"多层感知器"--MLP神经网络算法
提到人工智能(Artificial Intelligence,AI),大家都不会陌生,在现今行业领起风潮,各行各业无不趋之若鹜,作为技术使用者,到底什么是AI,我们要有自己的理解.
目前,在人工智能中,无可争议的是深度学习占据了统治地位,,其在图像识别,语音识别,自然语言处理,无人驾驶领域应用广泛.
如此,我们要如何使用这门技术呢?下面我们来一起了解"多层感知器",即MLP算法,泛称为神经网络.
神经网络顾名思义,就像我们人脑中的神经元一样,为了让机器来模拟人脑,我们在算法中设置一个个节点,在训练模型时,输入的特征与预测的结果用节点来表示,系数w(又称为"权重")用来连接节点,神经网络模型的学习就是一个调整权重的过程,训练模型一步步达到我们想要的效果.
理解了原理,下面来上代码直观看一下:
1.神经网络中的非线性矫正
每个输入数据与输出数据之间都有一个或多个隐藏层,每个隐藏层包含多个隐藏单元.
在输入数据和隐藏单元之间或隐藏单元和输出数据之间都有一个系数(权重).
计算一系列的加权求和和计算单一的加权求和和普通的线性模型差不多.
线性模型的一般公式:
y = w[0]▪x[0]+w[1]▪x[1] + ▪▪▪ + w[p]▪x[p] + b
为了使得模型比普通线性模型更强大,所以我们要进行一些处理,即非线性矫正(rectifying nonlinearity),简称为(rectified linear unit,relu).或是进行双曲正切处理(tangens hyperbolicus,tanh)
############################# 神经网络中的非线性矫正 #######################################
#导入numpy
import numpy as np
#导入画图工具
import matplotlib.pyplot as plt
#导入numpy
import numpy as py
#导入画图工具
import matplotlib.pyplot as plt #生成一个等差数列
line = np.linspace(-5,5,200)
#画出非线性矫正的图形表示
plt.plot(line,np.tanh(line),label='tanh')
plt.plot(line,np.maximum(line,0),label='relu') #设置图注位置
plt.legend(loc='best')
#设置横纵轴标题
plt.xlabel('x')
plt.ylabel('relu(x) and tanh(x)')
#显示图形
plt.show()
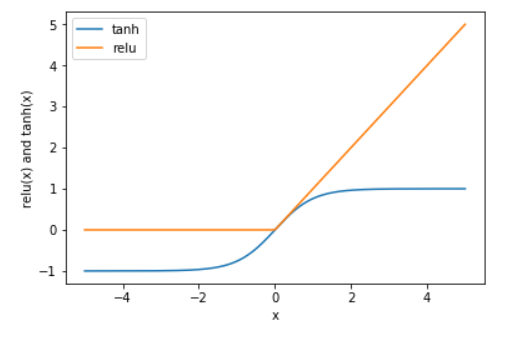
- tanh函数吧特征X的值压缩进-1到1的区间内,-1代表的是X中较小的数值,而1代表X中较大的数值.
- relu函数把小于0的X值全部去掉,用0来代替
2.神经网络的参数设置
#导入MLP神经网络
from sklearn.neural_network import MLPClassifier
#导入红酒数据集
from sklearn.datasets import load_wine
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
wine = load_wine()
X = wine.data[:,:2]
y = wine.target
#下面我们拆分数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=0)
#接下来定义分类器
mlp = MLPClassifier(solver='lbfgs')
mlp.fit(X_train,y_train)
MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_iter=200, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=None, shuffle=True, solver='lbfgs', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False)
- identity对样本特征不做处理,返回值是f(x) = x
- logistic返回的结果会是f(x)=1/[1 + exp(-x)],其和tanh类似,但是经过处理后的特征值会在0和1之间
#导入画图工具
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap #定义图像中分区的颜色和散点的颜色
cmap_light = ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000','#00FF00','#0000FF']) #分别用样本的两个特征值创建图像和横轴和纵轴
x_min,x_max = X_train[:, 0].min() - 1,X_train[:, 0].max() + 1
y_min,y_max = X_train[:, 1].min() - 1,X_train[:, 1].max() + 1 xx,yy = np.meshgrid(np.arange(x_min,x_max, .02),np.arange(y_min,y_max, .02))
