Spark性能调优:广播大变量broadcast
Spark性能调优:广播大变量broadcast
原文链接:https://blog.csdn.net/leen0304/article/details/78720838
概要
有时在开发过程中,会遇到需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时就应该使用Spark的广播(Broadcast)功能来提升性能。
在算子函数中使用到外部变量时,默认情况下,Spark会将该变量复制多个副本,通过网络传输到task中,此时每个task都有一个变量副本。如果变量本身比较大的话(比如100M,甚至1G),那么大量的变量副本在网络中传输的性能开销,以及在各个节点的Executor中占用过多内存导致的频繁GC,都会极大地影响性能。
因此对于上述情况,如果使用的外部变量比较大,建议使用Spark的广播功能,对该变量进行广播。广播后的变量,会保证每个Executor的内存中,只驻留一份变量副本,而Executor中的task执行时共享该Executor中的那份变量副本。这样的话,可以大大减少变量副本的数量,从而减少网络传输的性能开销,并减少对Executor内存的占用开销,降低GC的频率。
问题分析
Spark Application的Driver进程,其实就是我们写的Spark作业打成的jar运行起来的进程,以随机抽取map步骤为例,其工作时过程大致为:
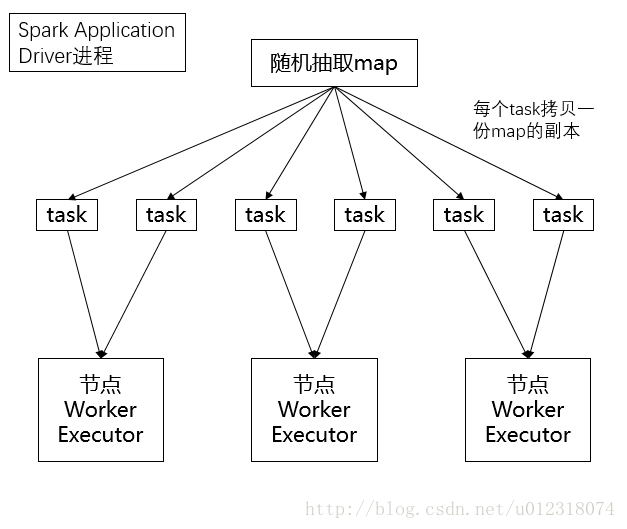
这种默认的情况下,task执行的算子中使用了外部的变量,每个task都会获取一份变量的副本,有什么缺点呢?在什么情况下会出现性能上的恶劣的影响呢?
因为map本身是不小,存放数据的一个单位是Entry,还有可能会用链表的格式的来存放Entry链条,所以map是比较消耗内存的数据格式。比如,map总共是1M。你前面调优都调的特好,资源给的到位,配合着资源并行度调节的绝对到位,设置1000个task,大量task的确都在并行运行。
第一点,这些task里面都用到了占用1M内存的map,那么首先,map会拷贝1000份副本,通过网络传输到各个task中去,给task使用。总计有1G的数据,会通过网络传输。网络传输的开销不容乐观啊!网络传输也许就会消耗掉你的spark作业运行的总时间的一小部分。
第二点,map副本传输到了各个task上之后是要占用内存的。也许1个map的确不大,也就1M,但1000个map分布在你的集群中,一下子就耗费掉1G的内存。这对性能会有什么影响呢?
