Spark中Task,Partition,RDD、节点数、Executor数、core数目的关系和Application,Driver,Job,Task,Stage理解

输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为Block。
当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨越文件。
随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。
随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partiton。
注意: 这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。
而 Task被执行的并发度 = Executor数目 * 每个Executor核数。
至于partition的数目:
- 对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task。
- 在Map阶段partition数目保持不变。
- 在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
1,Application
application(应用)其实就是用spark-submit提交的程序。比方说spark examples中的计算pi的SparkPi。一个application通常包含三部分:从数据源(比方说HDFS)取数据形成RDD,通过RDD的transformation和action进行计算,将结果输出到console或者外部存储(比方说collect收集输出到console)。
2,Driver
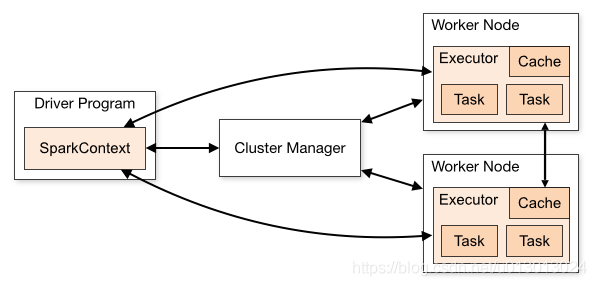
Spark中的driver感觉其实和yarn中Application Master的功能相类似。主要完成任务的调度以及和executor和cluster manager进行协调。有client和cluster联众模式。client模式driver在任务提交的机器上运行,而cluster模式会随机选择机器中的一台机器启动driver。从spark官网截图的一张图可以大致了解driver的功能。
3,Job
Spark中的Job和MR中Job不一样不一样。MR中Job主要是Map或者Reduce Job。而Spark的Job其实很好区别,一个action算子就算一个Job,比方说count,first等。
4, Task
Task是Spark中最新的执行单元。RDD一般是带有partitions的,每个partition的在一个executor上的执行可以任务是一个Task。
5, Stage
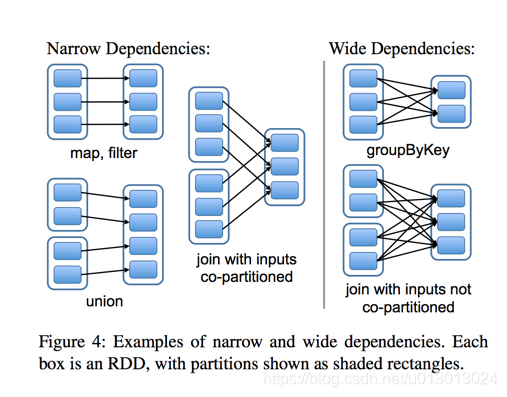
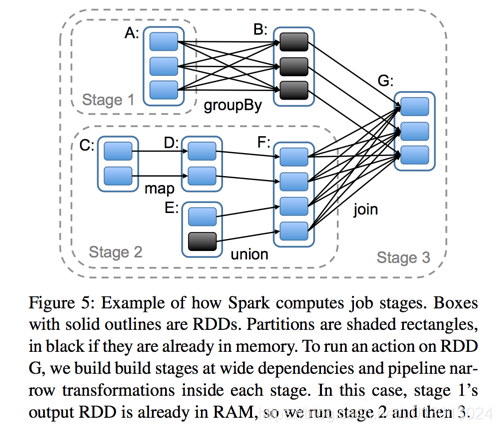
Stage概念是spark中独有的。一般而言一个Job会切换成一定数量的stage。各个stage之间按照顺序执行。至于stage是怎么切分的,首选得知道spark论文中提到的narrow dependency(窄依赖)和wide dependency( 宽依赖)的概念。其实很好区分,看一下父RDD中的数据是否进入不同的子RDD,如果只进入到一个子RDD则是窄依赖,否则就是宽依赖。宽依赖和窄依赖的边界就是stage的划分点
--class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client --driver-memory 4g --num-executors 2 --executor-memory 2g --executor-cores 2 /opt/apps/spark-1.6.0-bin-hadoop2.6/lib/spark-examples*.jar 10参数说明如下所示:
| 参数 | 参考值 | 说明 |
|---|---|---|
| class | org.apache.spark.examples.SparkPi | 作业的主类。 |
| master | yarn | 因为 E-MapReduce 使用 yarn 的模式,所以这里只能是 yarn 模式。 |
| yarn-client | 等同于 –-master yarn —deploy-mode client, 此时不需要指定deploy-mode。 | |
| yarn-cluster | 等同于 –-master yarn —deploy-mode cluster, 此时不需要指定deploy-mode。 | |
| deploy-mode | client | client 模式表示作业的 AM 会放在 Master 节点上运行。要注意的是,如果设置这个参数,那么需要同时指定上面 master 为 yarn。 |
| cluster | cluster 模式表示 AM 会随机的在 worker 节点中的任意一台上启动运行。要注意的是,如果设置这个参数,那么需要同时指定上面 master 为yarn。 | |
