频繁项集挖掘之Aprior和FPGrowth算法
频繁项集挖掘的应用多出现于购物篮分析,现介绍两种频繁项集的挖掘算法Aprior和FPGrowth,用以发现购物篮中出现频率较高的购物组合。
基础知识
项:“属性-值”对。比如啤酒2罐。
项集:项的集合。比如{啤酒2罐,…,尿布5片}
K项集:项集中的每个项都有K个项。
支持度:项集在训练元组中同时出现的次数(或者比例)。
置信度:A−>BA−>B的置信度,表示P(B|A)P(B|A),是个条件概率。(置信度大于用户规定的最小置信度的规则是可信的)
兴趣度:A−>BA−>B的置信度与BB的整体占比的差值。兴趣度越大,表示AA对BB的出现起到的促进作用越大。为负值时表示起到的抑制作用。为0时表示没有影响。
子集:被包含于某项集的项集。
超集:能包含某项集的项集。
频繁项集:在训练元组中,同时出现次数超过支持度的项集。
极大频繁项集:对当前频繁项集来说,没有包含它的频繁超集,则称当前项集为极大频繁超集。
Aprior算法
Aprior算法的基本思想是由KK项频繁项集产生K+1K+1项频繁项集,直到满足条件的频繁项集发现为止。
连接定理和频繁子集定理
连接定理:解决如何由KK项集产生K+1K+1项集问题。若有两个KK项集,其前K−1K−1个项是相同的,则这两个项集可以连接产生一个K+1项集。
频繁子集定理:用来压缩搜索空间。若一个项集的子集不是频繁项集,则该项集也不是频繁项集。(换句话说,非频繁项集的超集也是非频繁项集;频繁项集的所有非空子集也都是频繁项集)
Aprior算法步骤
1. 扫描数据库,产生候选1项集和频繁项集。
2. 从2项集开始循环,由频繁K-1项集生成频繁K项集。
2.1 产生候选项集。根据连接定理,产生候选项集(有个排序的要求,加快比较)。
2.2 去掉非频繁项集。根据频繁子集定理产生频繁项集。
2.3 去掉不符合条件的项集。扫描数据库,计算支持度、置信度、兴趣度,去掉不符合条件的项集。(这地方可变)
2.4 判断迭代终止条件。
Apriro优缺点
Aprior优点:
1)对大型数据库的处理能力,不需要将数库读入内存就可以完成频繁项集的挖掘。
Aprior缺点:
1)需要多次扫描数据库,效率低下。
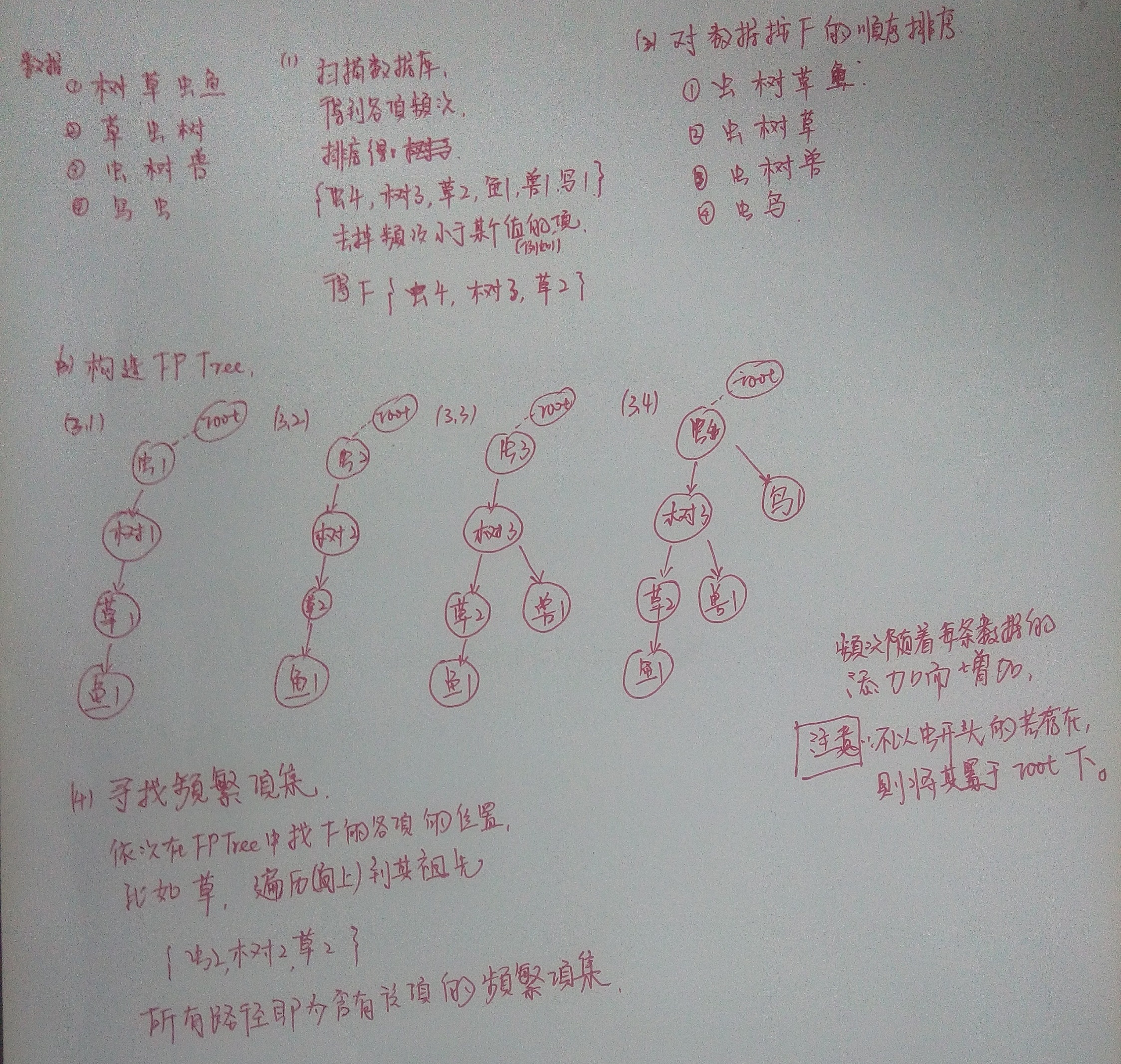
FPGrowth算法
