Ajax爬取豆瓣电影目录(Python)
下面的分析相当于一个框架,搞懂之后,对于类似的文字爬取,我们也可以实现。就算不能使用Ajax方法,我们也能够使用相同思想去爬取我们想要的数据。
豆瓣电影排行榜分析
首先我们打开网页的审查元素,选中Network==》XHR==》电影相关信息网页文件
筛选并比较以下数据(三个文件数据)
请求地址
Request URL:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0 Request URL:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20 Request URL:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=40
查询参数
type:movie
tag:热门
sort:recommend
page_limit:
page_start: type:movie
tag:热门
sort:recommend
page_limit:
page_start: type:movie
tag:热门
sort:recommend
page_limit:
page_start:
请求报头
Host:movie.douban.com
Referer:https://movie.douban.com/explore
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
X-Requested-With:XMLHttpRequest
通过比较请求地址和查询参数,得出
请求地址 = baseurl+type+tag+sort+page_limit+page_start baseurl:https://movie.douban.com/j/search_subjects?
type:固定为movie
tag:关键字,需要将utf-8转换为urlencode
sort:固定为recommend
page_limit:表示一页显示的电影数量,固定20
page_start:表示电影页数,从0开始,20为公差的递增函数
由此我们获取到了我们需要的数据,可以将爬虫分为三步
- 获取网页json格式代码
- 从代码中获取电影名和电影海报图片链接
- 将获得的图片命名为电影名
流程
准备工作
在函数外部定义伪装的请求报头
headers={
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/explore',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
获取json格式代码
def get_page(page):
#请求参数
params={
'type': 'movie',
'tag': '奥特曼',
'sort': 'recommend',
'page_limit': '',
'page_start': page,
}
#基本网页链接
base_url = 'https://movie.douban.com/j/search_subjects?'
#将基本网页链接与请求参数结合在一起
url = base_url + urlencode(params)
try:
#获取网页代码
resp = requests.get(url, headers=headers)
print(url)
#返回json数据格式代码
if 200 == resp.status_code:
print(resp.json())
return resp.json()
except requests.ConnectionError:
return None
筛选数据
通过观察电影列表代码文件的preview,进行数据筛选
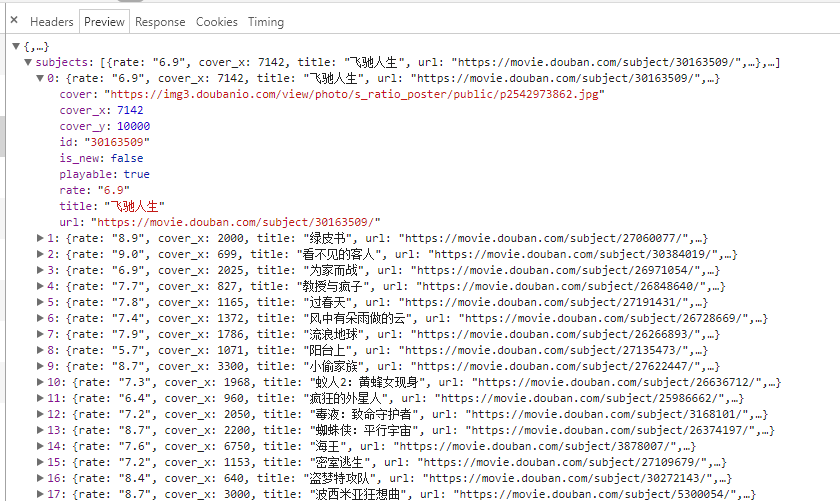
def get_image(json):
if(json.get('subjects')):
data=json.get('subjects')
for item in data:
title=item.get('title')
imageurl=item.get('cover')
#返回"信息"字典
yield {
'title':title,
'images':imageurl,
}
存储图片文件
def save_page(item):
#文件夹名称
file_name = '奥特曼电影大全'
if not os.path.exists(file_name):
os.makedirs(file_name) #获取图片链接
response=requests.get(item.get('images'))
#储存图片文件
if response.status_code==200:
file_path = file_name + os.path.sep + item.get('title') + '.jpg'
with open(file_path, 'wb') as f:
f.write(response.content)
多线程处理
def main(page):
json = get_page(page)
for item in get_image(json):
print(item)
save_page(item) if __name__ == '__main__':
pool = Pool()
pool.map(main, [i for i in range(0, 200, 20)])
pool.close()
pool.join()

总代码
import requests
from urllib.parse import urlencode
import os
from multiprocessing.pool import Pool headers={
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/explore',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
} def get_page(page):
#请求参数
params={
'type': 'movie',
'tag': '奥特曼',
'sort': 'recommend',
'page_limit': '',
'page_start': page,
}
#基本网页链接
base_url = 'https://movie.douban.com/j/search_subjects?'
