kudu记录-kudu原理
1.kudu是什么?
2.kudu基本概念
特点:
High availability(高可用性)。Tablet server 和 Master 使用 Raft Consensus Algorithm 来保证节点的高可用,确保只要有一半以上的副本可用,该 tablet 便可用于读写。例如,如果3个副本中有2个或5个副本中的3个可用,则该tablet可用。即使在 leader tablet 出现故障的情况下,读取功能也可以通过 read-only(只读的)follower tablets 来进行服务,或者是leader宕掉的情况下,会根据raft机制重新选举leader。
基础概念:
开发语言:C++
Columnar Data Store(列式数据存储)
Read Efficiency(高效读取)
对于分析查询,允许读取单个列或该列的一部分同时忽略其他列
Data Compression(数据压缩)
由于给定的列只包含一种类型的数据,基于模式的压缩比压缩混合数据类型(在基于行的解决案中使用)时更有效几个数量级。结合从列读取数据的效率,压缩允许您在从磁盘读取更少的块时完成查询
Table(表)
一张table是数据存储在 Kudu 的位置。表具有schema和全局有序的primary key(主键)。table被分成很多段,也就是称为tablets。
Tablet(段)
一个tablet是一张table连续的segment,与其它数据存储引擎或关系型数据库的partition(分区)相似。给定的tablet冗余到多个tablet服务器上,并且在任何给定的时间点,其中一个副本被认为是leader tablet。任何副本都可以对读取进行服务,并且写入时需要在为tablet服务的一组tablet server之间达成一致性。
一张表分成多个tablet,分布在不同的tablet server中,最大并行化操作
Tablet在Kudu中被切分为更小的单元,叫做RowSets,RowSets分为两种MemRowSets和DiskRowSet,MemRowSets每生成32M,就溢写到磁盘中,也就是DiskRowSet
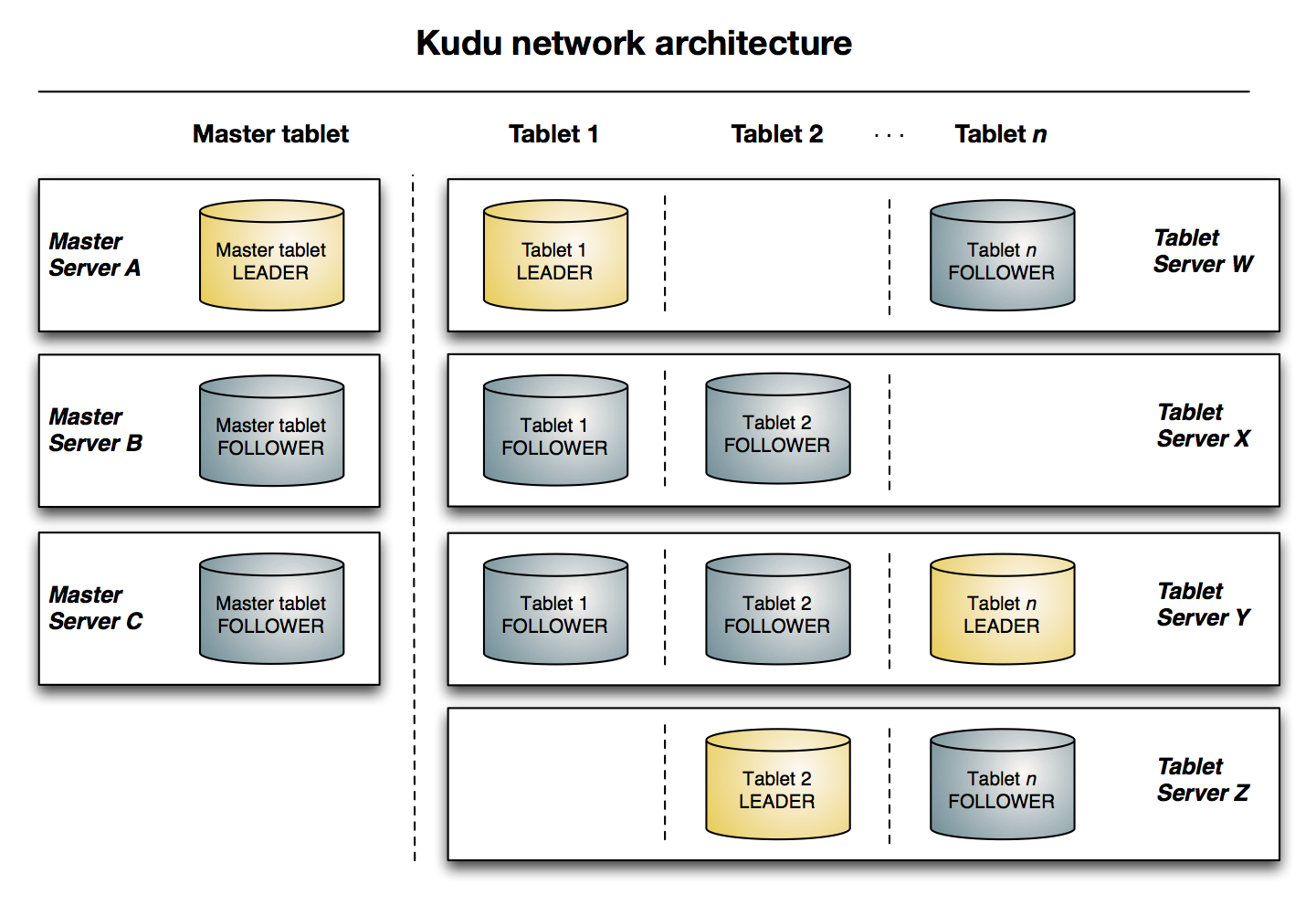
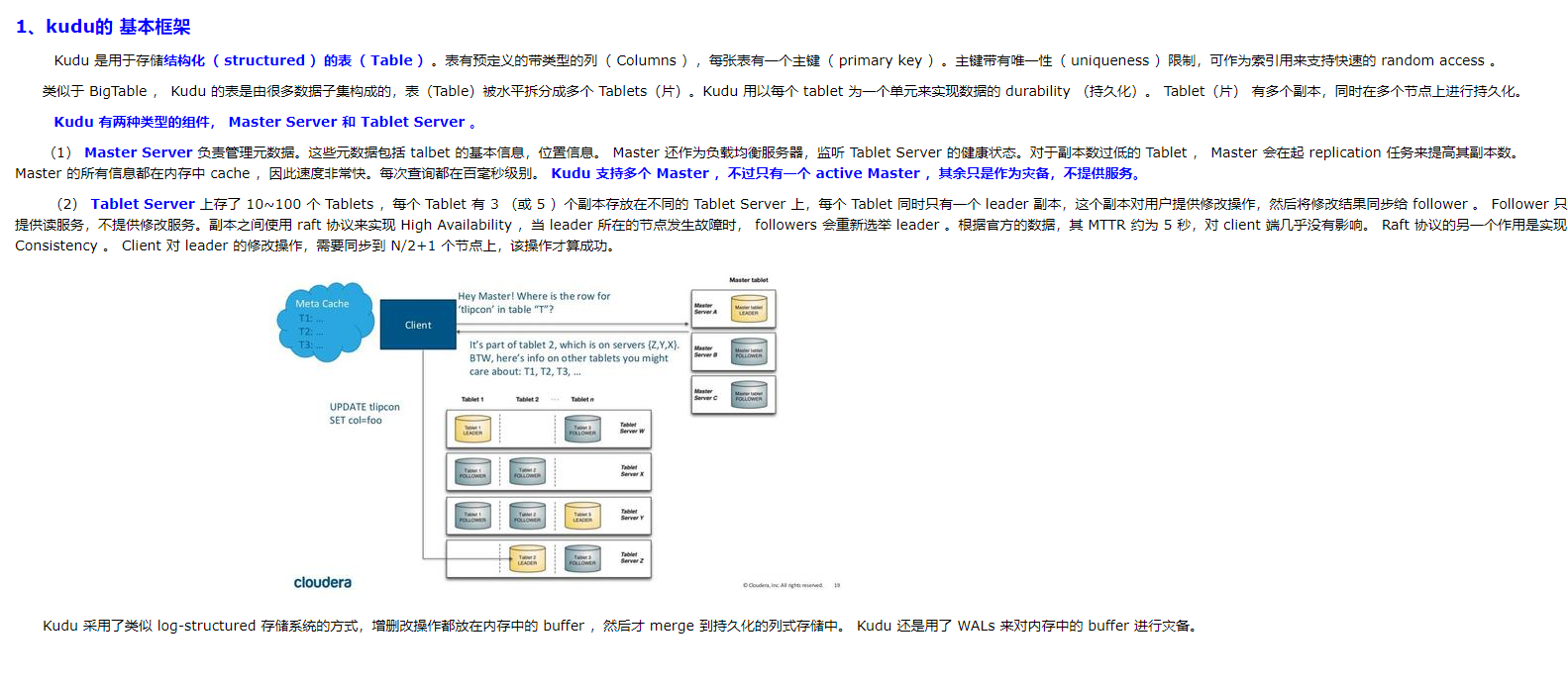
Tablet Server
一个tablet server存储tablet和为tablet向client提供服务。对于给定的tablet,一个tablet server充当 leader,其他tablet server充当该 tablet 的follower副本。只有leader服务写请求,然而leader或followers为每个服务提供读请求。leader使用Raft Consensus Algorithm来进行选举 。一个tablet server可以服务多个tablets,并且一个 tablet 可以被多个tablet servers服务着。
