PyTorch复现LeNet-5手写识别学习笔记
用PyTorch搭建LeNet-5手写识别
首先申明,这篇博客用于记录本人看完LeNet-5论文,并对其中的算法进行复现的记录,可以看成是学习笔记
这里只介绍复现的工作,如果想了解更多有关网络的细节,请去看论文《Gradient-Based Learning Applied to Document Recognition》
在此推荐一个b站up的视频从0开始撸代码--手把手教你搭建LeNet-5网络模型_哔哩哔哩_bilibili,博主也是根据此视频进行复现的,博主其实是个小菜鸟
博主觉得up讲的还不错的,视频不涉及原理,只是手把手教你如何搭建
要想细追原理,最好直接看YannLeCun论文《Gradient BasedLearning Applied to Document Recognition》,在此奉上。
链接:https://pan.baidu.com/s/1cB1pheefesy2Q6aR2WscXg?pwd=iq43 提取码:iq43
一、必要的环境
如果你什么都不会,可以先去这篇博客把所需的驱动,软件都下好,里面paddlepaddle环境不用安装
这里博主也是重新创建了一个叫pytorch的环境,python版本是3.8,
然后在cmd输入nvidia-smi命令来查看自己电脑最高支持的cuda版本
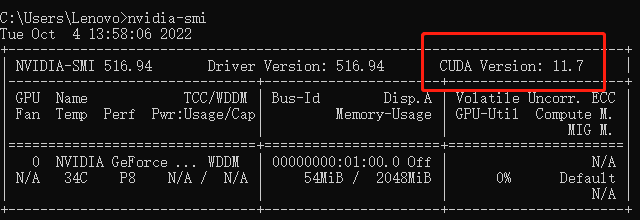
我的最高支持是11.7,我下载的是cuda11.3版本的
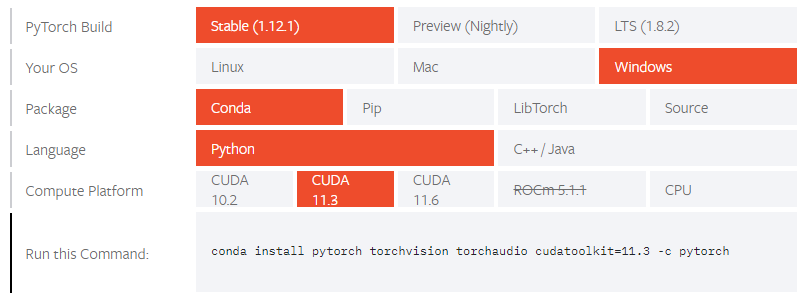
在之前创建的pytoch输入代码,应该就能安装成功
conda install pytorch torchvision torchaudio cudatoolkit=11.3
但博主输入这行代码就会报错,好像是找不到库还是什么原因,如果你们也会报错试试下面的代码
conda install pytorch==1.11.0 torchvision=0.12.0 cudatoolkit=11.3 -c pytorch
后面的-C不能去掉,这样下载能成功,但速度有点慢
注意:里面一个pytorch包1.2g太大了,如果因为网速慢没下载成功,可以试试这串代码
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
然后再次输入这行代码conda install pytorch==1.11.0 torchvision=0.12.0 cudatoolkit=11.3 -c pytorch ,把剩下的包下载好
下载好后,用炮哥博客的代码进行验证
import torch
print(torch.cuda.is_available())
print(torch.backends.cudnn.is_available())
print(torch.cuda_version)
print(torch.backends.cudnn.version())
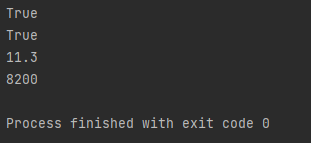
结果显示,就表示成功了,cuda版本11.3,cudnn的版本为8.20版本
到此为止,手写识别所需的环境就安装好了
二、搭建模型、训练
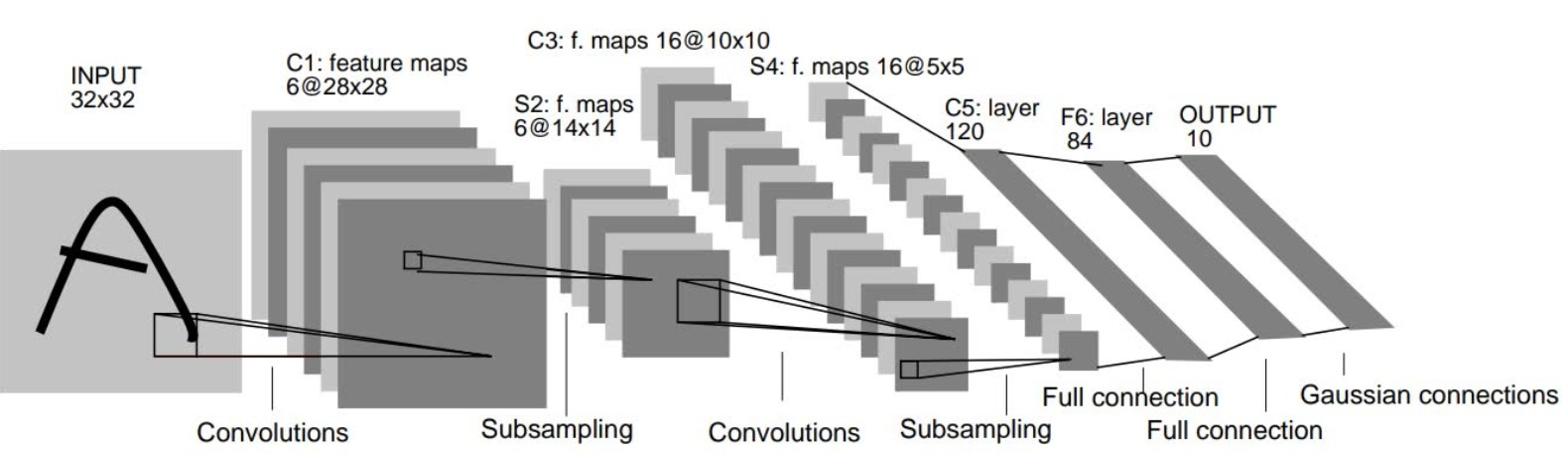
1.整体框图
我们就要利用整体框图来搭建模型,卷积层都采用5*5的卷积核,步长为1,池化层(下采样层)采用都2*2的卷积,步长为2
2.net.py
搭建模型基本结构、手写识别的代码还是比较好看懂的,可以自己去理解下
1 import torch
2 from torch import nn
3
4 #定义一个网络模型类
5 class MyLeNet5(nn.Module):
6 #初始化网络
7 def __init__(self):
8 super(MyLeNet5,self).__init__()
9 #输入大小为32*32,输出大小为28*28,输入通道为1,输出为6,卷积核大小为5,步长为1
10 self.c1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
11 #sigmoid激活函数
12 self.Sigmoid= nn.Sigmoid()
13 #平均池化
14 self.s2 = nn.AvgPool2d(kernel_size=2, stride=2)
15 self.c3 = nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5)
16 self.s4 = nn.AvgPool2d(kernel_size=2,stride=2)
17 self.c5 = nn.Conv2d(in_channels=16,out_channels=120,kernel_size=5)
