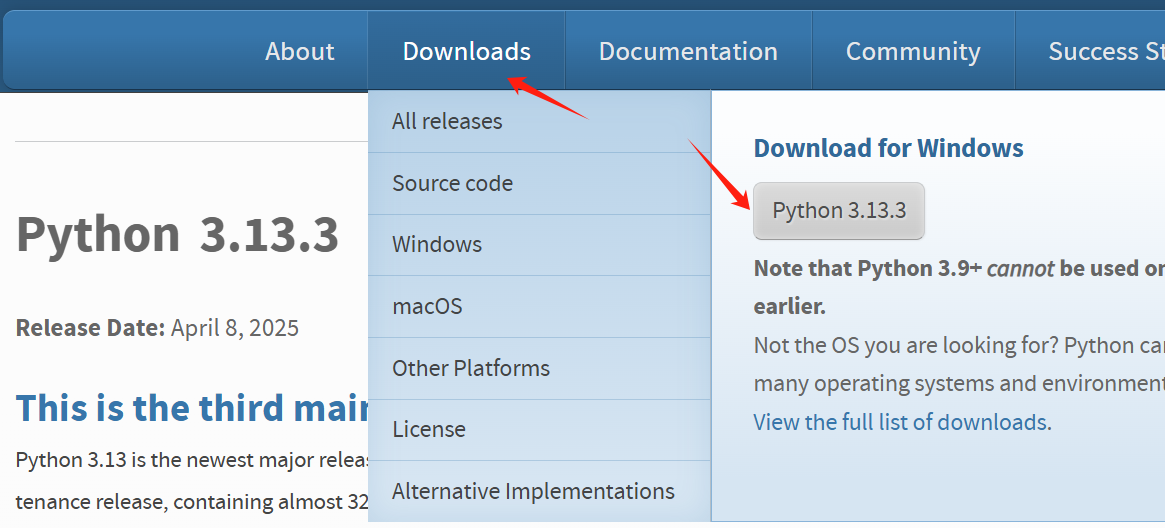
下载完成后,点击exe文件安装
注意,必须勾选【Add Python 3.10 to PATH】
然后点击【Customize installation】自定义安装程序
进入到可选功能【Optional Features】界面后,全部勾选,下一步
然后
勾选【Associate files with Python (requires the py launcher)】,默认python运行.py文件
勾选【Add Python to environment variables】,添加环境变量
修改安装的文件路径,尽量安装在磁盘根目录。例如:D:\python3.13
点击【install】按钮执行安装
安装完成后,打开cmd窗口,输入Python,效果如下:

确保版本正确
四、安装Anaconda
Anaconda是一个开源的Python发行版本,专注于数据科学、机器学习和大数据处理,集成了conda包管理器、Python解释器及180多个预装科学计算库(如NumPy、Pandas),提供跨平台的环境隔离与管理功能。
官方地址:https://www.anaconda.com/download/success
下载windows版本

下载完成后,点击exe程序,下一步,下一步安装即可。
打开windows11开启菜单,搜索ana,点击Anaconda Prompt
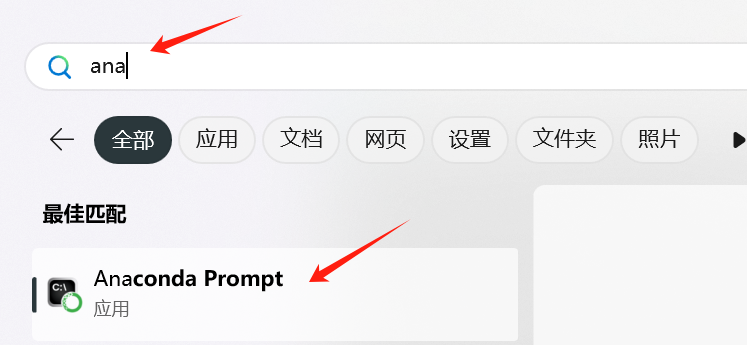
输入python,效果如下:
注意:显示的python版本和单独安装的python版本,有些差异是正常的。因为Anaconda还不支持最新python版本。
五、安装PyTorch
PyTorch 是一个开源的机器学习库,广泛应用于计算机视觉、自然语言处理等领域。
打开pytorch网页
https://pytorch.org/get-started/locally/
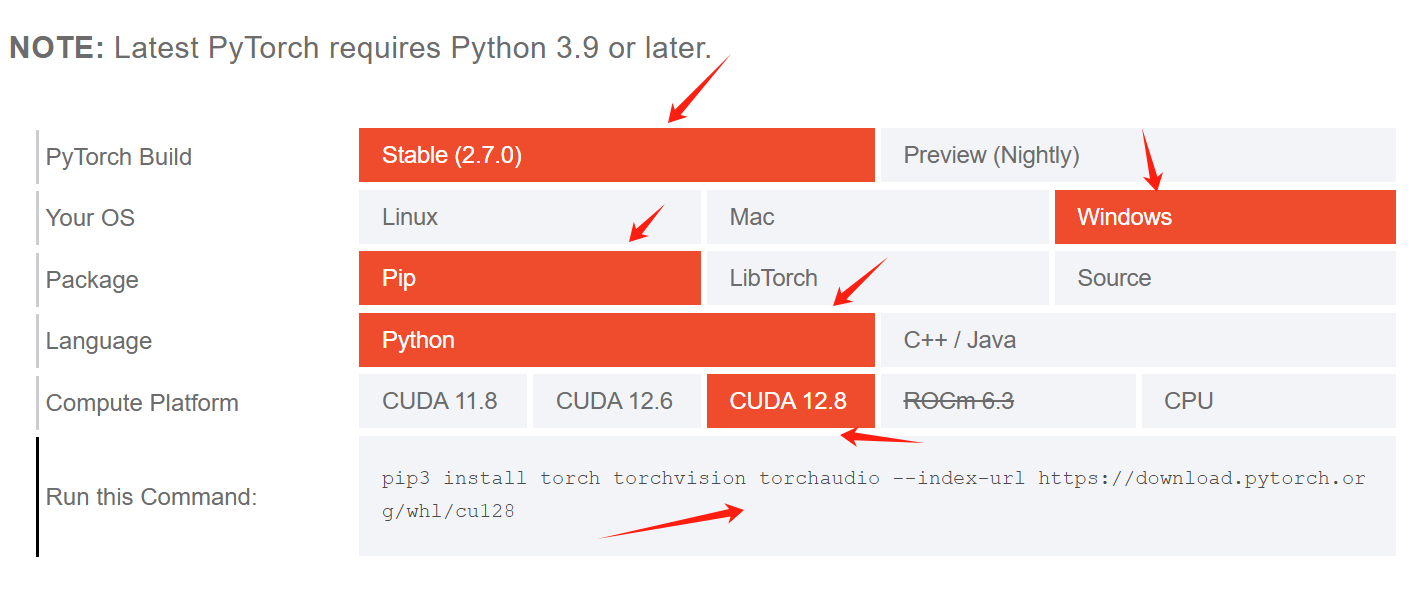
说明:
pytorch安装,python版本不能低于3.9
pytorch build,这里选择最新版本
your os,选择Linux
Package,选择pip安装
Language,开发语言,选择Python
compute platform,这里选择CUDA 12.8,因为在上面的步骤中,我安装的版本就是CUDA Toolkit 12.8
run this command,这里就会显示完整的安装命令,直接复制即可
创建虚拟环境
将环境创建在指定路径下
注意:目录D:\file\conda\envs,需要先手动创建一下,这里用来存放所有的虚拟环境
conda create --prefix D:\file\conda\envs\my_unsloth_env python=3.13.2
输入y
Continue creating environment (y/[n])? y
激活虚拟环境
conda activate D:\file\conda\envs\my_unsloth_env
安装pytorch
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
在python中确认一下torch是否安装成功
(my_unsloth_env) C:\Users\xiao>python
Python 3.13.2 | packaged by Anaconda, Inc. | (main, Feb 6 2025, 18:49:14) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> print(torch.cuda.device_count())
1
>>> print(torch.cuda.is_available())
True
>>> print(torch.__version__)
2.7.0+cu128
>>> print(torch.version.cuda)
12.8
>>> exit()
注意:确保torch.version.cuda输出的版本和CUDA Toolkit版本一致,就说明cuda和troch版本是匹配的。
