Pandas 文本数据
Pandas针对字符串配备的一套方法,使其易于对数组的每个元素(字符串)进行操作。
1.通过str访问,且自动排除丢失/ NA值
# 通过str访问,且自动排除丢失/ NA值 s = pd.Series(['A','b','C','bbhello','',np.nan,'hj'])
df = pd.DataFrame({'key1':list('abcdef'),
'key2':['hee','fv','w','hija','',np.nan]})
print(s)
print(df)
print('-----') print(s.str.count('b')) #对字符b进行计数
print(df['key2'].str.upper()) #upper全部变成大写
print('-----')
# 直接通过.str调用字符串方法
# 可以对Series、Dataframe使用
# 自动过滤NaN值 df.columns = df.columns.str.upper() #把所有的列名变为大写的。
print(df)
# df.columns是一个Index对象,也可使用.str
输出结果:
0 A
1 b
2 C
3 bbhello
4 123
5 NaN
6 hj
dtype: object
key1 key2
0 a hee
1 b fv
2 c w
3 d hija
4 e 123
5 f NaN
-----
0 0.0
1 1.0
2 0.0
3 2.0
4 0.0
5 NaN
6 0.0
dtype: float64
0 HEE
1 FV
2 W
3 HIJA
4 123
5 NaN
Name: key2, dtype: object
-----
KEY1 KEY2
0 a hee
1 b fv
2 c w
3 d hija
4 e 123
5 f NaN
2.字符串常用方法(1) - lower,upper,len,startswith,endswith
s = pd.Series(['A','b','bbhello','',np.nan]) print(s.str.lower(),'→ lower小写\n')
print(s.str.upper(),'→ upper大写\n')
print(s.str.len(),'→ len字符长度\n')
print(s.str.startswith('b'),'→ 判断起始是否为b\n')
print(s.str.endswith(''),'→ 判断结束是否为3\n')
输出结果:
0 a
1 b
2 bbhello
3 123
4 NaN
dtype: object → lower小写 0 A
1 B
2 BBHELLO
3 123
4 NaN
dtype: object → upper大写 0 1.0
1 1.0
2 7.0
3 3.0
4 NaN
dtype: float64 → len字符长度 0 False
1 True
2 True
3 False
4 NaN
dtype: object → 判断起始是否为b 0 False
1 False
2 False
3 True
4 NaN
dtype: object → 判断结束是否为3
3.字符串常用方法(2) - strip
s = pd.Series([' jack', 'jill ', ' jesse ', 'frank'])
df = pd.DataFrame(np.random.randn(3, 2), columns=[' Column A ', ' Column B '],
index=range(3))
print(s)
print(df)
print('-----') print(s.str.strip()) #去除前后的空格
print(s.str.lstrip()) # 去除字符串中的左空格
print(s.str.rstrip()) # 去除字符串中的右空格 df.columns = df.columns.str.strip()
print(df)
# 这里去掉了columns的前后空格,但没有去掉中间空格
输出结果:
0 jack
1 jill
2 jesse
3 frank
dtype: object
Column A Column B
0 -1.110964 -0.607590
1 2.043887 0.713886
2 0.840672 -0.854777
-----
0 jack
1 jill
2 jesse
3 frank
dtype: object
0 jack
1 jill
2 jesse
3 frank
dtype: object
0 jack
1 jill
2 jesse
3 frank
dtype: object
Column A Column B
0 -1.110964 -0.607590
1 2.043887 0.713886
2 0.840672 -0.854777
4.字符串常用方法(3) - replace
df = pd.DataFrame(np.random.randn(3, 2), columns=[' Column A ', ' Column B '],
index=range(3))
df.columns = df.columns.str.replace(' ','-')
print(df)
# 替换 df.columns = df.columns.str.replace('-','hehe',n=1)
print(df)
