python之Beautiful Soup库
1、简介
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
2、环境安装
Beautiful Soup 3 目前已经停止开发,推荐在现在的项目中使用Beautiful Soup 4,不过它已经被移植到BS4了,也就是说导入时我们需要 from bs4 import BeautifulSoup 。所以这里我们用的版本是 Beautiful Soup 4.3.2 (简称BS4)。
1、快速安装
|
1
|
pip install beautifulsoup4 |
2、如果想安装最新的版本,请直接下载安装包来手动安装,也是十分方便的方法
1、Beautiful Soup3.2.1
https://pypi.python.org/pypi/BeautifulSoup/3.2.1
2、Beautiful Soup4.3.2
https://pypi.python.org/pypi/beautifulsoup4/
下载完成之后解压
运行下面的命令即可完成安装
python setup.py install
3、然后需要安装 lxml
pip install lxml
另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:
pip install html5lib
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
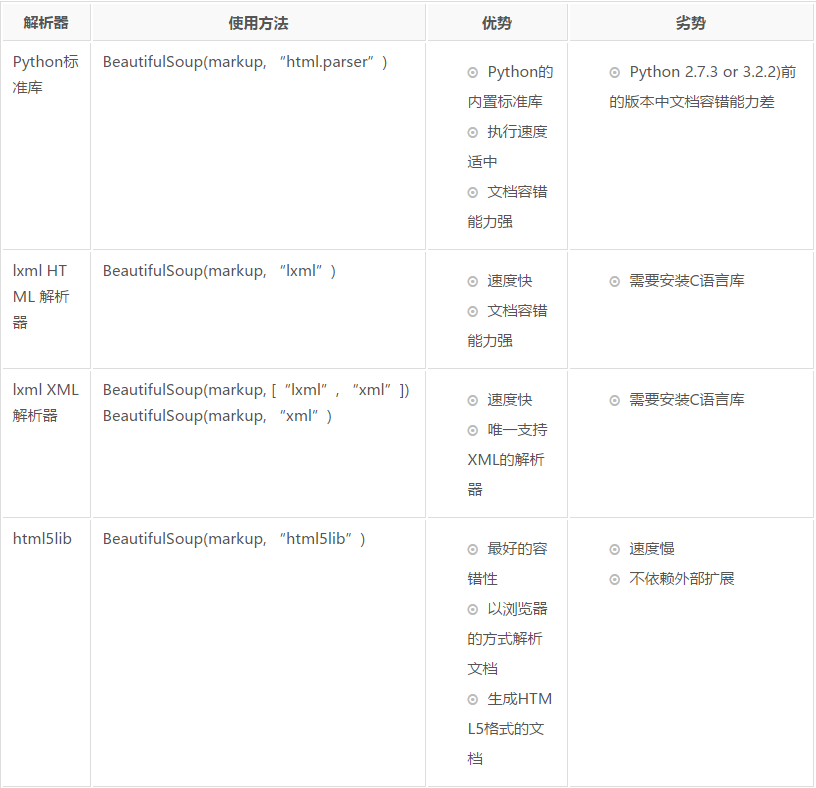
3. 使用方法
最佳方法参考官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
以下内容测试css和xpath分别提取文本和属性的区别,方便后续查看
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
from bs4 import BeautifulSoup as bs body = '''<html>
<head>
<base href='http://example.com/' />
<title id="txt">Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: My image <br /><img src='image1_thumb.jpg' /></a>
<a href='image2.html'>Name: My image <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html'>Name: My image <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html'>Name: My image <br /><img src='image5_thumb.jpg' /></a>"div text"</div>
<div>helloworld test</div>
</body>
</html>'''
soup = bs(body, "lxml")
print("css获取属性:",soup.select("div")[].attrs["id"])
print("xpath获取属性:",Selector(text=body).xpath("//div/@id").extract()[]) print("css获取文本:", soup.select("title[id='txt']")[].string)
print("xpath获取文本:",Selector(text=body).xpath("//title[@id='txt']/text()").extract()[])
python之Beautiful Soup库的更多相关文章
- Python Beautiful Soup库
Beautiful Soup库 Beautiful Soup库:https://www.crummy.com/software/BeautifulSoup/ 安装Beautiful Soup: 使用B ...
