Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.MR文件格式-SequenceFile
1>.生成SequenceFile文件(SequenceFileOutputFormat)
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
word.txt 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.sequencefile.output; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class SeqMapper extends Mapper<LongWritable, Text , LongWritable, Text> { @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(key,value); }
}
SeqMapper.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.sequencefile.output; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; /**
* 把wc.txt变为SequenceFile
* k-偏移量-LongWritable
* v-一行文本-Text
*/
public class SeqApp { public static void main(String[] args) throws Exception { Configuration conf = new Configuration();
conf.set("fs.defaultFS","file:///");
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf); job.setJobName("Seq-Out");
job.setJarByClass(SeqApp.class); //设置输出格式,这里的输出格式要和咱们Mapper程序的格式要一致哟!
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class); job.setMapperClass(SeqMapper.class); FileInputFormat.addInputPath(job, new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\word.txt")); Path outPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\seqout");
if (fs.exists(outPath)){
fs.delete(outPath);
}
FileOutputFormat.setOutputPath(job,outPath); //设置文件输出格式为SequenceFile
job.setOutputFormatClass(SequenceFileOutputFormat.class); //设置SeqFile的压缩类型为块压缩
SequenceFileOutputFormat.setOutputCompressionType(job,SequenceFile.CompressionType.BLOCK); //以上设置参数完毕后,我们通过下面这行代码就开始运行job
job.waitForCompletion(true);
}
}
运行以上代码之后,我们可以去输出目录通过hdfs命令查看生成的SequenceFile文件内容,具体操作如下:
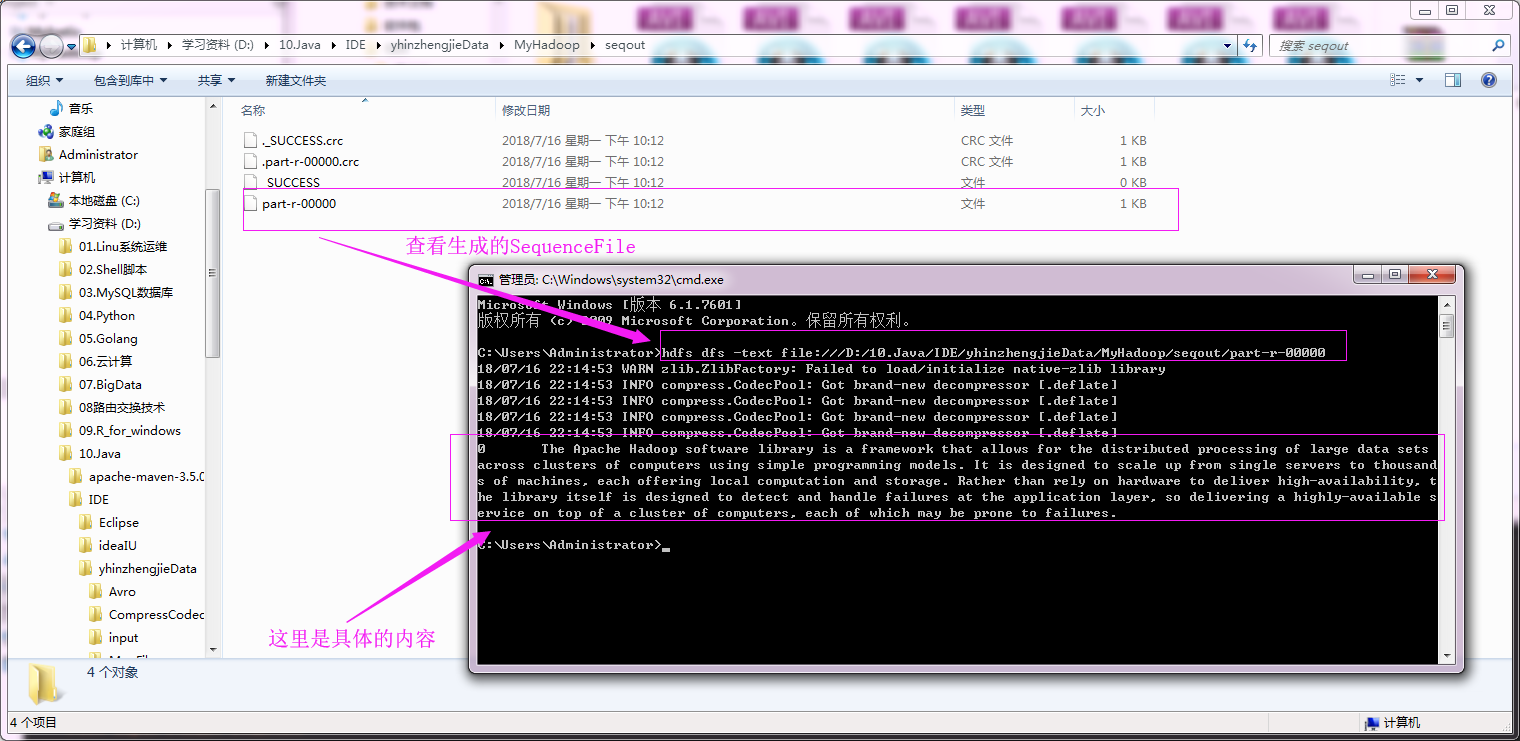
2>.对SequenceFile文件进行单词统计测试(SequenceFileInputFormat)
我们就不用去可以找具体的SequenceFile啦,我们直接用上面生成的Sequence进行测试,具体代码如下:
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.sequencefile.input; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class SeqMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString();
String[] arr = line.split(" ");
for(String word: arr){
context.write(new Text(word),new IntWritable(1)); } }
}
SeqMapper.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.sequencefile.input; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException; public class SeqReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
Integer sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
SeqReducer.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.sequencefile.input; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class SeqApp {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","file:///");