六、DeepSeek 多模态模型 Janus-Pro
Janus-Pro是DeepSeek最新开源的多模态模型,是一种新颖的自回归框架,统一了多模态理解和生成。通过将视觉编码解耦为独立的路径,同时仍然使用单一的、统一的变压器架构进行处理,该框架解决了先前方法的局限性。这种解耦不仅缓解了视觉编码器在理解和生成中的角色冲突,还增强了框架的灵活性。Janus-Pro 超过了以前的统一模型,并且匹配或超过了特定任务模型的性能。
github链接:https://github.com/deepseek-ai/Janus
安装依赖组件
安装依赖包,注意:这里要手动安装pytorch,指定版本。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
安装其他依赖组件
pip3 install transformers attrdict einops timm
下载模型
可以用modelscope下载,安装modelscope,命令如下:
pip install modelscope modelscope download --model deepseek-ai/Janus-Pro-7B
效果如下:
(my_unsloth_env) C:\Users\xiao> modelscope download --model deepseek-ai/Janus-Pro-7B
Downloading Model from https://www.modelscope.cn to directory: C:\Users\xiao\.cache\modelscope\hub\models\deepseek-ai\Janus-Pro-7B
Downloading [config.json]: 100%|███████████████████████████████████████████████████| 1.42k/1.42k [00:00<00:00, 5.29kB/s]
Downloading [configuration.json]: 100%|████████████████████████████████████████████████| 68.0/68.0 [00:00<00:00, 221B/s]
Downloading [README.md]: 100%|█████████████████████████████████████████████████████| 2.49k/2.49k [00:00<00:00, 7.20kB/s]
Downloading [processor_config.json]: 100%|███████████████████████████████████████████████| 210/210 [00:00<00:00, 590B/s]
Downloading [janus_pro_teaser1.png]: 100%|██████████████████████████████████████████| 95.7k/95.7k [00:00<00:00, 267kB/s]
Downloading [preprocessor_config.json]: 100%|████████████████████████████████████████████| 346/346 [00:00<00:00, 867B/s]
Downloading [janus_pro_teaser2.png]: 100%|███████████████████████████████████████████| 518k/518k [00:00<00:00, 1.18MB/s]
Downloading [special_tokens_map.json]: 100%|███████████████████████████████████████████| 344/344 [00:00<00:00, 1.50kB/s]
Downloading [tokenizer_config.json]: 100%|███████████████████████████████████████████████| 285/285 [00:00<00:00, 926B/s]