Z = mlp.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light) #用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,edgecolor='k',s=60)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("MLPClassifier:solver=lbfgs")
plt.show()

(1)设置隐藏层中节点数为10
#设置隐藏层中节点数为10
mlp_20 = MLPClassifier(solver='lbfgs',hidden_layer_sizes=[10])
mlp_20.fit(X_train,y_train) Z1 = mlp_20.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z1 = Z1.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z1, cmap=cmap_light) #用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,edgecolor='k',s=60)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("MLPClassifier:nodes=10")
plt.show()
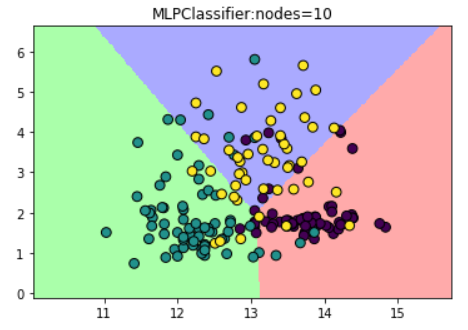
(2)设置神经网络有两个节点数为10的隐藏层
#设置神经网络2个节点数为10的隐藏层
mlp_2L = MLPClassifier(solver='lbfgs',hidden_layer_sizes=[10,10])
mlp_2L.fit(X_train,y_train) ZL = mlp_2L.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
ZL = ZL.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, ZL, cmap=cmap_light) #用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,edgecolor='k',s=60)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("MLPClassifier:2layers")
plt.show()
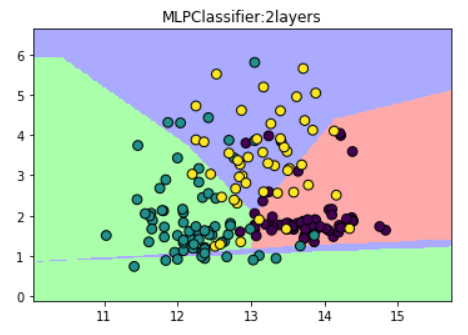
(3)设置激活函数为tanh
#设置激活函数为tanh
mlp_tanh = MLPClassifier(solver='lbfgs',hidden_layer_sizes=[10,10],activation='tanh')
mlp_tanh.fit(X_train,y_train) Z2 = mlp_tanh.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z2 = Z2.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z2, cmap=cmap_light) #用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,edgecolor='k',s=60)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("MLPClassifier:2layers with tanh")
plt.show()
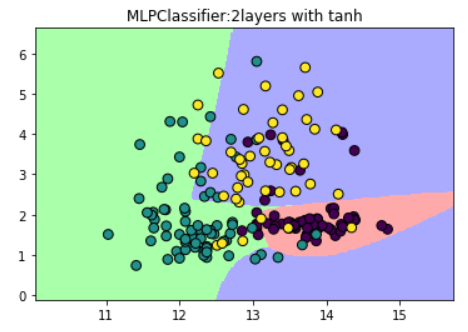
(4)修改模型的alpha参数
#修改模型的alpha参数
mlp_alpha = MLPClassifier(solver='lbfgs',hidden_layer_sizes=[10,10],activation='tanh',alpha=1)
mlp_alpha.fit(X_train,y_train) Z3 = mlp_alpha.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z3 = Z3.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z3, cmap=cmap_light) #用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,edgecolor='k',s=60)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("MLPClassifier:alpha=1")
plt.show()
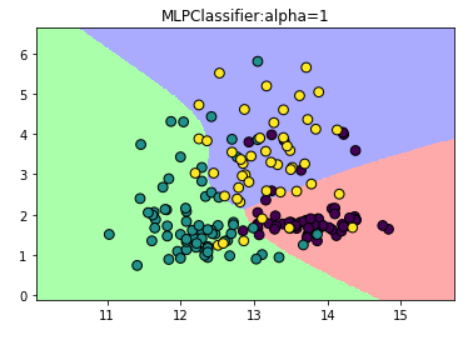
总结:
如此,我们有4种方法可以调节模型的复杂程度:
第一种,调整神经网络每一个隐藏层上的节点数
第二种,调节神经网络隐藏层的层数
第三种,调节activation的方式
第四种,通过调整alpha值来改变模型正则化的过程
对于特征类型比较单一的数据集来说,神经网络的表现还是不错的,但是如果数据集中的特征类型差异比较大的话,随机森林或梯度上升随机决策树等基于决策树的算法的表现会更好一点.
神经网络模型中的参数调节至关重要,尤其是隐藏层的数量和隐藏层中的节点数.
这里给出一个参考原则:神经网络中的隐藏层的节点数约等于训练数据集的特征数量,但一般不超过500.