Master
该master保持跟踪所有的tablets,tablet servers,Catalog Table 和其它与集群相关的metadata。在给定的时间点,只能有一个起作用的master(也就是 leader)。如果当前的 leader 消失,则选举出一个新的master,使用 Raft Consensus Algorithm来进行选举。
master还协调客户端的metadata operations(元数据操作)。例如,当创建新表时,客户端内部将请求发送给master。 master将新表的元数据写入catalog table,并协调在tablet server上创建 tablet 的过程。
所有master的数据都存储在一个 tablet 中,可以复制到所有其他候选的 master。
tablet server以设定的间隔向master发出心跳(默认值为每秒一次)。
master是以文件的形式存储在磁盘中,所以说,第一次初始化集群。需要设定好
Raft Consensus Algorithm
Kudu 使用 Raft consensus algorithm 作为确保常规 tablet 和 master 数据的容错性和一致性的手段。通过 Raft,tablet 的多个副本选举出 leader,它负责接受以及复制到 follower 副本的写入。一旦写入的数据在大多数副本中持久化后,就会向客户确认。给定的一组 N 副本(通常为 3 或 5 个)能够接受最多(N - 1)/2 错误的副本的写入。
Catalog Table(目录表)
catalog table是Kudu 的 metadata(元数据中)的中心位置。它存储有关tables和tablets的信息。该catalog table(目录表)可能不会被直接读取或写入。相反,它只能通过客户端 API中公开的元数据操作访问。catalog table 存储两类元数据。
Tables
table schemas, locations, and states(表结构,位置和状态)
Tablets
现有tablet 的列表,每个 tablet 的副本所在哪些tablet server,tablet的当前状态以及开始和结束的keys(键)。
注意:
1、建表的时候要求所有的tserver节点都活着