Downloading [pytorch_model.bin]: 0%|▏ | 16.0M/3.89G [00:00<03:55, 17.7MB/s]
Downloading [tokenizer.json]: 100%|████████████████████████████████████████████████| 4.50M/4.50M [00:00<00:00, 6.55MB/s]
Processing 11 items: 91%|█████████████████████████████████████████████████████▋ | 10.0/11.0 [00:19<00:00, 14.1it/s]
Downloading [pytorch_model.bin]: 100%|█████████████████████████████████████████████| 3.89G/3.89G [09:18<00:00, 7.48MB/s]
Processing 11 items: 100%|███████████████████████████████████████████████████████████| 11.0/11.0 [09:24<00:00, 51.3s/it]
可以看到下载目录为C:\Users\xiao\.cache\modelscope\hub\models\deepseek-ai\Janus-Pro-7B
在D盘新建目录D:\file\modelscope\model,专门用来存放模型的
将文件夹C:\Users\xiao\.cache\modelscope\hub\models\deepseek-ai,移动到目录D:\file\modelscope\model
测试图片理解
打开github链接:https://github.com/deepseek-ai/Janus
下载zip文件
新建目录D:\file\vllm,用来测试大模型的
将文件Janus-main.zip复制到此目录,并解压,得到目录Janus-main。
进入文件夹Janus-main
将图片aa.jpeg,下载链接:https://pics6.baidu.com/feed/09fa513d269759ee74c8d049640fcc1b6f22df9e.jpeg
放到文件夹Janus-main
在文件夹Janus-main,创建image_understanding.py文件
import torch
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
from janus.utils.io import load_pil_images model_path = r"D:\file\modelscope\model\deepseek-ai\Janus-Pro-7B" image='aa.jpeg'
question='请说明一下这张图片'
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval() conversation = [
{
"role": "<|User|>",
"content": f"<image_placeholder>\n{question}",
"images": [image],
},
{"role": "<|Assistant|>", "content": ""},
] # load images and prepare for inputs
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device) # # run image encoder to get the image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs) # # run the model to get the response
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True,
) answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)
注意:根据实际情况,修改 model_path,image这2个参数即可,其他的不需要改动。
运行代码,效果如下:
(my_unsloth_env) D:\file\vllm\Janus-main>python image_understanding.py
Python version is above 3.10, patching the collections module.
D:\file\conda\envs\my_unsloth_env\Lib\site-packages\transformers\models\auto\image_processing_auto.py:604: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead
warnings.warn(
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████| 2/2 [00:21<00:00, 10.73s/it]
You are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language. <|User|>: <image_placeholder>
请说明一下这张图片 <|Assistant|>: 这张图片展示了一位身穿传统服饰的女性,她正坐在户外,双手合十,闭着眼睛,似乎在进行冥想或祈祷。背景是绿色的树木和植物,阳光透过树叶洒下来,营造出一种宁静、祥和的氛围。她的服装以白色和粉色为主,带有精致的刺绣和装饰,显得非常优雅。整体画面给人一种平和、放松的感觉。
描述还是比较准确的
测试图片生成
在文件夹Janus-main,新建image_generation.py脚本,代码如下:
import os
import torch
import numpy as np
from PIL import Image
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor model_path = r"D:\file\modelscope\model\deepseek-ai\Janus-Pro-7B"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval() conversation = [
{"role": "<|User|>", "content": "超写实8K渲染,一位具有东方古典美的中国女性,瓜子脸,西昌的眉毛如弯弯的月牙,双眼明亮而深邃,犹如夜空中闪烁的星星。高挺的鼻梁,樱桃小嘴微微上扬,透露出一丝诱人的微笑。她的头发如黑色的瀑布般垂直落在减胖两侧,微风轻轻浮动发色。肌肤白皙如雪,在阳光下泛着微微的光泽。她身着乙烯白色的透薄如纱的连衣裙,裙摆在海风中轻轻飘动。"},
{"role": "<|Assistant|>", "content": ""},
] sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
conversations=conversation,
sft_format=vl_chat_processor.sft_format,
system_prompt=""
)
prompt = sft_format + vl_chat_processor.image_start_tag @torch.inference_mode()
def generate(
mmgpt: MultiModalityCausalLM,
vl_chat_processor: VLChatProcessor,
prompt: str,
temperature: float = 1,
parallel_size: int = 1, # 减小 parallel_size
cfg_weight: float = 5,
image_token_num_per_image: int = 576,
