利用xlrd模块读取excel利用json模块生成相应的json文件的脚本
excel的格式如下
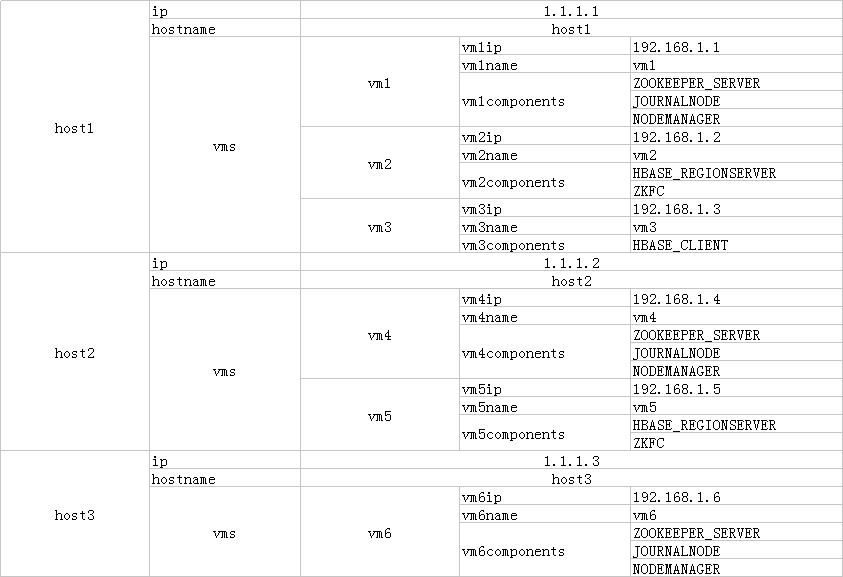
python代码如下,这里最难的就是合并单元格的处理
import xlrd
import json excel_obj = xlrd.open_workbook("test.xlsx") sheet_name = excel_obj.sheet_names()[0] sheet_obj = excel_obj.sheet_by_index(0) hadoop_dict = {
"services": [
"AMBARI_METRICS",
"HBASE",
"HDFS",
"HIVE",
"KAFKA",
"MAPREDUCE2",
"PIG",
"SLIDER",
"SMARTSENSE",
"SPARK2",
"STORM",
"TEZ",
"YARN",
"ZOOKEEPER"
],
"pm_group" :[],
"host_groups":[]
} host = {}
vm = {}
# components_list = [] r_num = sheet_obj.nrows
c_num = sheet_obj.ncols merge_cell_list = sheet_obj.merged_cells # for i in range(r_num):
# if sheet_obj.cell_value(i,c_num-1):
# components_list.append(sheet_obj.cell_value(i,c_num-1)) # 获取最后一列的所有数据 for i in merge_cell_list:
if i[2] == 0:
host[sheet_obj.cell_value(i[0],i[2])] = [i[0],i[1],i[2],i[3]] # 存放所有合并的单元格 for k,v in host.items():
host_dict = {}
print(sheet_obj.cell_value(v[0],1),sheet_obj.cell_value(v[0],2),sep="---->")
# 获取主机的ip地址
pm_ip = sheet_obj.cell_value(v[0],2)
print(pm_ip,"物理机地址") print(sheet_obj.cell_value(v[0] + 1,1),sheet_obj.cell_value(v[0] + 1,2),sep="---->")
# 获取主机的主机名
pm_name = sheet_obj.cell_value(v[0] + 1,2) host_dict["ip"] = pm_ip
host_dict["hostname"] = pm_name
host_dict["vms"] = [] for vms_cell in merge_cell_list:
vm_dict = {}
vm_components_dict = {}
if vms_cell[1] <= host[k][1] and vms_cell[2] == 2 and vms_cell[0] > host[k][0] + 1:
print(sheet_obj.cell_value(vms_cell[0],2))
# 获取虚拟机的名称
print(sheet_obj.cell_value(vms_cell[0],vms_cell[2] + 1))
# 获取虚拟机的ip的k print(sheet_obj.cell_value(vms_cell[0],vms_cell[2] + 2))
# 获取虚拟机的ip地址
vm_ip = sheet_obj.cell_value(vms_cell[0], vms_cell[2] + 2) print(sheet_obj.cell_value(vms_cell[0] + 1, vms_cell[2] + 1))
# 获取虚拟机的虚拟机名称的k print(sheet_obj.cell_value(vms_cell[0] + 1, vms_cell[2] + 2))
# 获取虚拟机的名字的值 vm_name = sheet_obj.cell_value(vms_cell[0] + 1, vms_cell[2] + 2) vm_name = sheet_obj.cell_value(vms_cell[0] + 1, vms_cell[2] + 2)
vm_dict = {
"hostname":vm_name,
} vm_components_dict["ip"] = vm_ip
vm_components_dict["hostname"] = vm_name
vm_components_dict["components"] = [] host_dict["vms"].append(vm_dict) vmcomponents_location_start = vms_cell[0] + 2