2、根据raft机制,允许(replication的副本数-)/ 2宕掉,集群还会正常运行,否则会报错找不到ip:7050(7050是rpc的通信端口号),需要注意一个问题,第一次运行的时候要保证集群处于正常状态下,也就是所有的服务都启动,如果运行过程中,允许(replication的副本数-)/ 2宕掉
3、读操作,只要有一台活着的情况下,就可以运行
上图显示了一个具有三个 master 和多个tablet server的Kudu集群,每个服务器都支持多个tablet。它说明了如何使用 Raft 共识来允许master和tablet server的leader和follow。此外,tablet server 可以成为某些 tablet 的 leader,也可以是其他 tablet follower。leader以金色显示,而 follower 则显示为蓝色。
测试:
7个tablet server
ssd硬盘,5分钟manul flush到kudu 1000万数据
总结:
1、KUDU分区数必须预先预定
2、在内存中对每个Tablet分区维护一个MemRowSet来管理最新更新的数据,默认是1G刷新一次或者是2分钟。后Flush到磁盘上形成DiskRowSet,多个DiskRowSet在适当的时候进行归并处理
3、和HBase采用的LSM(LogStructured Merge,很难对数据进行特殊编码,所以处理效率不高)方案不同的是,Kudu对同一行的数据更新记录的合并工作,不是在查询的时候发生的
(HBase会将多条更新记录先后Flush到不同的Storefile中,所以读取时需要扫描多个文件,比较rowkey,比较版本等,然后进行更新操作),
4、既然存在Delta数据,也就意味着数据查询时需要同时检索Base文件和Delta文件,这看起来和HBase的方案似乎又走到一起去了,不同的地方在于,Kudu的Delta文件与Base文件不同,
不是按Key排序的,而是按被更新的行在Base文件中的位移来检索的,号称这样做,在定位Delta内容的时候,不需要进行字符串比较工作,因此能大大加快定位速度,但是无论如何,
Delta文件的存在对检索速度的影响巨大。因此Delta文件的数量会需要控制,需要及时的和Base数据进行合并。由于Base文件是列式存储的,所以Delta文件合并时,可以有选择性的进行,
比如只把变化频繁的列进行合并,变化很少的列保留在Delta文件中暂不合并,这样做也能减少不必要的IO开销。
5、除了Delta文件合并,DRS自身也会需要合并,为了保障检索延迟的可预测性(这一点是HBase的痛点之一,比如分区发生Major Compaction时,读写性能会受到很大影响),
Kudu的compaction策略和HBase相比,有很大不同,kudu的DRS数据文件的compaction,本质上不是为了减少文件数量,实际上Kudu DRS默认是以32MB为单位进行拆分的,