FPGrowth的基本思想是将原始数据压缩到一个FPTree上,在该树上进行频繁项集的挖掘。(FPTree是共用前缀的)
FPGrowth算法步骤
讲地非常好的FPGrowth算法博客(包括原理讲解和代码实现):
(1)http://blog.csdn.net/huagong_adu/article/details/17739247 (2)http://www.cnblogs.com/zhangchaoyang/articles/2198946.html
FPGrowth优缺点
优点:
1)只需要扫描两边数据库,效率高。
2)可以并行化实现。
缺点:
1)受内存大小限制。
频繁项集挖掘之Aprior和FPGrowth算法的更多相关文章
- 频繁项集挖掘之apriori和fp-growth
Apriori和fp-growth是频繁项集(frequent itemset mining)挖掘中的两个经典算法,虽然都是十几年前的,但是理解这两个算法对数据挖掘和学习算法都有很大好处.在理解这两个 ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:非hash方法
http://blog.csdn.net/pipisorry/article/details/48914067 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:基于hash的方法
http://blog.csdn.net/pipisorry/article/details/48901217 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 海量数据挖掘MMDS week2: Association Rules关联规则与频繁项集挖掘
http://blog.csdn.net/pipisorry/article/details/48894977 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 手推FP-growth (频繁模式增长)算法------挖掘频繁项集
一.频繁项集挖掘为什么会出现FP-growth呢? 原因:这得从Apriori算法的原理说起,Apriori会产生大量候选项集(就是连接后产生的),在剪枝时,需要扫描整个数据库(就是给出的数据),通过 ...