18 #展开
19 self.flatten = nn.Flatten()
20 self.f6 = nn.Linear(120,84)
21 self.output = nn.Linear(84,10)
22
23 def forward(self,x):
24 #输入x为32*32*1,输出为28*28*6
25 x = self.Sigmoid(self.c1(x))
26 #输入为28*28*6,输出为14*14*6
27 x = self.s2(x)
28 # 输入为14*14*6,输出为10*10*16
29 x = self.Sigmoid(self.c3(x))
30 # 输入为10*10*16,输出为5*5*16
31 x = self.s4(x)
32 # 输入为5*5*16,输出为1*1*120
33 x = self.c5(x)
34 x = self.flatten(x)
35 # 输入为120,输出为84
36 x = self.f6(x)
37 # 输入为84,输出为10
38 x = self.output(x)
39 return x
40
41 if __name__=="__main__":
42 x = torch.rand([1,1,28,28])#任意产生一个张量,批次1,通道为1,大小为28*28
43 model = MyLeNet5()#网络实例化
44 y = model(x) #输出结果
写完后保存,可以运行下看是否报错
3.train.py
这是用于训练模型的代码
1 import torch
2 from torch import nn
3 from net import MyLeNet5
4 from torch.optim import lr_scheduler
5 from torchvision import datasets,transforms
6 import os
7
8
9 #将数据转化为tensor格式
10 data_transform = transforms.Compose([
11 transforms.ToTensor()
12 ])
13
14 # 加载训练数据集
15 train_dataset = datasets.MNIST(root='./data', train=True, transform=data_transform, download=True)
16 # 给训练集创建一个数据加载器, shuffle=True用于打乱数据集,每次都会以不同的顺序返回。
17 train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
18 # 加载训练数据集
19 test_dataset = datasets.MNIST(root='./data', train=False, transform=data_transform, download=True)
20 # 给训练集创建一个数据加载器, shuffle=True用于打乱数据集,每次都会以不同的顺序返回。
21 test_dataloader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=16, shuffle=True)
22
23
24 # 如果显卡可用,则用显卡进行训练
25 device = "cuda" if torch.cuda.is_available() else 'cpu'
26
27 #调用net文件的模型,果GPU可用则将模型转到GPU
28 model = MyLeNet5().to(device)
29
30 #定义损失函数,交叉熵损失
31 loss_fn = nn.CrossEntropyLoss()
32
33 #定义优化器SGD,随机梯度下降
34 optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)
35
36 #学习率每10个epoch变为原来的0.1
37 lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
38
39 #定义训练函数
40 def train(dataloader, model, loss_fn, optimizer):
41 loss, current, n = 0.0, 0.0, 0
42 # enumerate返回为数据和标签还有批次
43 for batch, (X, y) in enumerate(dataloader):
44 # 前向传播
45 X, y = X.to(device), y.to(device)
46 output = model(X)
47 cur_loss = loss_fn(output, y)