DRS的compaction并不减少文件数量,而是对内容进行排序重组,减少不同DRS之间key的overlap(重复),进而在检索的时候减少需要参与检索的DRS的数量。
而是在更新的时候进行,在Kudu中一行数据只会存在于一个DiskRowSet中,避免读操作时的比较合并工作。那Kudu是怎么做到的呢? 对于列式存储的数据文件,
要原地变更一行数据是很困难的,所以在Kudu中,对于Flush到磁盘上的DiskRowSet(DRS)数据,实际上是分两种形式存在的,一种是Base的数据,按列式存储格式存在,
一旦生成,就不再修改,另一种是Delta文件,存储Base数据中有变更的数据,一个Base文件可以对应多个Delta文件,这种方式意味着,插入数据时相比HBase,
需要额外走一次检索流程来判定对应主键的数据是否已经存在。因此,Kudu是牺牲了写性能来换取读取性能的提升。
更新、删除操作需要记录到特殊的数据结构里,保存在内存中的DeltaMemStore或磁盘上的DeltaFIle里面。DeltaMemStore是B-Tree实现的,因此速度快,而且可修改。磁盘上的DeltaFIle是二进制的列式的块,和base数据一样都是不可修改的。因此当数据频繁删改的时候,磁盘上会有大量的DeltaFiles文件,Kudu借鉴了Hbase的方式,会定期对这些文件进行合并。
3.kudu结构图



kudu记录-kudu原理的更多相关文章
- Kudu系列: Kudu主键选择策略
每个Kudu 表必须设置Pimary Key(unique), 另外Kudu表不能设置secondary index, 经过实际性能测试, 本文给出了选择Kudu主键的几个策略, 测试结果纠正了我之前 ...
- JDK记录-JVM原理与调优(转载)
转载自<https://www.cnblogs.com/andy-zhou/p/5327288.html> 一.什么是JVM JVM是Java Virtual Machine(Java虚拟 ...
- 【Web应用-Kudu】Kudu 管理和诊断 azure web 应用
Azure Kudu是 GitHub 上的一个开源项目,Kudu 站点 (也称为网站控制管理 SCM) 提供了一系列的在线工具,可以帮助用户查看 web 应用的设置,诊断 web 应用,以及安装 w ...
- kudu基础入门
1.kudu介绍 1.1 背景介绍 在KUDU之前,大数据主要以两种方式存储: (1)静态数据: 以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景.这类存储的局限性是数据无法进行随机 ...