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf);
job.setJobName("Seq-in");
job.setJarByClass(SeqApp.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(SeqMapper.class);
job.setReducerClass(SeqReducer.class);
//将我们生成的SequenceFile文件作为输入
FileInputFormat.addInputPath(job, new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\seqout"));
Path outPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\out");
if (fs.exists(outPath)){
fs.delete(outPath);
}
FileOutputFormat.setOutputPath(job, outPath);
//设置输入格式
job.setInputFormatClass(SequenceFileInputFormat.class);
//以上设置参数完毕后,我们通过下面这行代码就开始运行job
job.waitForCompletion(true);
}
}
运行以上代码之后,我们可以查看输出的单词统计情况,具体操作如下:
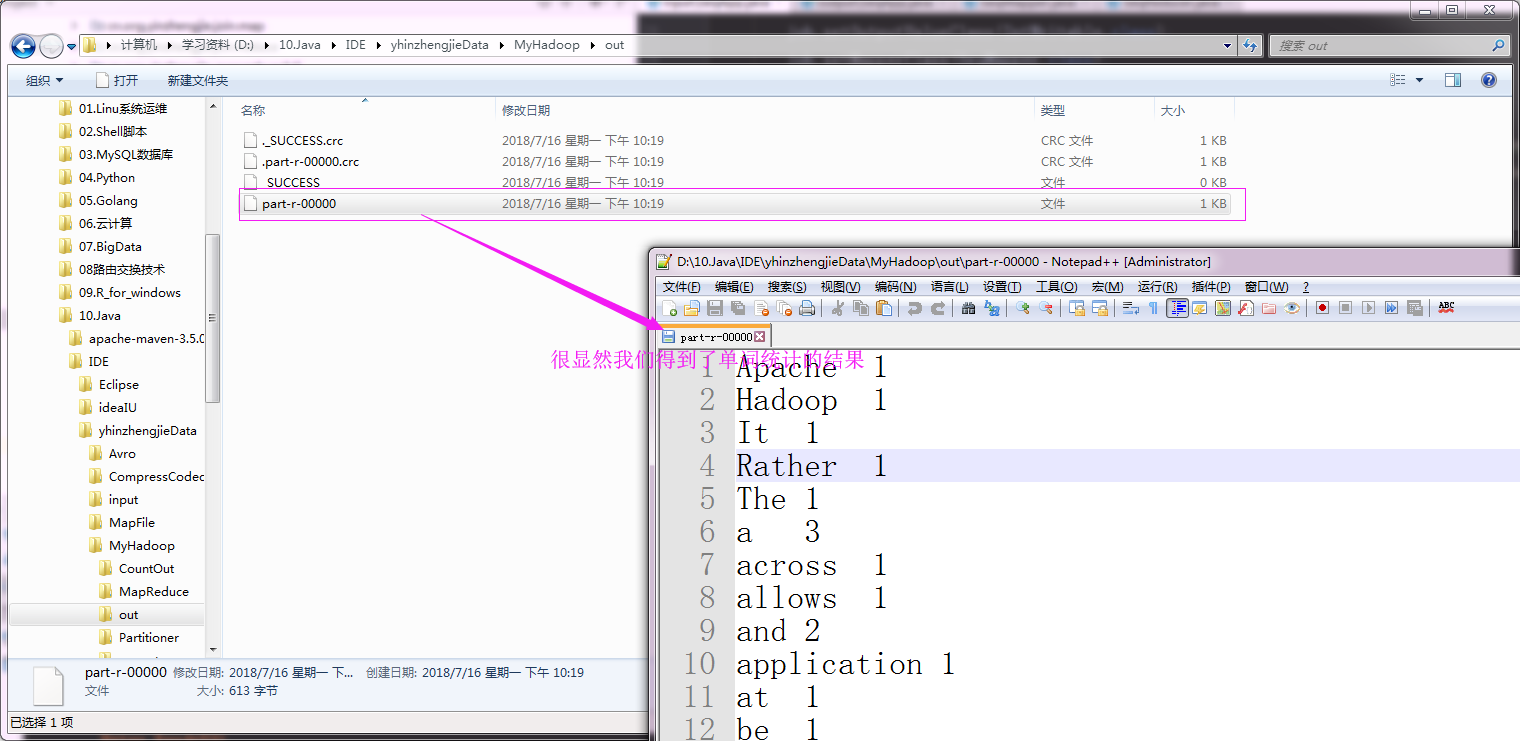
二.MR文件格式-DB
1>.创建数据库表信息
create database yinzhengjie; use yinzhengjie; create table wordcount(id int,line varchar(100)); insert into wordcount values(1,'hello my name is yinzhengjie'); insert into wordcount values(2,'I am a good boy'); create table wordcount2(word varchar(100),count int);

2>.编写代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.dbformat; import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException; /**
* 设置数据对应的格式,需要实现两个接口,即Writable, DBWritable。
*/
public class MyDBWritable implements Writable, DBWritable { //注意 : 这里我们定义了2个私有属性,这两个属性分别对应的数据库中的字段,id和line
private int id;
private String line; //wrutable串行化
public void write(DataOutput out) throws IOException {
out.writeInt(id);
out.writeUTF(line);
} //writable反串行化,注意反串行化的顺序要和串行化的顺序保持一致
public void readFields(DataInput in) throws IOException {
id = in.readInt();
line = in.readUTF(); } //DB串行化,设置值的操作
public void write(PreparedStatement st) throws SQLException {
//指定表中的第一列为id列
st.setInt(1, id);
//指定表中的第二列为line列
st.setString(2,line); } //DB反串行,赋值操作
public void readFields(ResultSet rs) throws SQLException {
//读取数据库的第一列,我们赋值给id
id = rs.getInt(1);
//读取数据库的第二列,我们赋值给line
line = rs.getString(2);
} public int getId() {
return id;
} public void setId(int id) {
this.id = id;
} public String getLine() {
return line;
} public void setLine(String line) {
this.line = line;
}
}
MyDBWritable.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.dbformat; import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException; public class MyDBWritable2 implements Writable, DBWritable {
//这两个属性分别对应的数据库中的字段,word和count分别对应的是输出表中的字段哟。
private String word;
private int count;
//wrutable串行化
public void write(DataOutput out) throws IOException {
out.writeUTF(word);
out.writeInt(count);
}
//writable反串行化
public void readFields(DataInput in) throws IOException {
word = in.readUTF();
count = in.readInt(); }
