Hadoop学习笔记(七):初识spark
1. spark的安装:
a). 首先复制一台虚拟机出来(复制任意一台master和slave即可),然后将其ip修改为192.168.XX.200,并将其hostname更改为c(hostnamectl set-hostname c)。然后再/etc/hosts文件中添加对本机的解析。最后重启网络服务。
b). 到官网下载spark(spark.apache.org,记住要下载对应hadoop版本的,这里下载的是spark-2.1.1-bin-hadoop2.7.tgz),并上传至/usr/local目录,然后解压,重命名为spark。
2. spark的运行模式:
a) local模式
b) standalone模式
c) yarn模式
d) mesos模式
3. 进入到spark目录下,执行命令:
./bin/spark-submit --class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.11-2.1.0.jar 10000
该命令表示提交一个spark例子程序,后边的10000表示10000个任务,该程序可以计算圆周率,最后的数字越大最后计算出来的结果越精确。提交任务后可以在宿主机输入IP地址:4040进行查看(该程序结束后,就不能访问该页面了)
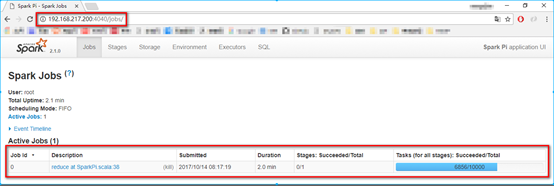
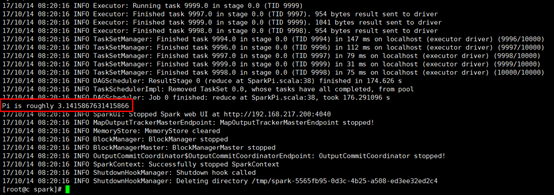
4. 等该任务执行结束后,观察执行结果:
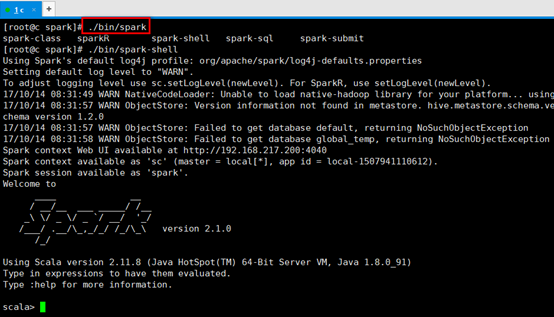
5. 进入spark-shell命令模式,输入:./bin/spark-shell
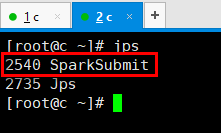
新打开一个连接窗口,输入命令jps,可以看到又启动了一个SparkSubmit服务:
6. spark-shell里敲的命令可以转换为一个job,通过SparkSubmit提交给spark,最后的结果在spark-shell里进行展示。
7. RDD(简言RDD就是一个数据集合,分布式存放,可以理解为里边装了一条条的数据)
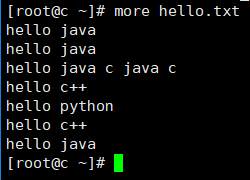
8. 在root目录下创建hello.txt文件,内容如下:
9. 执行val lineRDD = sc.textFile(“/root/hello.txt”)命令,其中,sc为ScalaContent对象,其Scala的上下文对象,从结果可以看出来,该命令的执行结果为一个RDD数组,数组里边的元素为String类型。

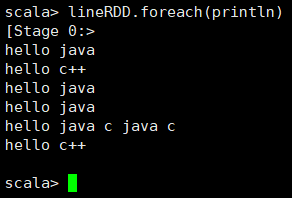
10. 遍历得到的数组,输入命令:lineRDD.foreach(println)观察结果
11. 执行lineRDD.collect命令,将lineRDD转换成一个Array

12. 执行val wordRDD = lineRDD.flatMap(line => line.split(" "))命令,将lineRDD里的每一个单词进行拆分。

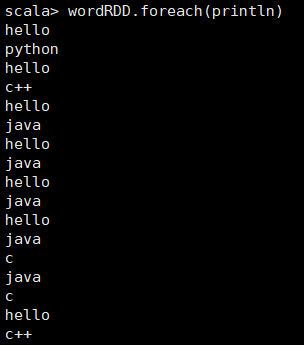
13. 执行wordRDD.foreach(println),查看wordRDD内容:
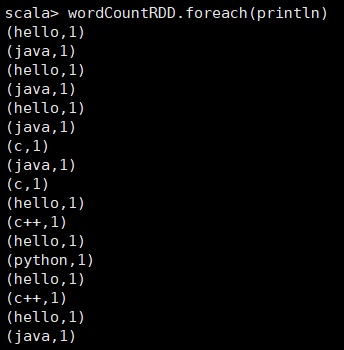
14. 执行val wordCountRDD = wordRDD.map(word => (word, 1))命令,该命令是遍历wordRDD里的每一个元素,并将该元素变成一个元组(key-value格式,key为该单词,value为1),然后输入wordCountRDD.foreach(println)观察其内容:
15. 执行var resultRDD = wordCountRDD.reduceByKey((x, y) => x + y)命令,熟悉MapReduce的应该知道,该命令相当于MapReduce中reduce的缩减过程,即通过key进行缩减,将相同key的value值(即x和y)进行相加,然后作为一个新的元组,进行下一次的reduce操作。遍历resultRDD进行结果的查看:
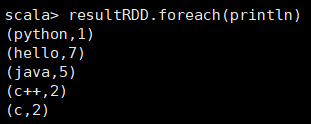
16. 上面所有的操作可以用一句scala语句来实现:

17. 去到输出目录查看,这个应该很眼熟了:
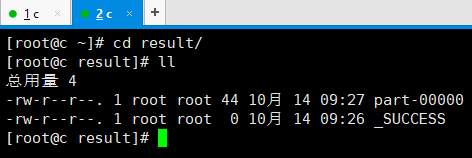
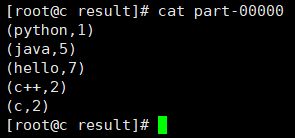
18. 查看结果:
Hadoop学习笔记(七):初识spark的更多相关文章
- Hadoop学习笔记—4.初识MapReduce
一.神马是高大上的MapReduce MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算.对于大数据量的计算,通常采用的处理手法就是并行计算.但对许多开发者来 ...
- Hadoop学习笔记(1) 初识Hadoop
1. Hadoop提供了一个可靠的共享存储和分析系统.HDFS实现存储,而MapReduce实现分析处理,这两部分是Hadoop的核心. 2. MapReduce是一个批量查询处理器,并且它能够在合理 ...
- python学习笔记七 初识socket(进阶篇)
socket socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过"套接字"向网络发出请求或者应答网络请求. sock ...
- Storm学习笔记 - Storm初识
Storm学习笔记 - Storm初识 1. Strom是什么? Storm是一个开源免费的分布式计算框架,可以实时处理大量的数据流. 2. Storm的特点 高性能,低延迟. 分布式:可解决数据量大 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Hadoop学习笔记系列
Hadoop学习笔记系列 一.为何要学习Hadoop? 这是一个信息爆炸的时代.经过数十年的积累,很多企业都聚集了大量的数据.这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
随机推荐
- 笔记:Spring Cloud Ribbon RestTemplate 详解
详细介绍RestTemplate 针对几种不同请求类型和参数类型的服务调用实现,示例代码中的 restTemplate 都是通过Spring 注入方式创建的,相关代码如下: @Autowired pr ...
- ASUS T100TA 换屏要记
建议完整阅读后再执行操作! 参考: [图片]华硕T100换触摸屏详细教程,全网第一发[平板电脑吧]_百度贴吧 [图片]我是这么修T100的……换外屏[win8平板吧]_百度贴吧 淘宝信息: 选择适用型 ...
- 使用pm2躺着实现负载均衡
事实上,pm2 是一个带有负载均衡功能的Node应用的进程管理器,Node实现进程管理的库有很多,forever也是其中一个很强大但是也相对较老的进程管理器. 为什么要使用pm2 对于这个问题,先说说 ...
- mysql数据库索引优化与实践(一)
前言 mysql数据库是现在应用最广泛的数据库系统.与数据库打交道是每个Java程序员日常工作之一,索引优化是必备的技能之一. 为什么要了解索引 真实案例 案例一:大学有段时间学习爬虫,爬取了知乎30 ...
- Django+xadmin打造在线教育平台(六)
九.课程章节信息 9.1.模板和urls 拷贝course-comments.html 和 course-video.html放入 templates目录下 先改course-video.html,同 ...
- javascript里的循环语句
前序:我一直对于for跟for..in存在一种误解,我觉得for都能把事情都做了,为啥还要for...in...这玩意了,有啥用,所以今天就说说JavaScript里的循环语句. 循环 要计算1+2+ ...
- 大数据 --> MapReduce原理与设计思想
MapReduce原理与设计思想 简单解释 MapReduce 算法 一个有趣的例子:你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃? MapReduce方法则是: 给在座 ...
- kvm之三:本地安装虚拟机
1.格式化新添加的磁盘 [root@kvm ~ ::]#fdisk /dev/sdb Command (m for help): n //新建分区 Command action e extended ...
- 让Myeclipse自动生成的get set方法 自动加上文本注释,并且注释内容包含字段中我们加的文档注释
在进行编码写实体类的时候发现,一个实体类有好多的字段要进行注释,他们都是私有的不能直接访问,我们在写的时候加入的文档注释也起不到效果,但是自动生成的get,set方法的文档注释有不符合我们要求(没有包 ...
- python IDLE中反斜杠显示为人民币符号¥的解决办法
改换英文字体即可