#将基本网页链接与请求参数结合在一起
url = base_url + urlencode(params)
try:
#获取网页代码
resp = requests.get(url, headers=headers)
print(url)
#返回json数据格式代码
if 200 == resp.status_code:
print(resp.json())
return resp.json()
except requests.ConnectionError:
return None def get_image(json):
if(json.get('subjects')):
data=json.get('subjects')
for item in data:
title=item.get('title')
imageurl=item.get('cover')
#返回"信息"字典
yield {
'title':title,
'images':imageurl,
} def save_page(item):
#文件夹名称
file_name = '奥特曼电影大全'
if not os.path.exists(file_name):
os.makedirs(file_name) #获取图片链接
response=requests.get(item.get('images'))
#储存图片文件
if response.status_code==200:
file_path = file_name + os.path.sep + item.get('title') + '.jpg'
with open(file_path, 'wb') as f:
f.write(response.content) def main(page):
json = get_page(page)
for item in get_image(json):
print(item)
save_page(item) if __name__ == '__main__':
pool = Pool()
pool.map(main, [i for i in range(0, 200, 20)])
pool.close()
pool.join()
本来是准备使用https://movie.douban.com/tag/#/ 不过在后面,刷新网页时,总是出现服务器问题。不过下面的代码还是可以用。
import requests
from urllib.parse import urlencode
import os
from hashlib import md5
from multiprocessing.pool import Pool headers={
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/tag/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
} def get_page(page):
params={
'sort':'U',
'range':'0,10',
'tags':'奥特曼',
'start': page,
}
base_url = 'https://movie.douban.com/j/new_search_subjects?'
url = base_url + urlencode(params)
try:
resp = requests.get(url, headers=headers)
print(url)
if 200 == resp.status_code:
print(resp.json())
return resp.json()
except requests.ConnectionError:
return None def get_image(json):
if(json.get('data')):
data=json.get('data')
for item in data:
title=item.get('title')
imageurl=item.get('cover')
yield {
'title':title,
'images':imageurl,
} def save_page(item):
file_name='奥特曼大全'+os.path.sep+item.get('title')
if not os.path.exists(file_name):
os.makedirs(file_name)
try:
response=requests.get(item.get('images'))
if response.status_code==200:
file_path = '{0}/{1}.{2}'.format(file_name, md5(response.content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image') def main(page):
json = get_page(page)
for item in get_image(json):
print(item)
save_page(item) if __name__ == '__main__':
pool = Pool()
pool.map(main, [i for i in range(0, 200, 20)])
pool.close()
pool.join()
Ajax爬取豆瓣电影目录(Python)的更多相关文章
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
随机推荐
- RocketMQ集群部署安装
RcoketMQ:[ 1.低延时:在高压下,1毫秒内超过99.6%的反应延迟. 2.面向金融:具有跟踪和审计功能的高可用性. 3.行业可持续发展:保证了万亿级的消息容量. 4.厂商中立:一个新的开放的 ...
- nginx+flask+gevent+uwsgi实现websocket
Websocket简介 WebSocket是HTML5开始提供的一种在单个 TCP 连接上进行全双工通讯的协议.在WebSocket API中,浏览器和服务器只需要做一个握手的动作,然后,浏览器和服务 ...
- 如何查看Codeforces的GYM中比赛的数据
前置条件:黄名(rating >= 2100) 或者 紫名(rating >= 1900)并且打过30场计分的比赛. 开启:首先打开GYM的界面,如果符合要求会在右边展示出一个Coach ...
- 漫谈五种IO模型
阅读目录 1 基础知识回顾 2 I/O模式 3 事件驱动编程模型 网络编程里常听到阻塞IO.非阻塞IO.同步IO.异步IO等概念,搞清楚这些概念之前,还得先回顾一些基础的概念. 1 基础知识回顾 注意 ...
- 【串线篇】spring boot外部配置加载顺序
SpringBoot也可以从以下位置加载配置: 原则仍然是优先级从高到低:高优先级的配置覆盖低优先级的配置,所有的配置会形成互补配置 1.命令行参数 所有的配置都可以在命令行上进行指定 java -j ...
- JS原型链详解(2)
深入理解javascript原型链 在javascript中原型和原型链是一个很神奇的东西,对于大多数人也是最难理解的一部分,掌握原型和原型链的本质是javascript进阶的重要一环.今天我分享一下 ...
- RMQ Message ACK
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/11808680.html 消息持久化机制 消息丢失了,需要将队列持久化,即将autoDelete设置成f ...
- 用jquery实现图片轮播
用jquery简单实现图片轮播效果,代码如下: <!DOCTYPE html> <html lang="en"> <head> <meta ...
- [NOIP2016][luogu]换教室[DP]
[NOIP2016] Day1 T3 换教室 ——!x^n+y^n=z^n 题目描述 对于刚上大学的牛牛来说,他面临的第一个问题是如何根据实际情况申请合适的课程. 在可以选择的课程中,有 2n 节课程 ...
- 【テンプレート】LCA
LCA目前比较流行的算法主要有tarjian,倍增和树链剖分 1)tarjian 是一种离线算法,需要提前知道所有询问对 算法如下 1.读入所有询问对(u,v),并建好树(建议邻接表) 2.初始化每个 ...