48 # torch.max返回每行最大的概率和最大概率的索引,由于批次是16,所以返回16个概率和索引
49 _, pred = torch.max(output, axis=1)
50
51 # 计算每批次的准确率, output.shape[0]为该批次的多少
52 cur_acc = torch.sum(y == pred) / output.shape[0]
53 # print(cur_acc)
54 # 反向传播
55 optimizer.zero_grad()
56 cur_loss.backward()
57 optimizer.step()
58 # 取出loss值和精度值
59 loss += cur_loss.item()
60 current += cur_acc.item()
61 n = n + 1
62
63 print('train_loss:' + str(loss / n))
64 print('train_acc:' + str(current / n))
65
66
67 #定义验证函数
68 def val(dataloader,model,loss_fn):
69 # 将模型转为验证模式
70 model.eval()
71 loss, acc, n = 0.0, 0.0, 0
72 # enumerate返回为数据和标签还有批次
73 with torch.no_grad():
74 for batch, (x, y) in enumerate(dataloader):
75 # 前向传播
76 x, y = x.to(device), y.to(device)
77 output = model(x)
78 cur_loss = loss_fn(output, y)
79 # torch.max返回每行最大的概率和最大概率的索引,由于批次是16,所以返回16个概率和索引
80 _, pred = torch.max(output, axis=1)
81
82 # 计算每批次的准确率, output.shape[0]为该批次的多少
83 cur_acc = torch.sum(y == pred) / output.shape[0]
84 loss += cur_loss.item()
85 acc += cur_acc.item()#取出单元素张量的元素值并返回该值
86 n += 1 # 记录有多少批次
87 print('test_loss:' + str(loss / n))
88 print('test_acc:' + str(acc / n))
89
90 return acc/n
91
92 #开始训练
93 epoch = 30#训练轮次
94 max_acc = 0
95 for t in range(epoch):
96 lr_scheduler.step()#学习率调整
97 print(f"epoch{t+1}\n-------------------")#加f表示格式化字符串,加f后可以在字符串里面使用用花括号括起来的变量和表达式
98 train(train_dataloader, model, loss_fn, optimizer)#调用train函数
99 a = val(test_dataloader,model,loss_fn)
100 #保存最后的模型权重文件
101 if a > max_acc:
102 folder = 'save_model'
103 if not os.path.exists(folder):
104 os.mkdir('save_model')
105 max_acc = a
106 print('save best model')
107 torch.save(model.state_dict(),"save_model/best_model.pth")
108 #保存最后的文件
109 if t == epoch - 1:
110 torch.save(model.state_dict(),"save_model/last_model.pth")
111 print('Done')
写完后运行train.py,大概需要一会时间,代码运行完成后,会生成最好和最后的权重

博主训练了30轮,训练集和测试集的准确就达到了96
三、模型测试
1.test.py
训练完成后,将最好的权重路径放到test.py文件里,运行代码,在此博客选择前10张图片作为验证,你们可以根据需求自己改
1 import torch
2 from net import MyLeNet5
3 from torch.autograd import Variable
4 from torchvision import datasets,transforms
5 from torchvision.transforms import ToPILImage