# n:替换个数
输出结果:
df = pd.DataFrame(np.random.randn(3, 2), columns=[' Column A ', ' Column B '],
index=range(3))
df.columns = df.columns.str.replace(' ','-')
print(df)
# 替换 df.columns = df.columns.str.replace('-','hehe',n=1)
print(df)
# n:替换个数
5.(1)字符串常用方法(4) - split、rsplit
s = pd.Series(['a,b,c','1,2,3',['a,,,c'],np.nan])
print(s,'\n')
print(s.str.split(','))
print('1-----','\n')
# 类似字符串的split print(s.str.split(',')[0])
print('2-----','\n')
# 直接索引得到一个list print(s.str.split(',').str[0])
print('3-----','\n')
print(s.str.split(',').str.get(1))
print('4-----','\n')
# 可以使用get或[]符号访问拆分列表中的元素 print(s.str.split(',', expand=True))
print('5-----','\n')
print(s.str.split(',', expand=True, n = 1))
print('6-----','\n')
print(s.str.rsplit(',', expand=True, n = 1))
print('7-----','\n')
# 可以使用expand可以轻松扩展此操作以返回DataFrame
# n参数限制分割数
# rsplit类似于split,反向工作,即从字符串的末尾到字符串的开头 df = pd.DataFrame({'key1':['a,b,c','1,2,3',[':,., ']],
'key2':['a-b-c','1-2-3',[':-.- ']]})
print(df,'\n8-----\n')
print(df['key2'].str.split('-'))
# Dataframe使用split
输出结果:
0 a,b,c
1 1,2,3
2 [a,,,c]
3 NaN
dtype: object 0 [a, b, c]
1 [1, 2, 3]
2 NaN
3 NaN
dtype: object
1----- ['a', 'b', 'c']
2----- 0 a
1 1
2 NaN
3 NaN
dtype: object
3----- 0 b
1 2
2 NaN
3 NaN
dtype: object
4----- 0 1 2
0 a b c
1 1 2 3
2 NaN None None
3 NaN None None
5----- 0 1
0 a b,c
1 1 2,3
2 NaN None
3 NaN None
6----- 0 1
0 a,b c
1 1,2 3
2 NaN None
3 NaN None
7----- key1 key2
0 a,b,c a-b-c
1 1,2,3 1-2-3
2 [:,., ] [:-.- ]
8----- 0 [a, b, c]
1 [1, 2, 3]
2 NaN
Name: key2, dtype: object
5.(2)
df = pd.DataFrame({'key1':['a,b,c','1,2,3',[':,., ']],
'key2':['a-b-c','1-2-3',[':-.- ']]})
print(df,'\n8-----\n')
print(df['key2'].str.split('-'),'\n')
print(df['key2'].str.split('-',expand = True))
df['k201'] = df['key2'].str.split('-').str[0]
print('\n')
print(df['k201'])
df['k202'] = df['key2'].str.split('-').str[1]
df['k203'] = df['key2'].str.split('-').str[2]
df
输出结果:
key1 key2
0 a,b,c a-b-c
1 1,2,3 1-2-3
2 [:,., ] [:-.- ]
8----- 0 [a, b, c]
1 [1, 2, 3]
2 NaN
Name: key2, dtype: object 0 1 2
0 a b c
1 1 2 3
2 NaN None None 0 a
1 1
2 NaN
Name: k201, dtype: object

6.(1)字符串索引
# 字符串索引 s = pd.Series(['A','b','C','bbhello','',np.nan,'hj'])
df = pd.DataFrame({'key1':list('abcdef'),
'key2':['hee','fv','w','hija','',np.nan]}) print(s,'\n')
print(s.str[0],'\n') # 取第一个字符串
print(s.str[:2],'\n') # 取前两个字符串
print(df,'\n')