//DB串行化
public void write(PreparedStatement st) throws SQLException {
st.setString(1,word);
st.setInt(2,count); }
//DB反串行
public void readFields(ResultSet rs) throws SQLException {
word = rs.getString(1);
count = rs.getInt(2);
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
}
MyDBWritable2.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.dbformat; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* 注意MyDBWritable为数据库输入格式哟
*/
public class DBMapper extends Mapper<LongWritable, MyDBWritable, Text, IntWritable> {
@Override
protected void map(LongWritable key, MyDBWritable value, Context context) throws IOException, InterruptedException {
String line = value.getLine();
String[] arr = line.split(" ");
for(String word : arr){
context.write(new Text(word), new IntWritable(1));
}
}
}
DBMapper.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.dbformat; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class DBReducer extends Reducer<Text, IntWritable, MyDBWritable2, NullWritable> {
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
Integer sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
MyDBWritable2 db = new MyDBWritable2();
//设置需要往数据表中写入数据的值
db.setWord(key.toString());
db.setCount(sum);
//将数据写到到数据库中
context.write(db,NullWritable.get());
}
}
DBReducer.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.dbformat; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat; public class DBApp { public static void main(String[] args) throws Exception { Configuration conf = new Configuration();
conf.set("fs.defaultFS","file:///");
Job job = Job.getInstance(conf); job.setJobName("DB");
job.setJarByClass(DBApp.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); job.setMapperClass(DBMapper.class);
job.setReducerClass(DBReducer.class); String driver = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://192.168.0.254:5200/yinzhengjie";
String name = "root";
String pass = "yinzhengjie"; DBConfiguration.configureDB(job.getConfiguration(), driver, url, name, pass); DBInputFormat.setInput(job, MyDBWritable.class,"select * from wordcount", "select count(*) from wordcount"); //指定表名为“wordcount2”并指定字段为2
DBOutputFormat.setOutput(job,"wordcount2",2); //指定输入输出格式
job.setInputFormatClass(DBInputFormat.class);
job.setOutputFormatClass(DBOutputFormat.class); job.waitForCompletion(true);
}
}
运行以上代码之后,我们可以查看数据库wordcount2表中的数据是否有新的数据生成,具体操作如下:

Hadoop基础-MapReduce的常用文件格式介绍的更多相关文章
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的Join操作
Hadoop基础-MapReduce的Join操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.连接操作Map端Join(适合处理小表+大表的情况) no001 no002 ...