img_size: int = 384,
patch_size: int = 16,
):
input_ids = vl_chat_processor.tokenizer.encode(prompt)
input_ids = torch.LongTensor(input_ids) tokens = torch.zeros((parallel_size * 2, len(input_ids)), dtype=torch.int).cuda()
for i in range(parallel_size * 2):
tokens[i, :] = input_ids
if i % 2 != 0:
tokens[i, 1:-1] = vl_chat_processor.pad_id inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens) generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda() for i in range(image_token_num_per_image):
outputs = mmgpt.language_model.model(inputs_embeds=inputs_embeds, use_cache=True,
past_key_values=outputs.past_key_values if i != 0 else None)
hidden_states = outputs.last_hidden_state logits = mmgpt.gen_head(hidden_states[:, -1, :])
logit_cond = logits[0::2, :]
logit_uncond = logits[1::2, :] logits = logit_uncond + cfg_weight * (logit_cond - logit_uncond)
probs = torch.softmax(logits / temperature, dim=-1) next_token = torch.multinomial(probs, num_samples=1)
generated_tokens[:, i] = next_token.squeeze(dim=-1)
next_token = torch.cat([next_token.unsqueeze(dim=1),
next_token.unsqueeze(dim=1)], dim=1).view(-1)
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
inputs_embeds = img_embeds.unsqueeze(dim=1)
# 添加显存清理
del logits, logit_cond, logit_uncond, probs
torch.cuda.empty_cache() dec = mmgpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int),
shape=[parallel_size, 8, img_size // patch_size, img_size // patch_size])
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1) dec = np.clip((dec + 1) / 2 * 255, 0, 255) visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
visual_img[:, :, :] = dec os.makedirs('generated_samples', exist_ok=True)
for i in range(parallel_size):
save_path = os.path.join('generated_samples', f"img_{i}.jpg")
img = Image.fromarray(visual_img[i])
