Elastisearch在kibana下批量处理(mget和bulk)
一、批量查询
有点:能够大大减少网络的请求次数,减少网络开销
1、自定义设置index、type以及document id,进行查询
GET /_mget
{
"docs":[
{
"_index":"ecommerce",
"_type":"product",
"_id":1
},
{
"_index":"ecommerce",
"_type":"product",
"_id":2
}
]
}
查询结果,由于id唯一的document已经删除,所以查出id为2的文档

2、在对应的index、type下进行批量查询
注意:在ElasticSearch6.0以后一个index下只能有一个type,如果设置了多个type会报错:
GET ecommerce/product/_mget
{
"ids":[2,3]
}
或者
GET ecommerce/product/_mget
{
"docs":[
{
"_id":2
},
{
"_id":3
}
]
}
二、基于bulk的增删改
bulk语法:
- delete:删除一个文档,只要1个json串就可以了
- create:PUT /index/type/id/_create,强制创建
- index:普通的put操作,可以是创建文档,也可以是全量替换文档
- update:执行的partial update操作
注意点:
1、bulk api对json的语法有严格的要求,除了delete外,每一个操作都要两个json串,且每个json串内不能换行,非同一个json串必须换行,否则会报错
2、bulk操作中,任意一个操作失败,是不会影响其他的操作的,但是在返回结果里,会告诉你异常日志:
#index
{"index": {"metadata"}}
{"data"}
{"index": {"metadata"}}
{"data"}
#create
{"create": {"metadata"}}
{"data"}
{"create": {"metadata"}}
{"data"}
#update
{"update": {"metadata"}}
{"data"}
...
#delete
{"delete": {"metadata"}}
{"delete": {"metadata"}}
Bulk 一次请求 多次操作
1、批量创建,一个index,多个document
任意一个操作失败,是不会影响其他的操作的,但是在返回结果里,会告诉你异常日志:
POST _bulk
{ "index" : { "_index" : "test_index", "_type" : "test_type", "_id" : "1" } }
{ "uid":1,"age":21}
{ "index" : { "_index" : "test_index", "_type" : "test_type", "_id" : "2" } }
{ "uid":2,"age":22}
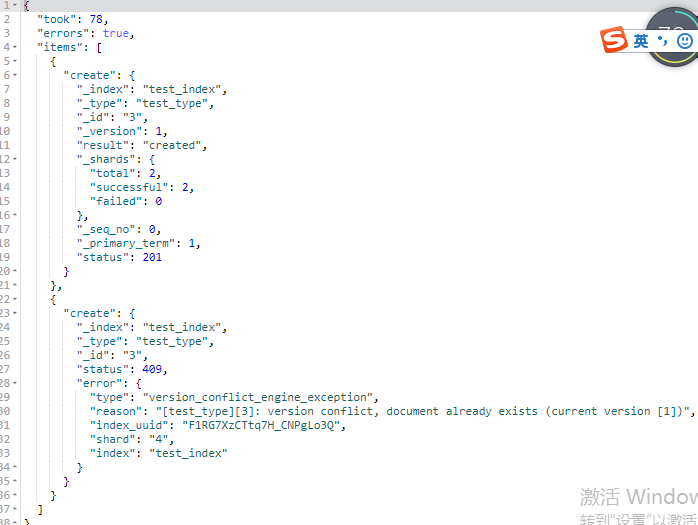
2、批量强制创建
任意一个操作失败,是不会影响其他的操作的,但是在返回结果里,会告诉你异常日志:
POST _bulk
{ "create" : { "_index" : "test_index", "_type" : "test_type", "_id" : "3" } }
{ "uid":3,"age":23}
{ "create" : { "_index" : "test_index", "_type" : "test_type", "_id" : "3" } }
{ "uid":3,"age":23}
3、修改
POST _bulk
{ "update" : {"_index" : "test_index", "_type" : "test_type", "_id" : "3"} }
{ "doc" : {"age" : 33} }
4、删除
删除一个文档,只要1个json串就可以了
POST _bulk
{ "delete" : { "_index" : "test_index", "_type" : "test_type", "_id" : "1" }}
{ "delete" : { "_index" : "test_index", "_type" : "test_type", "_id" : "5" }}
bulk api奇特的json格式
目前处理流程
直接按照换行符切割json,不用将其转换为json对象,不会出现内存中的相同数据的拷贝;
对每两个一组的json,读取meta,进行document路由;
直接将对应的json发送到node上去;
换成良好json格式的处理流程
将json数组解析为JSONArray对象,这个时候,整个数据,就会在内存中出现一份一模一样的拷贝,一份数据是json文本,一份数据是JSONArray对象;
解析json数组里的每个json,对每个请求中的document进行路由;
为路由到同一个shard上的多个请求,创建一个请求数组;
将这个请求数组序列化;
将序列化后的请求数组发送到对应的节点上去;
奇特格式的优缺点
缺点:可读性差;
优点:不需要将json数组解析为一个JSONArray对象,形成一份大数据的拷贝,浪费内存空间,能够尽可能地保证性能;
例如:
bulk size最佳大小一般建议说在几千条,大小在10MB左右。假设说现在100个bulk请求发送到了一个节点上去,然后每个请求是10MB,100个请求,就是1000MB = 1GB,然后每个请求的json都copy一份为jsonarray对象,此时内存中的占用就会翻倍,就会占用2GB的内存,甚至还不止。因为弄成jsonarray之后,还可能会多搞一些其他的数据结构,2GB+的内存占用。
占用更多的内存可能就会积压其他请求的内存使用量,比如说最重要的搜索请求,分析请求,等等,此时就可能会导致其他请求的性能急速下降。
另外的话,占用内存更多,就会导致java虚拟机的垃圾回收次数更多,跟频繁,每次要回收的垃圾对象更多,耗费的时间更多,导致es的java虚拟机停止工作线程的时间更多。
Elastisearch在kibana下批量处理(mget和bulk)的更多相关文章
- Elastisearch在kibana下常用命令总结
1.获取所有数据 GET /_search 2.创建一个Document PUT /ecommerce/product/1 { "name" : "gaolujie ya ...