首先不必要的内存的消耗和占用,就导致了你在进行RDD持久化到内存,也许就没法完全在内存中放下,就只能写入磁盘,最后导致后续的操作在磁盘IO上消耗性能;还有可能你的task在创建对象的时候,也许会发现堆内存放不下所有对象,也许就会导致频繁的垃圾回收器的回收(GC)。GC的时候一定是会导致工作线程停止,也就是导致Spark暂停工作那么一点时间。频繁GC的话对Spark作业的运行的速度会有相当可观的影响。
这种举例的随机抽取的map为1M还算小的,如果你是从哪个表里面读取了一些维度数据,比方说,所有商品品类的信息,在某个算子函数中要使用到,也许会达到100M,如果有1000个task,就会有100G的数据进行网络传输,集群瞬间因为这个原因消耗掉100G的内存。
广播大变量
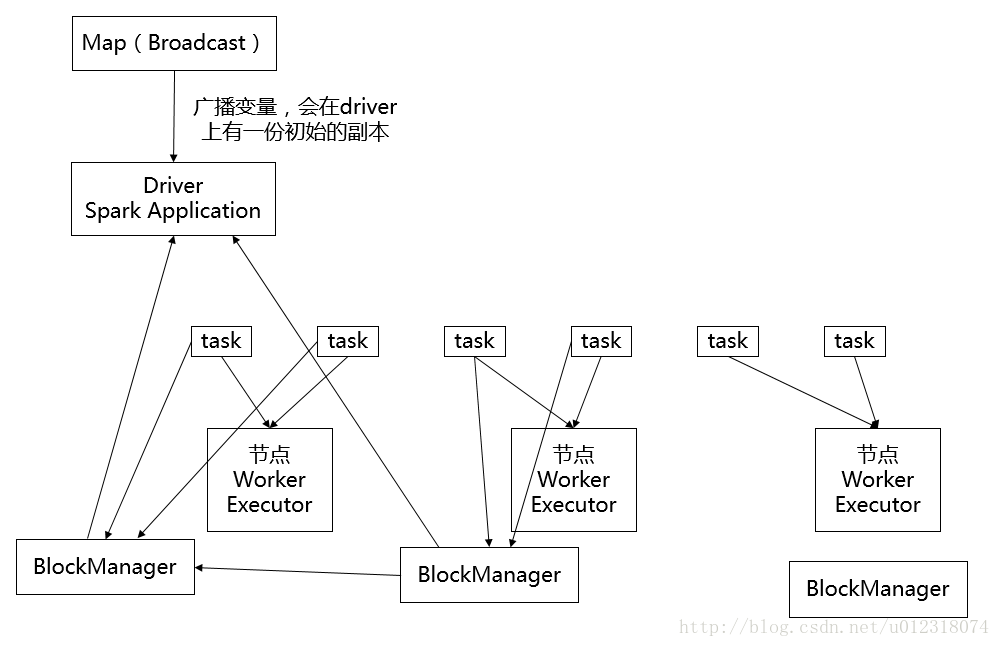
如上图所示,每个Executor会对应自己的BlockManager,BlockManager是负责管理某个Executor对应的内存和磁盘上的数据。
广播变量初始的时候就在Drvier上有一份副本,task在运行的时候,想要使用广播变量中的数据,此时首先会在自己本地的Executor对应的BlockManager中,尝试获取变量副本。如果本地没有,那么就从Driver远程拉取变量副本,并保存在本地的BlockManager中,此后这个executor上的task都会直接使用本地的BlockManager中的副本。executor的BlockManager除了从driver上拉取,也可能从其他节点的BlockManager上拉取变量副本,距离越近越好。
广播变量的优点:不是每个task一份变量副本,而是变成每个节点的executor才一份副本。这样的话,就可以让变量产生的副本大大减少。
根据在实际企业中的生产环境举例来说:总共有50个executor,1000个task,一个map大小为10M。
默认情况下,1000个task,1000份副本,共有10G的数据进行网络传输,在集群中,耗费10G的内存资源。
如果使用了广播变量,50个execurtor就只有50个副本,有500M的数据进行网络传输,而且不一定都是从Driver传输到每个节点,还可能是就近从最近的节点的executor的bockmanager上拉取变量副本,网络传输速度大大增加,只有500M的内存消耗。
之前是10000M,现在是500M,大约20倍以上的网络传输性能消耗的降低,20倍的内存消耗的减少。对性能的提升和影响,还是很客观的。
虽然说,不一定会对性能产生决定性的作用。比如运行30分钟的spark作业,可能做了广播变量以后,速度快了2分钟,或者5分钟。但是一点一滴的调优,积少成多,最后还是会有效果的。
Spark性能调优:广播大变量broadcast的更多相关文章
- Spark性能调优之代码方面的优化
Spark性能调优之代码方面的优化 1.避免创建重复的RDD 对性能没有问题,但会造成代码混乱 2.尽可能复用同一个RDD,减少产生RDD的个数 3.对多次使用的RDD进行持久化(ca ...