img.save(save_path) generate(
vl_gpt,
vl_chat_processor,
prompt,
)
注意:根据实际情况,修改model_path,conversation,parallel_size这3个参数即可。
提示词是可以写中文的,不一定非要是英文。
代码在默认的基础上做了优化,否则运行会导致英伟达5080显卡直接卡死。
运行代码,效果如下:
(my_unsloth_env) D:\file\vllm\Janus-main>python image_generation.py
Python version is above 3.10, patching the collections module.
D:\file\conda\envs\my_unsloth_env\Lib\site-packages\transformers\models\auto\image_processing_auto.py:604: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead
warnings.warn(
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████| 2/2 [00:15<00:00, 7.68s/it]
注意观察一下GPU使用情况,这里好像并不高啊,基本上在20%左右。
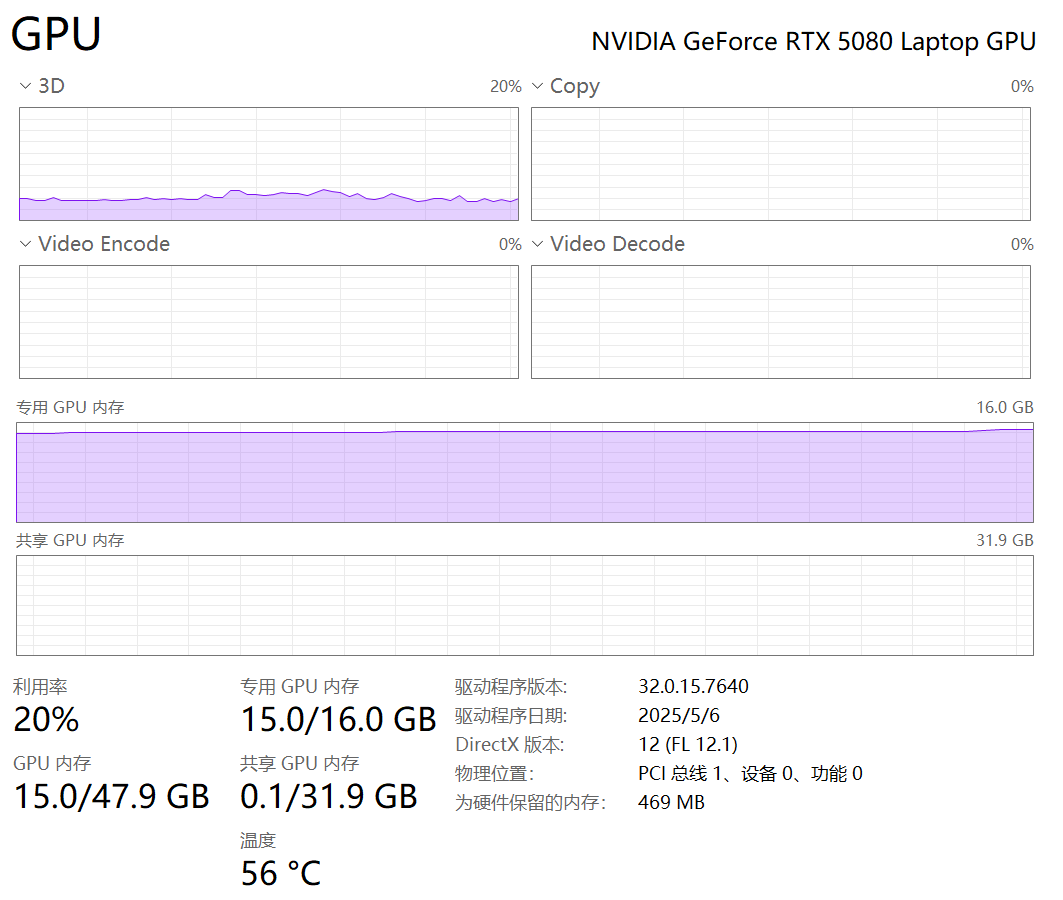
windows11用GPU很低,用WSL2利用GPU反而会很高?
WSL2 通常依赖于 Windows 的驱动程序,但可能会有兼容性或性能问题。只能这么解释了
等待1分钟左右,就会生成一张图片。
进入目录D:\file\vllm\Janus-main\generated_samples,这里会出现一张图片
打开图片,效果如下:

效果还算可以,距离真正的8k画质,还是有点差距的。
注意提示词,尽量丰富一点,生成的图片,才符合要求。
如果不会写提示词,可以让deepseek帮你写一段提示词。
windows11 安装CUDA Toolkit,Python,Anaconda,PyTorch并使用DeepSeek 多模态模型 Janus-Pro识别和生成图片的更多相关文章
- (原)Ubuntu16中安装cuda toolkit
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/5655957.html 参考网址: https://devtalk.nvidia.com/default ...
- windows10环境下安装深度学习环境anaconda+pytorch+CUDA+cuDDN
步骤零:安装anaconda.opencv.pytorch(这些不详细说明).复制运行代码,如果没有报错,说明已经可以了.不过大概率不行,我的会报错提示AssertionError: Torch no ...
- OpenSuse13.2安装CUDA Toolkit 7.5
此次安装过程有点曲折,不过最后还是能成功安装,由于没细细看官方的安装文档,导致花了很多时间安装,希望此文能让想装CUDA的同学少走点弯路 1.NVIDIA Driver是否要装 刚开始要装CUDA时, ...
- [Python[Anaconda & PyTorch]] -- 使用conda 安装 Torch 出现错误 --Windows
... (⊙o⊙)… ... 当时具体的错误我没有截图, 用这个命令时 , conda 会报无法在源中找到PyTorch, 还是什么的错误 有很大的一个可能是, 安装的Anaconda 是32 位的, ...
- 2018最新win10 安装tensorflow1.4(GPU/CPU)+cuda8.0+cudnn8.0-v6 + keras 安装CUDA失败 导入tensorflow失败报错问题解决
原文作者:aircraft 原文链接:https://www.cnblogs.com/DOMLX/p/9747019.html 基本开发环境搭建 1. Microsoft Windows 版本 关于W ...