- Hadoop基础-MapReduce的排序
Hadoop基础-MapReduce的排序 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce的排序分类 1>.部分排序 部分排序是对单个分区进行排序,举个 ...
- Hadoop基础-MapReduce的数据倾斜解决方案
Hadoop基础-MapReduce的数据倾斜解决方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据倾斜简介 1>.什么是数据倾斜 答:大量数据涌入到某一节点,导致 ...
- Hadoop基础-MapReduce的Partitioner用法案例
Hadoop基础-MapReduce的Partitioner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Partitioner关键代码剖析 1>.返回的分区号 ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- openresty开发系列13--lua基础语法2常用数据类型介绍
openresty开发系列13--lua基础语法2常用数据类型介绍 一)boolean(布尔)布尔类型,可选值 true/false: Lua 中 nil 和 false 为"假" ...
随机推荐
- Kubernetes学习之路(二十四)之Prometheus监控
目录 1.Prometheus概述 2.Prometheus部署 2.1.创建名称空间prom 2.2.部署node_exporter 2.3.部署prometheus-server 2.4.部署ku ...
- python 算法面试题
1.题目是:有一组“+”和“-”符号,要求将“+”排到左边,“-”排到右边,写出具体的实现方法. def StringSort(data): startIndex=0 endIndex=0 count ...
- Panorama——H5实现全景图片原理
前言 H5是怎么实现全景图片播放呢? 正文 全景图的基本原理即 "等距圆柱投影",这是一种将球体上的各个点投影到圆柱体的侧面上的一种投影方式,投影后再展开就是一张 2:1 的矩形图 ...
- effective c++ 笔记 (31-34)
//---------------------------15/04/20---------------------------- //#32 确定你的public继承塑膜出 is-a 关系 { ...
- jquery原理的简单分析,让你扒开jquery的小外套。
引言 最近LZ还在消化系统原理的第三章,因此这部分内容LZ打算再沉淀一下再写.本次LZ和各位来讨论一点前端的内容,其实有关jquery,在很久之前,LZ就写过一篇简单的源码分析.只不过当时刚开始写博客 ...
- WebService技术,服务端发布到Tomcat(使用Servlet发布),客户端使用axis2实现(二)
还是在WebService技术,服务端and客户端JDK-wsimport工具(一)的基础上实现.新建一个包:com.aixs2client.目录结构如下: 一.服务端: 1.还是使用com.webs ...
- vsftp在防火墙开启需要开放的端口
1.开放tcp端口 firewall-cmd --zone=public --add-port=20/tcp --permanent firewall-cmd --zone=public --add- ...
- 《陪孩子像搭积木一样学编程》,一起来玩Scratch(1)使用Scratch编程的基本流程
编程是一件很有趣的事情.初次接触编程,你可能不知所措,别担心,这并不复杂.首先,为了让读者对编程有大概的了解,可以把编写Scratch程序的过程分成7个步骤(如图1.8).注意,这是理想状态.在实际的 ...
- PHP学习 Cookie和Session
<?phpheader("Content-type:text/html;charset=utf-8");session_start(); $_SESSION['count'] ...
- node 随便升级到最新版本的遭遇
将node 升级到最新版本后,创建一个RN新项目,执行:react-native init AwesomeProject 遇到: error An unexpected error occurred ...