| driver-memory | 4g | driver 使用的内存,不可超过单机的 core 总数。 |
| num-executors | 2 | 创建多少个 executor。 |
| executor-memory | 2g | 各个 executor 使用的最大内存,不可超过单机的最大可使用内存。 |
| executor-cores | 2 | 各个 executor 使用的并发线程数目,也即每个 executor 最大可并发执行的 Task 数目。 |
资源计算
- yarn-client 模式的资源计算
节点 资源类型 资源量(结果使用上面的例子计算得到) master core 1 mem driver-memroy = 4G worker core num-executors * executor-cores = 4 mem num-executors * executor-memory = 4G - 作业主程序(Driver 程序)会在 master 节点上执行。按照作业配置将分配 4G(由 —driver-memroy 指定)的内存给它(当然实际上可能没有用到)。
- 会在 worker 节点上起 2 个(由 —num-executors 指定)executor,每一个 executor 最大能分配 2G(由 —executor-memory 指定)的内存,并最大支持 2 个(由—executor-cores 指定)task 的并发执行。
- yarn-cluster 模式的资源计算
节点 资源类型 资源量(结果使用上面的例子计算得到) master 一个很小的 client 程序,负责同步 job 信息,占用很小。 worker core num-executors * executor-cores+spark.driver.cores = 5 mem num-executors * executor-memory + driver-memroy = 8g 说明 这里的 spark.driver.cores 默认是 1,也可以设置为更多。
资源使用的优化
- yarn-client 模式
若您有了一个大作业,使用 yarn-client 模式,想要多用一些这个集群的资源,请参见如下配置:
--master yarn-client --driver-memory 5g –-num-executors 20 --executor-memory 4g --executor-cores 4注意- Spark 在分配内存时,会在用户设定的内存值上溢出 375M 或 7%(取大值)。
- Yarn 分配 container 内存时,遵循向上取整的原则,这里也就是需要满足 1G 的整数倍。
按照上述的资源计算公式,
master 的资源量为:
- core:1
- mem:6G (5G + 375M 向上取整为 6G)
workers 的资源量为:
- core: 20*4 = 80
- mem: 20*5G (4G + 375M 向上取整为 5G) = 100G
可以看到总的资源没有超过集群的总资源,那么遵循这个原则,您还可以有很多种配置,例如:--master yarn-client --driver-memory 5g --num-executors 40 --executor-memory 1g --executor-cores 2--master yarn-client --driver-memory 5g --num-executors 15 --executor-memory 4g --executor-cores 4--master yarn-client --driver-memory 5g --num-executors 10 --executor-memory 9g --executor-cores 6原则上,按照上述的公式计算出来的需要资源不超过集群的最大资源量就可以。但在实际场景中,因为系统,hdfs 以及 E-MapReduce 的服务会需要使用 core 和 mem 资源,如果把 core 和 mem 都占用完了,反而会导致性能的下降,甚至无法运行。
executor-cores 数一般也都会被设置成和集群的可使用核一致,因为如果设置的太多,CPU 会频繁切换,性能并不会提高。
- yarn-cluster 模式
当使用 yarn-cluster 模式后,Driver 程序会被放到 worker 节点上。资源会占用到 worker 的资源池里面,这时若想要多用一些这个集群的资源,请参加如下配置:
--master yarn-cluster --driver-memory 5g --num-executors 15 --executor-memory 4g --executor-cores 4
Spark中Task,Partition,RDD、节点数、Executor数、core数目的关系和Application,Driver,Job,Task,Stage理解的更多相关文章
- Spark中的partition和block的关系
hdfs中的block是分布式存储的最小单元,类似于盛放文件的盒子,一个文件可能要占多个盒子,但一个盒子里的内容只可能来自同一份文件.假设block设置为128M,你的文件是250M,那么这份文件占3 ...
