时间序列异常检测算法S-H-ESD
1. 基于统计的异常检测
Grubbs' Test
Grubbs' Test为一种假设检验的方法,常被用来检验服从正太分布的单变量数据集(univariate data set)\(Y\) 中的单个异常值。若有异常值,则其必为数据集中的最大值或最小值。原假设与备择假设如下:
\(H_0\): 数据集中没有异常值
\(H_1\): 数据集中有一个异常值
Grubbs' Test检验假设的所用到的检验统计量(test statistic)为
\[
G = \frac{\max |Y_i - \overline{Y}|}{s}
\]
其中,\(\overline{Y}\)为均值,\(s\)为标准差。原假设\(H_0\)被拒绝,当检验统计量满足以下条件
\[
G > \frac{(N-1)}{\sqrt{N}}\sqrt{\frac{ (t_{\alpha/(2N), N-2})^2}{N-2 + (t_{\alpha/(2N), N-2})^2}}
\]
其中,\(N\)为数据集的样本数,\(t_{\alpha/(2N), N-2}\)为显著度(significance level)等于\(\alpha/(2N)\)、自由度(degrees of freedom)等于\(N-2\)的t分布临界值。实际上,Grubbs' Test可理解为检验最大值、最小值偏离均值的程度是否为异常。
ESD
在现实数据集中,异常值往往是多个而非单个。为了将Grubbs' Test扩展到\(k\)个异常值检测,则需要在数据集中逐步删除与均值偏离最大的值(为最大值或最小值),同步更新对应的t分布临界值,检验原假设是否成立。基于此,Rosner提出了Grubbs' Test的泛化版ESD(Extreme Studentized Deviate test)。算法流程如下:
- 计算与均值偏离最远的残差,注意计算均值时的数据序列应是删除上一轮最大残差样本数据后;
\begin{equation}
R_j = \frac{\max_i |Y_i - \overline{Y'}|}{s}, \quad 1 \leq j \leq k
\label{eq:esd_test}
\end{equation}
- 计算临界值(critical value);
\[
\lambda_j = \frac{(n-j) * t_{p,n-j-1}}{\sqrt{(n-j-1+t_{p,n-j-1}^2)(n-j+1)}}, \quad 1 \leq j \leq k
\]
检验原假设,比较检验统计量与临界值;若\(R_i > \lambda_j\),则原假设\(H_0\)不成立,该样本点为异常点;
重复以上步骤\(k\)次至算法结束。
2. 时间序列的异常检测
鉴于时间序列数据具有周期性(seasonal)、趋势性(trend),异常检测时不能作为孤立的样本点处理;故而Twitter的工程师提出了S- ESD (Seasonal ESD)与S-H-ESD (Seasonal Hybrid ESD)算法,将ESD扩展到时间序列数据。
S-ESD