6
7 # 将数据转化为tensor格式
8 data_transform = transforms.Compose([
9 transforms.ToTensor()
10 ])
11
12 # 加载训练数据集
13 train_dataset = datasets.MNIST(root='./data', train=True, transform=data_transform, download=True)
14 # 给训练集创建一个数据加载器, shuffle=True用于打乱数据集,每次都会以不同的顺序返回。
15 #train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
16 # 加载训练数据集
17 test_dataset = datasets.MNIST(root='./data', train=False, transform=data_transform, download=True)
18 # 给训练集创建一个数据加载器, shuffle=True用于打乱数据集,每次都会以不同的顺序返回。
19 #test_dataloader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=16, shuffle=True)
20
21 # 如果显卡可用,则用显卡进行训练
22 device = "cuda" if torch.cuda.is_available() else 'cpu'
23
24 # 调用net里面定义的模型,如果GPU可用则将模型转到GPU
25 model = MyLeNet5().to(device)
26
27 #加载train.py里训练好的模型
28 model.load_state_dict(torch.load(("D:/python/LeNet-5/save_model/best_model.pth")))#填写权重路径
29
30 #获取预测结果
31
32 classes = [
33 "0",
34 "1",
35 "2",
36 "3",
37 "4",
38 "5",
39 "6",
40 "7",
41 "8",
42 "9",
43 ]
44
45 # 把tensor转换成Image,方便可视化
46 show = ToPILImage()
47
48 #进入验证阶段
49 model.eval()
50 # 对test_dataset手写数字图片进行推理
51 for i in range(10): #在此处可以选择需要验证的图片,这里博主选择了前10张
52 x,y = test_dataset[i][0],test_dataset[i][1]
53 #可视化
54 show(x).show()
55 # 扩展张量维度为4维
56 x = Variable(torch.unsqueeze(x,dim=0).float(),requires_grad=False).to(device)
57 with torch.no_grad():
58 pred = model(x)
59 # 得到预测类别中最高的那一类,再把最高的这一类对应的标签输出
60 predicted,actual = classes[torch.argmax(pred[0])],classes[y]
61 print(f'predicted:"{predicted},actual:{actual}"')
测试结果,可以看到还是非常不错的
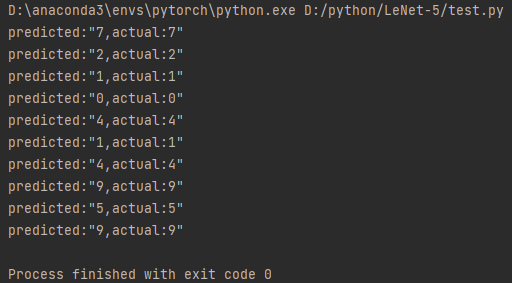
到这手写识别算法基本就完成了
总结
手写识别算,利用现在的框架复现还是比较容易的,代码也是容易读懂,希望这篇博客对你有用
最后的最后,码字不易,给个赞吧wuwuwu~

PyTorch复现LeNet-5手写识别学习笔记的更多相关文章
- Caffe系列4——基于Caffe的MNIST数据集训练与测试(手把手教你使用Lenet识别手写字体)
基于Caffe的MNIST数据集训练与测试 原创:转载请注明https://www.cnblogs.com/xiaoboge/p/10688926.html 摘要 在前面的博文中,我详细介绍了Caf ...
- Pytorch卷积神经网络识别手写数字集
卷积神经网络目前被广泛地用在图片识别上, 已经有层出不穷的应用, 如果你对卷积神经网络充满好奇心,这里为你带来pytorch实现cnn一些入门的教程代码 #首先导入包 import torchfrom ...
- 10分钟教你用python 30行代码搞定简单手写识别!
欲直接下载代码文件,关注我们的公众号哦!查看历史消息即可! 手写笔记还是电子笔记好呢? 毕业季刚结束,眼瞅着2018级小萌新马上就要来了,老腊肉小编为了咱学弟学妹们的学习,绞尽脑汁准备编一套大学秘籍, ...
