【转帖】训练中文LLaMA大规模语言模型
https://zhuanlan.zhihu.com/p/612752963?utm_id=0
最近,FacebookResearch 开源了他们最新的大规模语言模型 LLaMA,包含从 7B 到 65B 的参数范围,训练使用多达 14,000 亿 tokens 语料。其中,LLaMA-13B 在大部分基准测评上超过了 GPT3(175B),与目前最强的语言模型 Chinchilla-70B 和 PaLM-540B 相比,LLaMA-65B 也具有竞争力。因此,LLaMA 可能是目前公开模型权重中效果最好的语言模型。
论文:https://arxiv.org/abs/2302.13971
代码:https://github.com/facebookresearch/llama

在论文中,作者针对常识推理、问答、数学推理、代码生成、语言理解等能力对 LLaMA 进行了评测。结果显示,LLaMA 以相对少量的参数获得了媲美超大模型的效果,这对 NLP 社区的研究者们更加友好,因为它可以在单个 GPU 上运行。开源代码提供 LLaMA 的文本生成示例,可以直接用于一些 Zero/Few-Shot Learning 任务。也有许多用户关心如何使用自己的数据微调或增量训练LLaMA模型,然而Facebook目前还没有提供对应的训练代码。在本文中,我们介绍如何基于 TencentPretrain 预训练框架训练 LLaMA 模型。
TencentPretrain 是 UER-py 预训练框架的多模态版本,支持 BERT、GPT、T5、ViT、Dall-E、Speech2Text 等模型,支持文本、图像和语音模态预训练及下游任务。TencentPretrain 基于模块化设计,用户可以通过模块组合的方式构成各种模型,也可以通过复用已有的模块进行少量修改来实现新的模型。例如,LLaMA 的模型架构基于 Transformer 有三项改动:
- 前置 normalization [GPT3]: 在每个 transformer 层输入之前进行标准化,以提高训练稳定性。标准化层使用RMSNorm。
- SwiGLU 激活函数[PaLM]:在 Feedforward 层使用 Gated Linear Units [T5] 以及 SwiGLU 激活函数。
- 旋转位置编码[GPTNeo]:移除了 Embedding 层的绝对位置编码,并在每个 transformer 层增加旋转位置编码(RoPE)。
得益于模块化特性,我们在 TencentPretrain 中基于 GPT2 模型的已有模块,仅添加约 100 行代码就能实现以上三个改动从而训练 LLaMA 模型。具体的使用步骤为:
- 克隆 TencentPretrain 项目,并安装依赖:PyTorch、DeepSpeed、SentencePiece
git clone https://github.com/Tencent/TencentPretrain.git2. 下载 LLaMA 模型权重(7B),可以向 FacebookResearch 申请模型,或者从 Huggingface 社区获取;将模型权重转换为 TencentPretrain 格式
cd TencentPretrain
python3 scripts/convert_llama_to_tencentpretrain.py --input_model_path $LLaMA_7B_FOLDER/consolidated.00.pth --output_model_path models/llama-7b.bin --layers_num 323. 调整配置文件
将 tencentpretrain/utils/constants.py 文件中 L4: special_tokens_map.json 修改为 llama_special_tokens_map.json
4. 语料预处理:使用项目自带的语料作为演示,也可以使用相同格式的语料进行替换
python3 preprocess.py --corpus_path corpora/book_review.txt --spm_model_path $LLaMA_7B_FOLDER/tokenizer.model \
--dataset_path dataset.pt --processes_num 8 --data_processor lm5. 启动训练,以8卡为例
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_config.json \
--pretrained_model_path models/llama-7b.bin \
--dataset_path dataset.pt --spm_model_path $LLaMA_7B_FOLDER/tokenizer.model \
--config_path models/llama/7b_config.json \
--output_model_path models/output_model.bin \
--world_size 8 --learning_rate 1e-4 \
--data_processor lm --total_steps 10000 --save_checkpoint_steps 2000 --batch_size 24启动训练后,可以看到模型的 loss 和准确率:
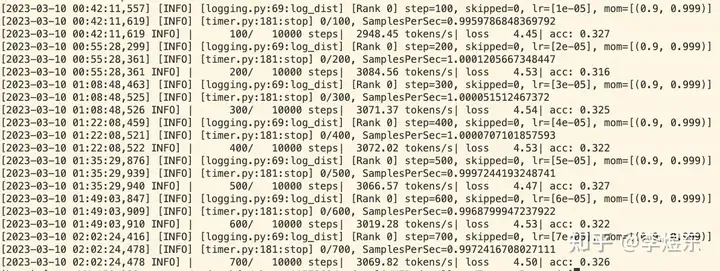
模型推理
类似 facebookresearch/llama ,TencentPretrain 也提供语言模型推理代码。例如,使用单卡进行 LLaMA-7B 推理,prompt 在文件beginning.txt 中:
python3 scripts/generate_lm.py --load_model_path models/llama-7b.bin --spm_model_path $LLaMA_7B_FOLDER/tokenizer.model \
--test_path beginning.txt --prediction_path generated_sentence.txt \
--config_path models/llama/7b_config.json 开源的 LLaMA 模型在预训练阶段主要基于英语训练,也具有一定的多语言能力,然而由于它没有将中文语料加入预训练,LLaMA在中文上的效果很弱。利用 TencentPretrain 框架,用户可以使用中文语料增强 LLaMA 的中文能力,也可以将它微调成垂直领域模型。
目前,TencentPretrain 只支持 LLaMA-7B 训练,我们将会持续改进以支持所有规模的 LLaMA 模型训练/微调并分享更多实验结果。欢迎大家分享使用 TencentPretrain 训练的模型权重或提交 Pull Request 贡献代码。
其他预训练模型权重例如中文 BERT、GPT、T5 等可以在我们的 Model Zoo 或者 Huggingface 仓库下载。
更新:LLaMA中文权重以及对话模型
【转帖】训练中文LLaMA大规模语言模型的更多相关文章
- 使用 DL4J 训练中文词向量
目录 使用 DL4J 训练中文词向量 1 预处理 2 训练 3 调用 附录 - maven 依赖 使用 DL4J 训练中文词向量 1 预处理 对中文语料的预处理,主要包括:分词.去停用词以及一些根据实 ...