STL将时间序列数据分解为趋势分量、周期分量和余项分量。想当然的解法——将ESD运用于STL分解后的余项分量中,即可得到时间序列上的异常点。但是,我们会发现在余项分量中存在着部分假异常点(spurious anomalies)。如下图所示:
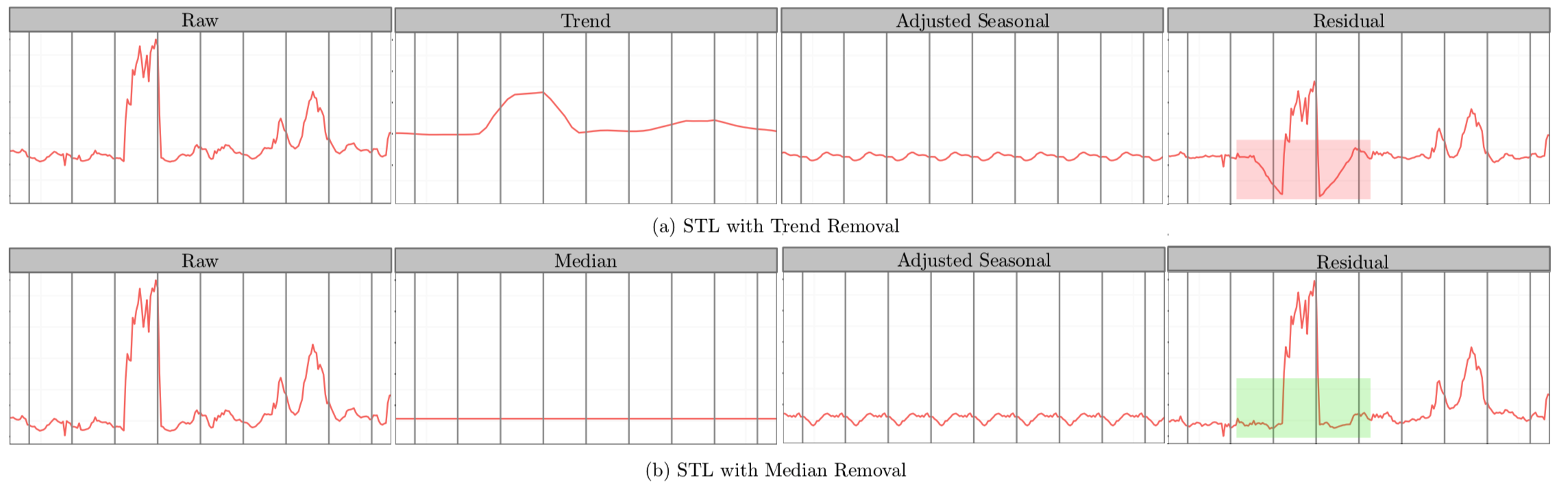
在红色矩形方框中,向下突起点被误报为异常点。为了解决这种假阳性降低准确率的问题,S-ESD算法用中位数(median)替换掉趋势分量;余项计算公式如下:
\[
R_X = X - S_X- \tilde{X}
\]
其中,\(X\)为原时间序列数据,\(S_X\)为STL分解后的周期分量,\(\tilde{X}\)为\(X\)的中位数。
S-H-ESD
由于个别异常值会极大地拉伸均值和方差,从而导致S-ESD未能很好地捕获到部分异常点,召回率偏低。为了解决这个问题,S-H-ESD采用了更具鲁棒性的中位数与绝对中位差(Median Absolute Deviation, MAD)替换公式\eqref{eq:esd_test}中的均值与标准差。MAD的计算公式如下:
\[
MAD = median(|X_i - median(X)|)
\]
S-H-ESD的Python实现有pyculiarity,时间序列异常检测数据集有Yahoo公开的A Labeled Anomaly Detection Dataset。
3. 参考资料
[1] Hochenbaum, Jordan, Owen S. Vallis, and Arun Kejariwal. "Automatic Anomaly Detection in the Cloud Via Statistical Learning." arXiv preprint arXiv:1704.07706 (2017).
时间序列异常检测算法S-H-ESD的更多相关文章
- 机器学习:异常检测算法Seasonal Hybrid ESD及R语言实现
Twritters的异常检测算法(Anomaly Detection)做的比较好,Seasonal Hybrid ESD算法是先用STL把序列分解,考察残差项.假定这一项符合正态分布,然后就可以用Ge ...
- 异常检测算法--Isolation Forest
南大周志华老师在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据,这里对这个算法进行简要总结. iTree 提到森林 ...
- 异常检测算法:Isolation Forest
iForest (Isolation Forest)是由Liu et al. [1] 提出来的基于二叉树的ensemble异常检测算法,具有效果好.训练快(线性复杂度)等特点. 1. 前言 iFore ...
- kaggle信用卡欺诈看异常检测算法——无监督的方法包括: 基于统计的技术,如BACON *离群检测 多变量异常值检测 基于聚类的技术;监督方法: 神经网络 SVM 逻辑回归
使用google翻译自:https://software.seek.intel.com/dealing-with-outliers 数据分析中的一项具有挑战性但非常重要的任务是处理异常值.我们通常将异 ...