print(df['key2'].str[0])
# str之后和字符串本身索引方式相同
输出结果:
0 A
1 b
2 C
3 bbhello
4 123
5 NaN
6 hj
dtype: object 0 A
1 b
2 C
3 b
4 1
5 NaN
6 h
dtype: object 0 A
1 b
2 C
3 bb
4 12
5 NaN
6 hj
dtype: object key1 key2
0 a hee
1 b fv
2 c w
3 d hija
4 e 123
5 f NaN 0 h
1 f
2 w
3 h
4 1
5 NaN
Name: key2, dtype: object
6.(2)
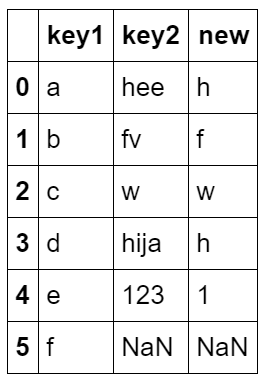
df = pd.DataFrame({'key1':list('abcdef'),
'key2':['hee','fv','w','hija','',np.nan]})
df['new'] = df['key2'].str[0]
df
输出结果:
练习题:
作业1:如图创建一个Dataframe,并分别通过字符串常用方法得到3个Series或得到新的Dataframe:
① name字段首字母全部大写
② gender字段去除所有空格
③ score字段按照-拆分,分别是math,english,art三个学分

import numpy as np
import pandas as pd df = pd.DataFrame({'gender':['M ',' M',' F ',' M ',' F'],
'Name':['jack','tom','marry','zack','heheda'],
'score':['90-90-90','89-89-89','90-90-90','78-78-78','60-60-60']})
print(df,'\n')
df['Name'] = df['Name'].str.capitalize() #首字母大写
print(df,'\n')
df['Name'] = df['Name'].str.upper() #全部大写
print(df,'\n') df['gender'] = df['gender'].str.strip() #去掉所有空格
print(df,'\n') df['Math'] = df['score'].str.split('-').str[0]
df['English'] = df['score'].str.split('-').str[1]
df['Art'] = df['score'].str.split('-').str[2]
print(df,'\n')
print(df['Math'].dtype) #字符串类型
#改为整型
df['Math'] = df['Math'].astype(np.int)
print(df['Math'].dtype) #整型
输出结果:
Name gender score
0 jack M 90-90-90
1 tom M 89-89-89
2 marry F 90-90-90
3 zack M 78-78-78
4 heheda F 60-60-60 Name gender score
0 Jack M 90-90-90
1 Tom M 89-89-89
2 Marry F 90-90-90
3 Zack M 78-78-78
4 Heheda F 60-60-60 Name gender score
0 JACK M 90-90-90
1 TOM M 89-89-89
2 MARRY F 90-90-90
3 ZACK M 78-78-78
4 HEHEDA F 60-60-60 Name gender score
0 JACK M 90-90-90
1 TOM M 89-89-89
2 MARRY F 90-90-90
3 ZACK M 78-78-78
4 HEHEDA F 60-60-60 Name gender score Math English Art
0 JACK M 90-90-90 90 90 90
1 TOM M 89-89-89 89 89 89
2 MARRY F 90-90-90 90 90 90
3 ZACK M 78-78-78 78 78 78
4 HEHEDA F 60-60-60 60 60 60 object
int32
Pandas 文本数据的更多相关文章
- Python文本数据互相转换(pandas and win32com)
(工作之后,就让自己的身心都去休息吧) 今天介绍一下文本数据的提取和转换,这里主要实例的转换为excel文件(.xlsx)转换world文件(.doc/docx),同时需要使用win32api,同py ...
- pandas处理大文本数据
当数据文件是百万级数据时,设置chunksize来分批次处理数据 案例:美国总统竞选时的数据分析 读取数据 import numpy as np import pandas as pdfrom pan ...
- 如何使用 scikit-learn 为机器学习准备文本数据
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 文本数据需要特殊处理,然后才能开始将其用于预测建模. 我们需要解析文本,以删除被称为标记化的单词.然后,这些词还需要被编码为整型或浮点型,以用作 ...