- Pytorch1.0入门实战一:LeNet神经网络实现 MNIST手写数字识别
记得第一次接触手写数字识别数据集还在学习TensorFlow,各种sess.run(),头都绕晕了.自从接触pytorch以来,一直想写点什么.曾经在2017年5月,Andrej Karpathy发表 ...
- 手写数字识别 卷积神经网络 Pytorch框架实现
MNIST 手写数字识别 卷积神经网络 Pytorch框架 谨此纪念刚入门的我在卷积神经网络上面的摸爬滚打 说明 下面代码是使用pytorch来实现的LeNet,可以正常运行测试,自己添加了一些注释, ...
- caffe_手写数字识别Lenet模型理解
这两天看了Lenet的模型理解,很简单的手写数字CNN网络,90年代美国用它来识别钞票,准确率还是很高的,所以它也是一个很经典的模型.而且学习这个模型也有助于我们理解更大的网络比如Imagenet等等 ...
- tensorflow笔记(四)之MNIST手写识别系列一
tensorflow笔记(四)之MNIST手写识别系列一 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7436310.html ...
- tensorflow笔记(五)之MNIST手写识别系列二
tensorflow笔记(五)之MNIST手写识别系列二 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7455233.html ...
- 深度学习之PyTorch实战(3)——实战手写数字识别
上一节,我们已经学会了基于PyTorch深度学习框架高效,快捷的搭建一个神经网络,并对模型进行训练和对参数进行优化的方法,接下来让我们牛刀小试,基于PyTorch框架使用神经网络来解决一个关于手写数字 ...
- 深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识 在tf第一个例子的时候需要很多预备知识. tf基本知识 香农熵 交叉熵代价函数cross-entropy 卷积神经网络 s ...
随机推荐
- SpringBoot课程学习(三)
一.YAML格式的基本语法 (1)格式: 大小写敏感 数据值前边必须有空格,作为分隔符 使用缩进表示层级关系 缩进时不允许使用Tab键,只允许使用空格(各个系统 Tab对应的 空格数目可能不同,导致层 ...
- Codeforces Round #822 (Div. 2) A-F
比赛链接 A 题解 知识点:贪心. 注意到任意三根木棍的相等最优解是最长减最小,因此从小到大排序,三个三个取,取最小值. 时间复杂度 \(O(n\log n)\) 空间复杂度 \(O(n)\) 代码 ...
- 计算机保研,maybe this is all you need(普通双非学子上岸浙大工程师数据科学项目)
写在前面 9.28接收了拟录取通知,也终究是尘埃落定了,我人生的又一个阶段也终于结束.面对最终录取结果,或多或少会有所遗憾,但也还是基本达到了预期的目标了. 作为在今年严峻的保研形势下幸存的我,一直想 ...
- Go_Goroutine详解
Goroutine详解 goroutine的概念类似于线程,但 goroutine是由Go的运行时(runtime)调度和管理的.Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU ...
- <一>关于进程虚拟地址空间区域内存划分和布局
C++代码在编译完成后会生产.exe程序(windows平台), .EXE以文件的形式存储在磁盘上,当运行.exe程序的时候 操作系统会将磁盘上的.exe文件加载到内存中,那么在加载到内存中的时候,操 ...
- Double数据运算过程中精度调整
Double数据进行运算时,容易出现多位小数的精度问题 ①问题现象 ②解决方案 使用BigDecimal类型来进行Double类型数据运算 创建BigDecimal类型对象时将Double类型的数据转 ...
- JDK 8之前日期和时间的API
JDK 8之前日期和时间的API(1) System类中的currentTimeMillis():返回当前时间与1970年1月1日0时0分0秒之间以毫秒为单位的时间差.称为时间戳. java.util ...
- Chrony时间同步服务
概: 网络时间协议(Network Time Protocol,NTP)是用于网络时间同步的协议.提供NTP时间同步服务的软件有很多,这里采用Chrony软件来实现时间同步 chrony 的优势: ...
- 2流高手速成记(之六):从SpringBoot到SpringCloudAlibaba
咱们接上回 2流高手速成记(之五):Springboot整合Shiro实现安全管理 - 14号程序员 - 博客园 (cnblogs.com) 身边常有朋友说:小项目用PHP.大项目用Java(这里绝无 ...
- mlflow详细安装部署
1.安装docker # 安装工具 sudo yum install -y yum-utils # 添加yum仓库配置 sudo yum-config-manager --add-repo https ...