- 基于RRCF(robust random cut forest)的时间序列异常检测流程
摘要:RRCF是亚马逊提出的一个流式异常检测算法,是对孤立森林的改进,可对时序或非时序数据进行异常检测.本文是我从事AIOps研发工作时所做的基于RRCF的时序异常检测方案. 1. 数据格式 ...
- 【机器学习】异常检测算法(I)
在给定的数据集,我们假设数据是正常的 ,现在需要知道新给的数据Xtest中不属于该组数据的几率p(X). 异常检测主要用来识别欺骗,例如通过之前的数据来识别新一次的数据是否存在异常,比如根据一个用户以 ...
- 如何开发一个异常检测系统:使用什么特征变量(features)来构建异常检测算法
如何构建与选择异常检测算法中的features 如果我的feature像图1所示的那样的正态分布图的话,我们可以很高兴地将它送入异常检测系统中去构建算法. 如果我的feature像图2那样不是正态分布 ...
- 异常检测(Anomaly detection): 异常检测算法(应用高斯分布)
估计P(x)的分布--密度估计 我们有m个样本,每个样本有n个特征值,每个特征都分别服从不同的高斯分布,上图中的公式是在假设每个特征都独立的情况下,实际无论每个特征是否独立,这个公式的效果都不错.连乘 ...
- 异常检测算法的Octave仿真
在基于高斯分布的异常检测算法一文中,详细给出了异常检测算法的原理及其公式,本文为该算法的Octave仿真.实例为,根据训练样例(一组网络服务器)的吞吐量(Throughput)和延迟时间(Latenc ...
随机推荐
- Hibernate中报错org.hibernate.HibernateException: No CurrentSessionContext configured!
报错信息如下: 解决方法: 问题原因是getCurrentSession()出现了问题 在hibernate.cfg.xml(hibernate的核心配置文件)文件中加入下列代码: <prope ...
- Codeforces 514C Watto and Mechanism 【Trie树】+【DFS】
<题目链接> 题目大意:输入n个单词构成单词库,然后进行m次查询,每次查询输入一个单词(注意这些单词只由a,b,c构成),问该单词库中是否存在与当前查询的单词有且仅有一个字符不同的单词. ...
- RFC2616-HTTP1.1-Methods(方法规定部分—译文)
part of Hypertext Transfer Protocol -- HTTP/1.1RFC 2616 Fielding, et al. 9 方法定义 下面列出了有关HTTP/1.1协议的一些 ...
- XamarinEssentials教程清空键值
XamarinEssentials教程清空键值 Preferences类的Clear()方法可以清空所有的键和值.该方法有两种形式,下面依次进行介绍. (1)Clear()方法的语法形式如下: pub ...
- 后台执行Bitmap加载
如果加载图片时,使用的图片数据源不是来自于内存,而是来自硬盘或网络时,一般不会再UI线程执行图片加载操作. 图片的加载速度取决于很多方面(往往具有不可预测性),比如:硬盘或者网络的读写速度.图片大小. ...
- python网络编程(九)
单进程服务器-非堵塞模式 服务器 #coding=utf-8 from socket import * import time # 用来存储所有的新链接的socket g_socketList = [ ...
- C++知识点:拷贝构造函数例子
//拷贝构造函数: //函数参数传递时调用一次拷贝构造函数,给对象赋值时调用一次拷贝构造函数,对象作为参数传递后会被及时销毁. #include <fstream> #include &l ...
- Cocos Creator存储和读取用户数据--官方文档
存储数据 cc.sys.localStorage.setItem(key, value) 上面的方法需要两个参数,用来索引的字符串键值 key,和要保存的字符串数据 value. 假如我们要保存玩家最 ...
- python字符串面试题:找出一个字符串中第一个字母和最后一个字符是第一次重复,中间没有重复且最长的子串
1.给出任意一个字符串,打印一个最长子串字符串及其长度,如果有相同长度的子字符串,都要一起打印出来,该子字符串满足以下条件, 第一个字母和最后一个字符是第一次重复 这个子字符串的中间字母没有重复 这个 ...
- 深入理解this,bind、call
直接看this 直接看call和bind 首先放一道题: var a={ a:'haha', getA: function(){ console.log(this.a); } } var b= { a ...