- shell下批量重命名svn文件的方法
shell下批量重命名svn文件的方法 目标: 将svn目录下所有文件重命名 , 原文件前缀为 ucc_ , 批量改为 xmd_ 用tree看下当前svn目录 ucc_1.c ucc_1.h ucc_ ...
- 06_Elasticsearch 批量获取mget
06_Elasticsearch 批量获取mget 现在有: http://192.168.32.81:9200/bank/bank_account/1 http://192.168.32.81:92 ...
- Linux下批量管理工具pssh安装和使用
Linux下批量管理工具pssh安装和使用 pssh工具包 安装:yum -y install pssh pssh:在多个主机上并行地运行命令 pscp:把文件并行地复制到多个主机上 prsync:通 ...
- Elasticsearch学习笔记(十)批量查询mget、批量增删改bulk
一.批量查询 mget GET /_mget { "docs":[ { "_index":" ...
- python实现指定目录下批量文件的单词计数:并发版本
在 文章 <python实现指定目录下批量文件的单词计数:串行版本>中, 总体思路是: A. 一次性获取指定目录下的所有符合条件的文件 -> B. 一次性获取所有文件的所有文件行 - ...
- Linux 下批量创建用户(shell 命令)
第一种方法: 用shell批量创建用户,分为2中:1,批量创建的用户名无规律 :2.批量创建的用户名有规律首先,来说下批量创建的用户名无规律的shell:先把需要批量创建的用户名用一个文本文档列出来, ...
- Linux下批量修改文件及文件夹所有者及权限
Linux下批量修改文件及文件夹所有者及权限需要使用到两个命令,chmod以及chown 例:对/opt/Oracle/目录下的所有文件与子目录执行相同的权限变更: chmod -R 700 /opt ...
- Linux下批量删除空文件
Linux下批量删除空文件(大小等于0的文件)的方法 find . -name "*" -type f -size 0c | xargs -n 1 rm -f 用这个还能够删除指定 ...
随机推荐
- java课后作业2019.11.04
一.编写一个程序,指定一个文件夹,能够自动计算出其总容量 1.代码 package HomeWork; import java.io.File; public class getFileDaxiao ...
- iOS崩溃日志 如何看
日志主要分为六个部分:进程信息.基本信息.异常信息.线程回溯.线程状态和二进制映像. 我们在进行iPhone应用测试时必然会在"隐私"中找到不少应用的崩溃日志,但是不会阅读对于很多 ...
- 几句话说明 .NET MVC中ViewData, ViewBag和TempData的区别
ViewData和TempData是字典类型,赋值方式用字典方式, ViewData["myName"] ViewBag是动态类型,使用时直接添加属性赋值即可 ViewBag.my ...
- JDBC(一)—— JDBC概述
Jdbc概述 Java DataBase connectivity(Java语言连接数据库) Jdbc本质是什么? 是Sun公司制定的一套接口,java.sql.* 接口都有调用者和实现者 面向接口调 ...
- web移动端css reset
通用版css reset,pc端使用只需要修改html{font-size: 10px;}为html{font-size: 12px;} @charset "utf-8"; htm ...
- html5shiv.js和respond.min.js作用说明(IE9及以下兼容)
一.在web端页面开发过程中基本都会需要解决的问题(IE兼容): 1.解决ie9以下浏览器对html5新增标签的不识别,并导致CSS不起作用的问题. 2.让不支持css3 Media Query的浏览 ...
- 通过CSS绘制五星红旗
任务要求: 1.创建一个div作为红旗旗面,用CSS控制其比例宽高比为3:2,背景为红色. 2.再创建五个小的div,用CSS控制其大小和位置. 3.用CSS同时控制每个小div的大小.边框和位置,同 ...
- docker下安装svn-server
参考资料,搭建过程比较详细:https://www.jianshu.com/p/a25fac7e7811 我按照上面资料搭建后,将其重新制作成了新的镜像theorydance/svn-server:1 ...
- 前端魔法堂:可能是你见过最详细的WebWorker实用指南
前言 JavaScript从使用开初就一直基于事件循环的单线程运行模型,即使是成功进军后端开发的Nodejs也没有改变这一模型.那么对于计算密集型的应用,我们必须创建新进程来执行运算,然后执行进程间通 ...
- html 02-浏览器的介绍
02-浏览器的介绍 #常见的浏览器 浏览器是网页运行的平台,常见的浏览器有谷歌(Chrome).Safari.火狐(Firefox).IE.Edge.Opera等.如下图所示: 我们重点需要学习的是 ...