vmcomponents_location_end = vms_cell[1]
# print(vmcomponents_location_start,vmcomponents_location_end,"我是大傻逼")
vm_components_info_list = []
for i in range(vmcomponents_location_start,vmcomponents_location_end):
temp_components = sheet_obj.cell_value(i,c_num-1)
vm_components_info_list.append(temp_components) for component in vm_components_info_list:
temp_dict = {}
temp_dict["name"] = component
vm_components_dict["components"].append(temp_dict) hadoop_dict["host_groups"].append(vm_components_dict) # 获取每个虚拟机的components信息
hadoop_dict["pm_group"].append(host_dict) import json
file_name = "journalnode_".upper() + "test_journalnode_case_1" + "." + "json"
my_file_obj = open(file_name,"w") json.dump(hadoop_dict,my_file_obj,indent=4)
my_file_obj.close()
最后按照要求生成制定格式的json文件
{
"services": [
"AMBARI_METRICS",
"HBASE",
"HDFS",
"HIVE",
"KAFKA",
"MAPREDUCE2",
"PIG",
"SLIDER",
"SMARTSENSE",
"SPARK2",
"STORM",
"TEZ",
"YARN",
"ZOOKEEPER"
],
"pm_group": [
{
"ip": "1.1.1.1",
"hostname": "host1",
"vms": [
{
"hostname": "vm1"
},
{
"hostname": "vm2"
},
{
"hostname": "vm3"
}
]
},
{
"ip": "1.1.1.2",
"hostname": "host2",
"vms": [
{
"hostname": "vm4"
},
{
"hostname": "vm5"
}
]
},
{
"ip": "1.1.1.3",
"hostname": "host3",
"vms": [
{
"hostname": "vm6"
}
]
}
],
"host_groups": [
{
"ip": "192.168.1.1",
"hostname": "vm1",
"components": [
{
"name": "ZOOKEEPER_SERVER"
},
{
"name": "JOURNALNODE"
},
{
"name": "NODEMANAGER"
}
]
},
{
"ip": "192.168.1.2",
"hostname": "vm2",
"components": [
{
"name": "HBASE_REGIONSERVER"
},
{
"name": "ZKFC"
}
]
},
{
"ip": "192.168.1.3",
"hostname": "vm3",
"components": [
{
"name": "HBASE_CLIENT"
}
]
},
{
"ip": "192.168.1.4",
"hostname": "vm4",
"components": [
{
"name": "ZOOKEEPER_SERVER"
},
{
"name": "JOURNALNODE"
},
{
"name": "NODEMANAGER"
}
]
},
{
"ip": "192.168.1.5",
"hostname": "vm5",
"components": [
{
"name": "HBASE_REGIONSERVER"
},
{
"name": "ZKFC"
}
]
},
{
"ip": "192.168.1.6",
"hostname": "vm6",
"components": [
{
"name": "ZOOKEEPER_SERVER"
},
{
"name": "JOURNALNODE"
},
{
"name": "NODEMANAGER"
}
]
}
]
}
利用xlrd模块读取excel利用json模块生成相应的json文件的脚本的更多相关文章
- 利用 pandas库读取excel表格数据
利用 pandas库读取excel表格数据 初入IT行业,愿与大家一起学习,共同进步,有问题请指出!! 还在为数据读取而头疼呢,请看下方简洁介绍: 数据来源为国家统计局网站下载: 具体方法 代码: i ...