- Beautiful Soup库基础用法(爬虫)
初识Beautiful Soup 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/# 中文文档:https://www.crumm ...
- 【转载】Beautiful Soup库(bs4)入门
转载自:Beautiful Soup库(bs4)入门 该库能够解析HTML和XML 使用Beautiful Soup库: from bs4 import BeautifulSoup impo ...
- Beautiful Soup库入门
1.安装:pip install beautifulsoup4 Beautiful Soup库是解析.遍历.维护“标签树”的功能库 2.引用:(1)from bs4 import BeautifulS ...
- python beautiful soup库的超详细用法
原文地址https://blog.csdn.net/love666666shen/article/details/77512353 参考文章https://cuiqingcai.com/1319.ht ...
- 【Python爬虫学习笔记(3)】Beautiful Soup库相关知识点总结
1. Beautiful Soup简介 Beautiful Soup是将数据从HTML和XML文件中解析出来的一个python库,它能够提供一种符合习惯的方法去遍历搜索和修改解析树,这将大大减 ...
- crawler碎碎念4 关于python requests、Beautiful Soup库、SQLlite的基本操作
Requests import requests from PIL import Image from io improt BytesTO import jason url = "..... ...
- Python之Beautiful Soup的用法
1. Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- Python的Beautiful Soup简单使用
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据 Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能 它是一个工具箱, ...
随机推荐
- hadoop22---wait,notify
vv wait和notify,是要加syschronized的,是要获取锁的,wait是释放控制权,别的线程就可以执行了,notify和notifyall是通知其他线程执行.
- What is CRC and how does it works?
What is CRC and how does it works? CRC errors refer to Layer 1 or 2 issues. Two things you should ch ...
- 阻塞方法与InterruptedException
什么是阻塞方法?为什么会抛出InterruptedException? 一般方法的完成只取决于它所要做的事情,以及是否有足够多可用的计算资源(CPU 周期和内存). 而阻塞方法的完成还取决于一些外部的 ...
- ARM协处理器CP15寄存器详解【转】
本文转载i自;https://blog.csdn.net/gameit/article/details/13169405 用于系统存储管理的协处理器CP15 MCR{cond} copro ...
- [转载]织梦DEDE多选项筛选_联动筛选功能的实现_二次开发
织梦默认的列表页没有筛选功能,但有时候我们做产品列表页的时候,产品的字段比较多,很多人都需要用到筛选功能,这样可以让用户更方便的找到自己所需要的东西,实现这个联动筛选功能需要对织梦进行二次开发,下面就 ...
- Java 获取路径的几种方法 - 转载
1.获取当前类所在的“项目名路径” String rootPath = System.getProperty("user.dir"); 2.获取编译文件“jar包路径”(反射) S ...
- 深入理解SELECT ... LOCK IN SHARE MODE和SELECT ... FOR UPDATE
概念和区别 SELECT ... LOCK IN SHARE MODE走的是IS锁(意向共享锁),即在符合条件的rows上都加了共享锁,这样的话,其他session可以读取这些记录,也可以继续添加IS ...
- C语言中单引号和双引号
写惯了python对单引号和双引号都混了.. C语言中的单引号和双引号含义迥异,用单引号引起的一个字符实际上代表一个整数,整数值对应于该字符在编译器采用的字符集中的序列值,因此,采用ASCII字符集的 ...
- Memcached 连接
我们可以通过 telnet 命令并指定主机ip和端口来连接 Memcached 服务. 语法 telnet HOST PORT 命令中的 HOST 和 PORT 为运行 Memcached 服务的 I ...
- JNIjw05
ZC: 这个代码,没有真正的运行测试 1.VC6(CPP)的DLL代码: #include<stdio.h> #include "jniZ_JNIjw05.h" #in ...