- Update(Stage5):Kudu入门_项目介绍_ CDH搭建
Kudu 导读 什么是 Kudu 操作 Kudu 如何设计 Kudu 的表 Table of Contents 1. 什么是 Kudu 1.1. Kudu 的应用场景 1.2. Kudu 和其它存储工 ...
- kudu
Kudu White Paper http://www.cloudera.com/documentation/betas/kudu/0-5-0/topics/kudu_resources.html h ...
- Kudu vs HBase
本文由 网易云发布. 背景 Cloudera在2016年发布了新型的分布式存储系统--kudu,kudu目前也是apache下面的开源项目.Hadoop生态圈中的技术繁多,HDFS作为底层数据存储的 ...
- Kettle系列:使用Kudu API插入数据到Kudu中
本文详细介绍了在Kettle中使用 Kudu API将数据写入Kudu中, 从本文可以学习到:1. 如何编写一个简单的 Kettle 的 Used defined Java class.2. 如何读取 ...
- Kudu系列-基础
Apache Kudu 支持Insert/Update/Delete 等写操作(Kudu 随机写效率也很高, 实测对一个窄表做全字段update, 其速度达到了Insert速度的88%, 而verti ...
随机推荐
- 开源通用爬虫框架YayCrawler-框架的运行机制
这一节我将向大家介绍一下YayCrawler的运行机制,首先允许我上一张图: 首先各个组件的启动顺序建议是Master.Worker.Admin,其实不按这个顺序也没关系,我们为了讲解方便假定是这个启 ...
- Activiti解析.bpmn文件获得User Task节点的CandidateUsers特性的值
参考文档: http://www.cnblogs.com/mingforyou/p/5351332.html http://blog.csdn.net/jackyrongvip/article/det ...
- [同事转帖] .net core的服务器模式和工作站模式
发现自己的服务器上面的进程占用越来越厉害 所以就跟同事讨论了一下 性能组同事 说已经发现 并且给了一个 网址 这里转帖记录一下 避免以后找不到. .NET Core是一个开源通用的开发框架,具有跨平台 ...
- Linux 更改root与home分区大小的方法总结
1. 安装了CentOS7.5的虚拟机 但是发现里面的操作系统 home 分区占到了400g 根分区只有50g 认为不太好,所以要改一下. 2.方法. 好像是xfs的文件格式, 没法使用resize2 ...
- ACM数论之旅12---康托展开((*゚▽゚*)装甲展开,主推进器启动,倒计时3,2,1......)
在我们做题中,搜索也好,动态规划也好,我们往往有时候需要用一个数字表示一种状态 比如有8个灯泡排成一排,如果你用0和1表示灯泡的发光情况 那么一排灯泡就可以转换为一个二进制数字了 比如 0110011 ...
- 选择 Delphi 2007 ( CodeGear Delphi 2007 for Win32 Version 11.0.2837.9583 ) 的理由
选择 Delphi 2007 ( CodeGear Delphi 2007 for Win32 Version 11.0.2837.9583 ) 的理由 我不喜欢用InstallRite的全自动安装包 ...
- IBM推出新一代云计算技术来解决多云管理
IBM 云计算论坛在南京举行,推出了一项全新的开放式技术,使用户能够更加便捷地跨不同云计算基础架构来管理.迁移和整合应用. IBM 多云管理解决方案(Multicloud Manager)控制面板 据 ...
- Linux下创建和删除软、硬链接 可临时处理空间不足
在Linux系统中,内核为每一个新创建的文件分配一个Inode(索引结点),每个文件都有一个惟一的inode号.文件属性保存在索引结点里,在访问文件时,索引结点被复制到内存在,从而实现文件的快速访问. ...
- asp.net 连接SQL Server 数据库并进行相关操作
asp.net 连接数据库,操作数据库主要需要两个类,一个是SqlConnection,一个是SqlCommand SqlConnection用于连接数据库,打开数据库,关闭数据库. 连接数据库需要特 ...
- BZOJ2144跳跳棋——LCA+二分
题目描述 跳跳棋是在一条数轴上进行的.棋子只能摆在整点上.每个点不能摆超过一个棋子.我们用跳跳棋来做一个简单的 游戏:棋盘上有3颗棋子,分别在a,b,c这三个位置.我们要通过最少的跳动把他们的位置移动 ...