- Python xlrd模块读取Excel表中的数据
1.xlrd库的安装 直接使用pip工具进行安装(当然也可以使用pycharmIDE进行安装,这里就不详述了) pip install xlrd 2.xlrd模块的一些常用命令 ①打开excel文件并 ...
- Xlrd模块读取Excel文件数据
Xlrd模块使用 excel文件样例:
- Python-用xlrd模块读取excel,数字都是浮点型,日期格式是数字的解决办法
excel文件内容: 读取excel: # coding=utf-8 import xlrd import sys reload(sys) sys.setdefaultencoding('utf-8' ...
- 猜想-未做 利用office组件读取excel数据
---未实际使用过 用SQL-Server访问Office的Access和Excel http://blog.sina.com.cn/s/blog_964237ea0101532x.html 2007 ...
- python 利用三方的xlrd模块读取excel文件,处理合并单元格
目的: python能使用xlrd模块实现对Excel数据的读取,且按照想要的输出形式. 总体思路: (1)要想实现对Excel数据的读取,需要用到第三方应用,直接应用. (2)实际操作时候和我 ...
- 后端Nodejs利用node-xlsx模块读取excel
后端Nodejs(利用node-xlsx模块) /** * Created by zh on 16-9-14. */ var xlsx = require("node-xlsx") ...
- 基础补充:使用xlrd模块读取excel文件
因为接口测试用例使用excel文件来维护的,所以有必要学习下操作excel的基本方法 参考博客:python 3 操作 excel 把自己练习的代码贴出来,是一些基本的操作,每行代码后面都加了注释. ...
- python-利用xlrd模块读取excel数据,将excel数据转换成字典格式
前言 excel测试案例数据 转换成这种格式 实现代码 import os import xlrd excel_path = '..\data\\test_case.xlsx' data_path = ...
随机推荐
- 清除linux服务器缓存 clean.sh
#!/bin/sh#根据输入参数创建后台进程的日志名称#FileName: createNohupPhpForbak.sh #export JAVA_HOME=/root/lib/jdk1.7.0_7 ...
- css3 之border-radius 属性解析
在css 设置样式的时候,有时候会用到将元素的边框设置为圆形的样子的时候,一般都是通常直接设置:{border-radius:5px },这样就行了,但是到底是什么意思,一直以来都没有弄明白,只是知道 ...
- 几道关于springboot、springCloud的面试题。
什么是springboot 用来简化spring应用的初始搭建以及开发过程 使用特定的方式来进行配置(propertites或yml文件) 创建独立的spring引用程序main方法运行 嵌入的tom ...
- linux 文件系统之superblock
为了实际测试这个pagecache和对裸盘操作的区别,我一不小心敲错命令,将一个磁盘的super_block给抹掉了,全是0, dd if =/dev/zero of=/dev/sda2 bs=409 ...
- 如何使用JBDC修改数据
1.JDBC取得数据库Connection连接对象conn, Connection conn=null; //数据库连接对象 String strSql=null; //sql语句对象 // ...
- angularjs中安卓原生APP调用H5页面js函数,js写法应注意
安卓原生app调用js方法,js方法应写在html下的script标签内,不能有任何function包裹,例如angular的controller层,这样APP也是获取不到的: 所以只有放在html中 ...
- winform,listbox设置行高
//必须要在写这个事件里写才有效果 private void listBox1_MeasureItem(object sender, MeasureItemEventArgs e) { e.ItemH ...
- mongo的csv文件参考
https://blog.csdn.net/u012318074/article/details/77713228
- 微信小程序之富文本解析
亲身体验 wxparse 是个坑,弃之不用 微信小程序的 <rich-text>标签挺好用的 用法如下: 1.wxml页面 <rich-text nodes="{{node ...
- 03_java基础(四)之方法的创建与调用
import org.junit.Test; public class Main { public static void main(String[] args) { System.out.print ...