- spark——spark中常说RDD,究竟RDD是什么?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark专题第二篇文章,我们来看spark非常重要的一个概念--RDD. 在上一讲当中我们在本地安装好了spark,虽然我们只有lo ...
- spark中的pair rdd,看这一篇就够了
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark专题的第四篇文章,我们一起来看下Pair RDD. 定义 在之前的文章当中,我们已经熟悉了RDD的相关概念,也了解了RDD基 ...
- Spark中Task,Partition,RDD、节点数、Executor数、core数目(线程池)、mem数
Spark中Task,Partition,RDD.节点数.Executor数.core数目的关系和Application,Driver,Job,Task,Stage理解 from:https://bl ...
- spark中资源调度任务调度
在spark的资源调度中 1.集群启动worker向master汇报资源情况 2.Client向集群提交app,向master注册一个driver(需要多少core.memery),启动一个drive ...
- 【原】Spark中Stage的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Job如何划分为Stage http://www.cnblogs.com/yourarebest/p/5342424.html 1 ...
- Hanlp分词1.7版本在Spark中分布式使用记录
新发布1.7.0版本的hanlp自然语言处理工具包差不多已经有半年时间了,最近也是一直在整理这个新版本hanlp分词工具的相关内容.不过按照当前的整理进度,还需要一段时间再给大家详细分享整理的内容.昨 ...
- 原创:Spark中GraphX图运算pregel详解
由于本人文字表达能力不足,还是多多以代码形式表述,首先展示测试代码,然后解释: package com.txq.spark.test import org.apache.spark.graphx.ut ...
- Spark中分布式使用HanLP(1.7.0)分词示例
HanLP分词,如README中所说,如果没有特殊需求,可以通过maven配置,如果要添加自定义词典,需要下载“依赖jar包和用户字典". 分享某大神的示例经验: 是直接"java ...
随机推荐
- HDU - 1403 - Longest Common Substring
先上题目: Longest Common Substring Time Limit: 8000/4000 MS (Java/Others) Memory Limit: 65536/32768 K ...
- NandFlash、NorFlash、DataFlash
1. NandFlash和NorFlash Flash存储芯片,俗称闪存,因其具有非易失性.可擦除性.可重复编程及高密度.低功耗等特点,广泛地应用于手机.数码相机.笔记本电脑等产品. ...
- 学习webpack过程并上传到github
使用工具:sublimeText+node+git 1,一个包的文件结构,生成初始文件 在node 命令行窗口中创建demo_a文件夹 使用命令 npm init 初始化包,生成package.jso ...
- [转]SQLSERVER一些公用DLL的作用解释
转自:Leo_wlCnBlogs SQLSERVER一些公用DLL的作用解释 如果你的SQLSERVER安装在C盘的话,下面的路径就是相应SQLSERVER版本的公用DLL的存放路径 SQL2005 ...
- hibernate 普通字段延迟载入无效的解决的方法
关联对象的延迟载入就不说了.大家都知道. 关于普通字段的延迟载入,尤其是lob字段,若没有延迟载入,对性能影响极大.然而简单的使用 @Basic(fetch = FetchType.LAZY) 注解并 ...
- VIM 移动
基础 字符移动 k 上移 k h 左移 h l l 右移 j j 下移 你也可以使用键盘上的方向键来移动,但这么做h j k l的存在就失去了意义 之所以使用h j k l来控制方向,其主要目的是让你 ...
- 87.Ext_菜单组件_Ext.menu.Menu
转自:https://blog.csdn.net/lms1256012967/article/details/52574921 菜单组件常用配置: /* Ext.menu.Menu主要配置项表: it ...
- Coursera Algorithms week3 归并排序 练习测验: Merging with smaller auxiliary array
题目原文: Suppose that the subarray a[0] to a[n-1] is sorted and the subarray a[n] to a[2*n-1] is sorted ...
- nodejs express开发
用NodeJS+Express开发WEB应用---第一篇 大漠穷秋2014-03-28 预热 为了对后面的内容理解更加透彻,推荐首先阅读下面这篇很好的文章: http://www.nodebeginn ...
- poj3071Football(概率期望dp)
Football Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 5620 Accepted: 2868 Descript ...