- 关联分析中寻找频繁项集的FP-growth方法
关联分析是数据挖掘中常用的分析方法.一个常见的需求比如说寻找出经常一起出现的项目集合. 引入一个定义,项集的支持度(support),是指所有包含这个项集的集合在所有数据集中出现的比例. 规定一个最小 ...
- 挖掘频繁项集之FP-Growth算法
http://blog.csdn.net/pipisorry/article/details/48918007 FP-Growth频繁项集挖掘算法(Frequent-Pattern Growth, 频 ...
- 机器学习实战(Machine Learning in Action)学习笔记————08.使用FPgrowth算法来高效发现频繁项集
机器学习实战(Machine Learning in Action)学习笔记————08.使用FPgrowth算法来高效发现频繁项集 关键字:FPgrowth.频繁项集.条件FP树.非监督学习作者:米 ...
- 【Storm】Storm实战之频繁二项集挖掘
一.前言 针对大叔据实时处理的入门,除了使用WordCount示例之外,还需要相对更深入点的示例来理解Storm,因此,本篇博文利用Storm实现了频繁项集挖掘的案例,以方便更好的入门Storm. 二 ...
随机推荐
- Alluxio/Tachyon如何发挥lineage的作用?
在Spark的RDD中引入过lineage这一概念.指的是RDD之间的依赖.而Alluxio则使用lineage来表示文件之间的依赖.在代码层面,指的是fileID之间的依赖. 代码中的注释指出: * ...
- 深入浅出 JMS(二) - ActiveMQ 入门指南
深入浅出 JMS(二) - ActiveMQ 入门指南 上篇博文深入浅出 JMS(一) – JMS 基本概念,我们介绍了消息通信的规范JMS,这篇博文介绍一款开源的 JMS 具体实现-- Active ...
- Spring Boot集成Quartz注入Spring管理的类
摘要: 在Spring Boot中使用Quartz时,在JOB中一般需要引用Spring管理的Bean,通过定义Job Factory实现自动注入. Spring有自己的Schedule定时任务,在S ...
- [转载红鱼儿]Delphi实现微信开发(3)如何使用multipart/form-data格式上传文件
开始前,先看下要实现的微信接口,上传多媒体文件,这个接口是用Form表单形式上传的文件.对我来说,对http的Form表单一知半解,还好,查到这个资料,如果你也和我一样,必须看看这篇文章. 在xali ...
- 2018.06.30 BZOJ 2342: [Shoi2011]双倍回文(manacher)
2342: [Shoi2011]双倍回文 Time Limit: 10 Sec Memory Limit: 128 MB Description Input 输入分为两行,第一行为一个整数,表示字符串 ...
- hdu-1130(卡特兰数+大数乘法,除法模板)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1130 卡特兰数:https://blog.csdn.net/qq_33266889/article/d ...
- newton法分形图
方程:z^6-1=0; %f为求解的方程,df是导数,使用的时候用funchandler定义 %res是目标分辨率,iter是循环次数,(xc,yc)是图像的中心,xoom是放大倍数 %参数视自己需求 ...
- C语言中交换两个数值的方法
//方法1 int one = 1; int two = 2; int temp = 0; temp = one; one = two; two = temp; ...
- 如何用命令行将我的Phonegap环境更新到最新版本?
从npm安装的Phonegap(version > 3.0),更新命令如下 npm update -g phonegap 检查当前本机环境的最新版本 phonegap -v 检查npm的最新ph ...
- maven 学习:为什么要使用maven,maven使用过程中的一些参数
Maven是一个基于Java平台的项目构建工具. 设计的出发点: 在进行软件开发的过程中,无论什么项目,采用何种技术,使用何种编程语言,我们要重复相同的开发步骤:编码,编译,测试,生成文档,打包发布. ...