- ubuntu常用命令及操作,包括安装CUDA
chmod Document 这里Document是一个文件夹,文件夹中还有好多子文件,可以发现执行了这条指令以后,其子文件夹的权限并没有改变. 要想改变其子文件夹的权限,应该执行 Document/ ...
- win7 64位下自行编译OpenCV2.4.10+CUDA toolkit 5.5的整个过程以及需要注意的问题(opencv+cuda并行计算元素的使用)
首先说明的是,这个帖子是成功的编译了dll,但是这个dll使用的时候还是很容易出现各种问题的. 发现错误可能是由于系统安装了太多版本的opencv,环境变量的设置混乱,造成dll版本加载 ...
- Windows10 安装 CUDA + cuDNN + pyTorch
2020/5/29 在 windows10 上面安装 CUDA 和 cuDNN 0.简单了解一下 CUDA 和 cuDNN 1)什么是 CUDA CUDA(ComputeUnified Device ...
- 从零开始配置深度学习环境:CUDA+Anaconda+Pytorch+TensorFlow
本文适用于电脑有GPU(显卡)的同学,没有的话直接安装cpu版是简单的.CUDA是系统调用GPU所必须的,所以教程从安装CUDA开始. CUDA安装 CUDA是加速深度学习计算的工具,诞生于NVIDI ...
- TensorFlow-Gpu环境搭建——Win10+ Python+Anaconda+cuda
参考:http://blog.csdn.net/sb19931201/article/details/53648615 https://segmentfault.com/a/1190000009803 ...
随机推荐
- Android应用借助LinearLayout实现垂直水平居中布局
首先说的是LinearLayout布局下的居中一般是这样的: (注意:android:layout_width="fill_parent" android:layout_heigh ...
- nginx 强制https
nginx 强制https 通常有如下两种方法强制https推荐第二种,第二种更高效1.使用nginx的rewrite方法 server { listen 80; server_name xxx. ...
- 万字解析Golang的map实现原理
0.引言 相信大家对Map这个数据结构都不陌生,像C++的map.Java的HashMap.各个语言的底层实现各有不同,在本篇博客中,我将分享个人对Go的map实现的理解,以及深入源码进行分析,相信耐 ...
- 循环(Java篇)
令人头痛的循环(:´д`)ゞ 我们在学习循环的时候可能会有点懵,什么是循环?它可以干嘛?我这里为什么要用循环来写这段代码?等问题. 首先我们来讲一下循环可以干嘛 循环是什么?o(′益`)o 在 Jav ...
- Golang 入门 : 常量
常量 相对于变量而言,常量是在程序使用过程中,不会改变的数据.有些地方你需要将定义好的常量重复使用,代码中你不允许它的值改变.例如 圆周率 在程序执行过程中不会改变. 常量的声明 const Pi f ...
- linux php重启
1.停止命令 你可以先查看自己的php进程有没有启动 ps -ef | grep php [root@iZ6we4yxap93y2r0clg3g8Z ~]# ps -ef | grep php roo ...
- 业余无线电爱好者,自制天线比较容易上手天线“莫克森天线”Moxon
本文仅作为笔记分享,如有疑问可以留言交流. 莫克森天线尺寸计算软件:Moxon rectangle 高手门做的成品,参考资料: 英文文献资料:
- EntityFramework GroupJoin
总而言之, GroupJoin 是先 Join 后 Group, 对应的 SQL 也是先 Join, 然后通过内置 LINQ 操作分组. 参考文档 GroupJoin 方法 Reimplementin ...
- Docker 实用镜像
实用镜像 nginx-proxy nginx-proxy sets up a container running nginx and docker-gen. ...
- 如何使用 OpenAI Agents SDK 构建 MCP
1.概述 OpenAI Agents SDK 现已支持 MCP(模型上下文协议),这是 AI 互操作性的重大变革.这使开发人员能够高效地将 AI 模型连接到外部工具和数据源.本篇博客,笔者将指导使用 ...