- 机器学习入门-文本数据-构造词频词袋模型 1.re.sub(进行字符串的替换) 2.nltk.corpus.stopwords.words(获得停用词表) 3.nltk.WordPunctTokenizer(对字符串进行分词操作) 4.np.vectorize(对函数进行向量化) 5. CountVectorizer(构建词频的词袋模型)
函数说明: 1. re.sub(r'[^a-zA-Z0-9\s]', repl='', sting=string) 用于进行字符串的替换,这里我们用来去除标点符号 参数说明:r'[^a-zA-Z0- ...
- pynlpir + pandas 文本分析
pynlpir是中科院发布的一个分词系统,pandas(Python Data Analysis Library) 是python中一个常用的用来进行数据分析和统计的库,利用这两个库能够对中文文本数据 ...
- Pandas中数据的处理
有两种丢失数据 ——None ——np.nan(NaN) None是python自带的,其类型为python object.因此,None不能参与到任何计算中 Object类型的运算比int类型的运算 ...
- Pandas文本数据处理
先初始化数据 import pandas as pd import numpy as np index = pd.Index(data=["Tom", "Bob" ...
- 【tensorflow2.0】处理文本数据
一,准备数据 imdb数据集的目标是根据电影评论的文本内容预测评论的情感标签. 训练集有20000条电影评论文本,测试集有5000条电影评论文本,其中正面评论和负面评论都各占一半. 文本数据预处理较为 ...
- Bulk Insert:将文本数据(csv和txt)导入到数据库中
将文本数据导入到数据库中的方法有很多,将文本格式(csv和txt)导入到SQL Server中,bulk insert是最简单的实现方法 1,bulk insert命令,经过简化如下 BULK INS ...
随机推荐
- vue-样式问题
问题: 今天在用vue开发单页面应用的时候,遇到一个问题,在A页面,直接刷新,页面的布局样式之类的是没有问题的,不过在B页面跳转到A页面,那么A页面有一些样式就不是预期的效果. 发现解决问题: 用调试 ...
- HTTP杂记
HTTP请求中的浏览器Timing信息: stalled:浏览器发出请求到这个请求可以发出的等待时间 proxy negotiation: 代理协商的时间 request sent:请求的第一个字节发 ...
- Form上传编译
编译上传的Form,使用命令: 在R12服务器上: cd $AU_TOP/forms/US frmcmp_batch module=$CUX_TOP/forms/ZHS/XXX.fmbuserid=a ...
- Android基础Activity篇——销毁活动
销毁活动只需要添加 finish(); 这个方法即可.相当于back键.
- u-boot分析(八)----串口初始化
u-boot分析(八) 上篇博文我们按照210的启动流程,分析到了内存初始化,今天我们继续按照u-boot的启动流程对串口的初始化进行分析. 今天我们会用到的文档: 1. 2440芯片手 ...
- SQLServer 连接和联合
一.内连接(inner join) 默认省略inner ,内连接是严格过滤,等同where限制,连接两端的表都数据都需要过滤. 二.左外连接(left outer join) 以左表为基准进行数据连接 ...
- 如何用C# 动态创建Access数据库和表?
记得以前要动态的创建Access数据库的mdb文件都是采用DAO,用VC开发,一大堆的API,很是麻烦.而且以前工作中需要全新的access数据库,可以复制数据库,也可以把新的数据库放到资源里面,用新 ...
- react+webpack 引入字体图标
在使用react+webpack 构建项目过程中免不了要用到字体图标,在引入过程中报错,不能识别字体图标文件中的@符,报错 Uncaught Error: Module parse failed: U ...
- zendstudio 汉化
http://archive.eclipse.org/technology/babel/index.php http://www.eclipse.org/babel/downloads.php 注册码 ...
- IOS GCD03-其他用法
#define global_queue dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0) #define main_queu ...