如果想对庞大复杂高维的数据集做处理与分析,建议往深度学习发展,这里介绍两个流行的python深度学习库:keras,tensor-flow
文章引自 : 《深入浅出python机器学习》
"多层感知器"--MLP神经网络算法的更多相关文章
- 4.2tensorflow多层感知器MLP识别手写数字最易懂实例代码
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: https://www.cnblogs.com/bclshuai/p/11380657.html 1.1 多层感知器MLP(m ...
- TFboy养成记 多层感知器 MLP
内容总结与莫烦的视频. 这里多层感知器代码写的是一个简单的三层神经网络,输入层,隐藏层,输出层.代码的目的是你和一个二次曲线.同时,为了保证数据的自然,添加了mean为0,steddv为0.05的噪声 ...
- keras—多层感知器MLP—MNIST手写数字识别
一.手写数字识别 现在就来说说如何使用神经网络实现手写数字识别. 在这里我使用mind manager工具绘制了要实现手写数字识别需要的模块以及模块的功能: 其中隐含层节点数量(即神经细胞数量)计算 ...
- keras—多层感知器MLP—IMDb情感分析
import urllib.request import os import tarfile from keras.datasets import imdb from keras.preprocess ...
- 神经网络与机器学习 笔记—多层感知器(MLP)
多层感知器(MLP) Rosenblatt感知器和LMS算法,都是单层的并且是单个神经元构造的神经网络,他们的局限性是只能解决线性可分问题,例如Rosenblatt感知器一直没办法处理简单异或问题.然 ...
- RBF神经网络学习算法及与多层感知器的比较
对于RBF神经网络的原理已经在我的博文<机器学习之径向基神经网络(RBF NN)>中介绍过,这里不再重复.今天要介绍的是常用的RBF神经网络学习算法及RBF神经网络与多层感知器网络的对比. ...
- MLPclassifier,MLP 多层感知器的的缩写(Multi-layer Perceptron)
先看代码(sklearn的示例代码): from sklearn.neural_network import MLPClassifier X = [[0., 0.], [1., 1.]] y = [0 ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- Spark Multilayer perceptron classifier (MLPC)多层感知器分类器
多层感知器分类器(MLPC)是基于前馈人工神经网络(ANN)的分类器. MLPC由多个节点层组成. 每个层完全连接到网络中的下一层. 输入层中的节点表示输入数据. 所有其他节点,通过输入与节点的权重w ...
随机推荐
- Git - 高级合并
Git - 高级合并https://git-scm.com/book/zh/v2/Git-%E5%B7%A5%E5%85%B7-%E9%AB%98%E7%BA%A7%E5%90%88%E5%B9%B6 ...
- mongodb的开机自启动
一.背景 Linux轻松的在rc.local中写上启动脚本,reboot~发现没有启动成功.这不科学啊,查看日志发现“permission denied” 二.解决 Linux系统下,使用自定配置文件 ...
- numpy linspace
https://www.cnblogs.com/antflow/p/7220798.html numpy.linspace(start, stop, num=50, endpoint=True, re ...
- 【转载】 tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
原文地址: https://blog.csdn.net/dcrmg/article/details/79776876 ----------------------------------------- ...
- 代理类和AOP
客户端不用调用目标对象了,直接调用代理类.最终目标方法还是去实行了. 代理类的每个方法调用目标类的相同方法,并且在调用方法时候加上系统功能的代码 代理和目标实现了相同的接口,有相同的方法.通过接口进行 ...
- 算法习题---5-7打印队列(UVa12100)
一:题目 有一个打印机,有一些任务在排着队打印,每个任务都有优先级.打印时,每次取出队列第一个任务,如果它的优先级不是当前队列中最高的,就会被放到队尾,否则就打印出来.输出初始队列的第m个任务的打印时 ...
- 随机图片大小在DIV中垂直居中对齐总结
老遇到这种样式 现在总结一下 <!DOCTYPE> <html> <head> <meta http-equiv="Content-Type&quo ...
- SpringCloud学习笔记:服务支撑组件
SpringCloud学习笔记:服务支撑组件 服务支撑组件 在微服务的演进过程中,为了最大化利用微服务的优势,保障系统的高可用性,需要通过一些服务支撑组件来协助服务间有效的协作.各个服务支撑组件的原理 ...
- soapui教程
简介 SOAPUI,一款专业的web service的测试软件,SoapUI也是一个开源测试工具,通过soap/http来检查.调用.实现Web Service的功能/负载/符合性测试.该工具既可作为 ...
- Django:使用模态框新增数据,成功后提示“提交成功”,并刷新表格bootstrap-table数据
废话不说先看图: 代码实现: 前台代码: {% load staticfiles %} <!DOCTYPE html> <html lang="en"> ...