- Tesseract训练中文字体识别
注:目前仅说明windows下的情况 前言 网上已经有大量的tesseract的识别教程,但是主要有两个缺点: 大多数比较老,有部分内容已经不适用. 大部分只是就英文的训练进行探索,很少针对中文的训练 ...
- 使用word2vec训练中文词向量
https://www.jianshu.com/p/87798bccee48 一.文本处理流程 通常我们文本处理流程如下: 1 对文本数据进行预处理:数据预处理,包括简繁体转换,去除xml符号,将单词 ...
- word2vec训练中文模型
-- 这篇文章是一个学习.分析的博客 --- 1.准备数据与预处理 首先需要一份比较大的中文语料数据,可以考虑中文的维基百科(也可以试试搜狗的新闻语料库).中文维基百科的打包文件地址为 https: ...
- Windows下基于python3使用word2vec训练中文维基百科语料(二)
在上一篇对中文维基百科语料处理将其转换成.txt的文本文档的基础上,我们要将为文本转换成向量,首先都要对文本进行预处理 步骤四:由于得到的中文维基百科中有许多繁体字,所以我们现在就是将繁体字转换成简体 ...
- tesserat训练中文备忘录
最近用OCR识别身份证,用的tesseract引擎.但是google自带的中文库是在太慢了,尤其是对于性别.民族这样结果可以穷举的特征信息而言,完全可以自己训练字库.自己训练字库不仅可以提高识别速度, ...
- [转帖]Linux内核为大规模支持100Gb/s网卡准备好了吗?并没有
Linux内核为大规模支持100Gb/s网卡准备好了吗?并没有 之前用 千兆的机器 下载速度 一般只能到 50MB 左右 没法更高 万兆的话 可能也就是 200MB左右的速度 很难更高 不知道后续的服 ...
- Windows下基于python3使用word2vec训练中文维基百科语料(一)
在进行自然语言处理之前,首先需要一个语料,这里选择维基百科中文语料,由于维基百科是 .xml.bz2文件,所以要将其转换成.txt文件,下面就是相关步骤: 步骤一:下载维基百科中文语料 https:/ ...
- Windows下基于python3使用word2vec训练中文维基百科语料(三)
对前两篇获取到的词向量模型进行使用: 代码如下: import gensim model = gensim.models.Word2Vec.load('wiki.zh.text.model') fla ...
- 预训练语言模型整理(ELMo/GPT/BERT...)
目录 简介 预训练任务简介 自回归语言模型 自编码语言模型 预训练模型的简介与对比 ELMo 细节 ELMo的下游使用 GPT/GPT2 GPT 细节 微调 GPT2 优缺点 BERT BERT的预训 ...
随机推荐
- picker组件增加搜索item条目的功能
picker组件顶部有搜索框,能搜索条目,如果条目很多的时候,上下翻很麻烦了,而且不容易找到,可以先全查,然后js搜索 wxml <button bindtap="openFlag&q ...
- 让 Java 打包缩小一大半,Solon v1.9.3 发布
相对于 Spring Boot 和 Spring Cloud 的项目: 启动快 5 - 10 倍. (更快) qps 高 2- 3 倍. (更高) 运行时内存节省 1/3 ~ 1/2. (更少) 打包 ...
- MAC zsh:no matches found
jimmy@MacBook-Pro bin % wsdl2java http://www.webxml.com.cn/WebServices/IpAddressSearchWebService.asm ...
- GDB变量值显示为< optimized_out >的解决方法
GDB调试显示< optimized_out > 最近使用GDB调试的时候,经常遇到GDB查看变量值的时候输出< optimized_out >,Google了一下,找到几个解 ...
- 获取标准报表CJI3的ALV数据
1.CJI3 运行标准程序CJI3,获取对象和业务货币值,在其他程序中展示 2.代码展示 CJI3对应程序名rkpep003,最终展示的ALV结构可以再程序中找到. 因为本实例只获取其中两个字段的值, ...
- C# 实用第三方库
C# 实用第三方库 Autofac 依赖注入IOC框架 NuGet安装:Autofac.Autofac.Extras.DynamicProxy AutoMapper 对象映射 Mapster 对象映射 ...
- LaTex常用数学符号整理
在论文和博客的写作中,经常会用到Latex的语法来书写数学公式,一份详细的数学符号对照表必不可少,本文重写了部分 Markdown 公式指导手册 . 在线Latex公式编辑器 -1.求和积分的上下标位 ...
- Codeforces Round #620 (Div. 2) (A~D)
比赛链接:Here A题挺水的就不写了 1304B - Longest Palindrome 题意: 输入 \(m\) 个长度为 \(n\) 的字符串,问这些字符串能组成的最长回文串有多长. 思路: ...
- Codeforces Round #658 (Div. 2)
A.Common Subsequence 题意 给你两组数,问你有没有相同 的书,有的话,输出最短的那组(大家都知道,1是最小的) AC #include<bits/stdc++.h> ...
- 活动回顾|阿里云 Serverless 技术实战与创新上海站回放&PPT下载
5月27日"阿里云 Serverless 技术实战与创新"上海站圆满落幕.活动现场邀请了来自阿里云 一线技术专家,分享当前 Serverless 趋势和落地实践过程中的挑战和机遇: ...