- Spark性能调优之解决数据倾斜
Spark性能调优之解决数据倾斜 数据倾斜七种解决方案 shuffle的过程最容易引起数据倾斜 1.使用Hive ETL预处理数据 • 方案适用场景:如果导致数据倾斜的是Hive表.如果该Hiv ...
- [Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析
本課主題 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- spark 性能调优(一) 性能调优的本质、spark资源使用原理、调优要点分析
转载:http://www.cnblogs.com/jcchoiling/p/6440709.html 一.大数据性能调优的本质 编程的时候发现一个惊人的规律,软件是不存在的!所有编程高手级别的人无论 ...
- Spark性能调优之合理设置并行度
Spark性能调优之合理设置并行度 1.Spark的并行度指的是什么? spark作业中,各个stage的task的数量,也就代表了spark作业在各个阶段stage的并行度! 当分配 ...
- Spark性能调优之资源分配
Spark性能调优之资源分配 性能优化王道就是给更多资源!机器更多了,CPU更多了,内存更多了,性能和速度上的提升,是显而易见的.基本上,在一定范围之内,增加资源与性能的提升,是成正比的:写完了 ...
- Spark性能调优之Shuffle调优
Spark性能调优之Shuffle调优 • Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外内存(netty是零拷贝),所以使用了堆外内存. ...
- Spark性能调优之JVM调优
Spark性能调优之JVM调优 通过一张图让你明白以下四个问题 1.JVM GC机制,堆内存的组成 2.Spark的调优为什么会和JVM的调 ...
- Spark性能调优
Spark性能优化指南——基础篇 https://tech.meituan.com/spark-tuning-basic.html Spark性能优化指南——高级篇 https://tech.meit ...
随机推荐
- 【线性代数】Linear Algebra Big Picture
Abstract: 通过学习MIT 18.06课程,总结出的线性代数的知识点相互依赖关系,后续博客将会按照相应的依赖关系进行介绍.(2017-08-18 16:28:36) Keywords: Lin ...
- dup2函数
将当前系统中的进程信息打印到文件中 命令行:ps aux > out 将ps得到的信息重定向到out文件中 使用dup2文件在程序中完成. int dup2(int oldfd,int newf ...
- CodeForces 754C Vladik and chat ——(xjbg)
虽然是xjbg的题目,但是并不很好做. 题意不难理解.读入有点麻烦.做法是先正着推每段对话的?可能是谁说的,然后反过来选择即可.正推时,其中vis数组表示谁已经被用过了,cnt表示该组当前可以选择几个 ...
- 5.使用Ribbon实现客户端侧负载均衡
Ribbon实现客户端侧负载均衡 5.1. Ribbon简介 Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法 ...
- 在 Go 语言中使用 Session(一)
在上一篇博客 理解Cookie和Session 中,我们了解了 Cookie 和 Session 的一些基础知识,也知道了 Session 的基本原理是由服务端保存一份状态信息(以及它的唯一标识符), ...
- IDEA个人常用配置记录
原文 一.常用快捷键 编辑 ⇧ + ↩:开始新的一行 ⌘ + ⇧ + ↩:行内任意位置进行换行,并自动补齐“;”.“{}” ⌘ + ⇧ + U:大小写切换 ⌥ + ⌦:删除到单词的末尾(⌦键为Fn+D ...
- LeetCode 岛屿的最大面积(探索字节跳动)
题目描述 给定一个包含了一些 0 和 1的非空二维数组 grid , 一个 岛屿 是由四个方向 (水平或垂直) 的 1 (代表土地) 构成的组合.你可以假设二维矩阵的四个边缘都被水包围着. 找到给定的 ...
- 【Makefile】Makefile中的常用函数简介
1. subst函数 格式:$(subst <from>, <to>, <text>)功能:把字串<text>中的<from>字符串替换成& ...
- NetUtils网络连接工具类
import android.app.Activity; import android.content.ComponentName; import android.content.Context; i ...
- SpringMVC,SpringBoot上传文件简洁代码
@RequestMapping("/updateAvatar.html") public String updateHeadUrl(MultipartFile avatar, Mo ...