Scrapy 项目:腾讯招聘
目的:
通过爬取腾讯招聘网站(https://careers.tencent.com/search.html)练习Scrapy框架的使用
步骤:
1、通过抓包确认要抓取的内容是否在当前url地址中,测试发现内容不在当前url中并且数据格式为json字符串
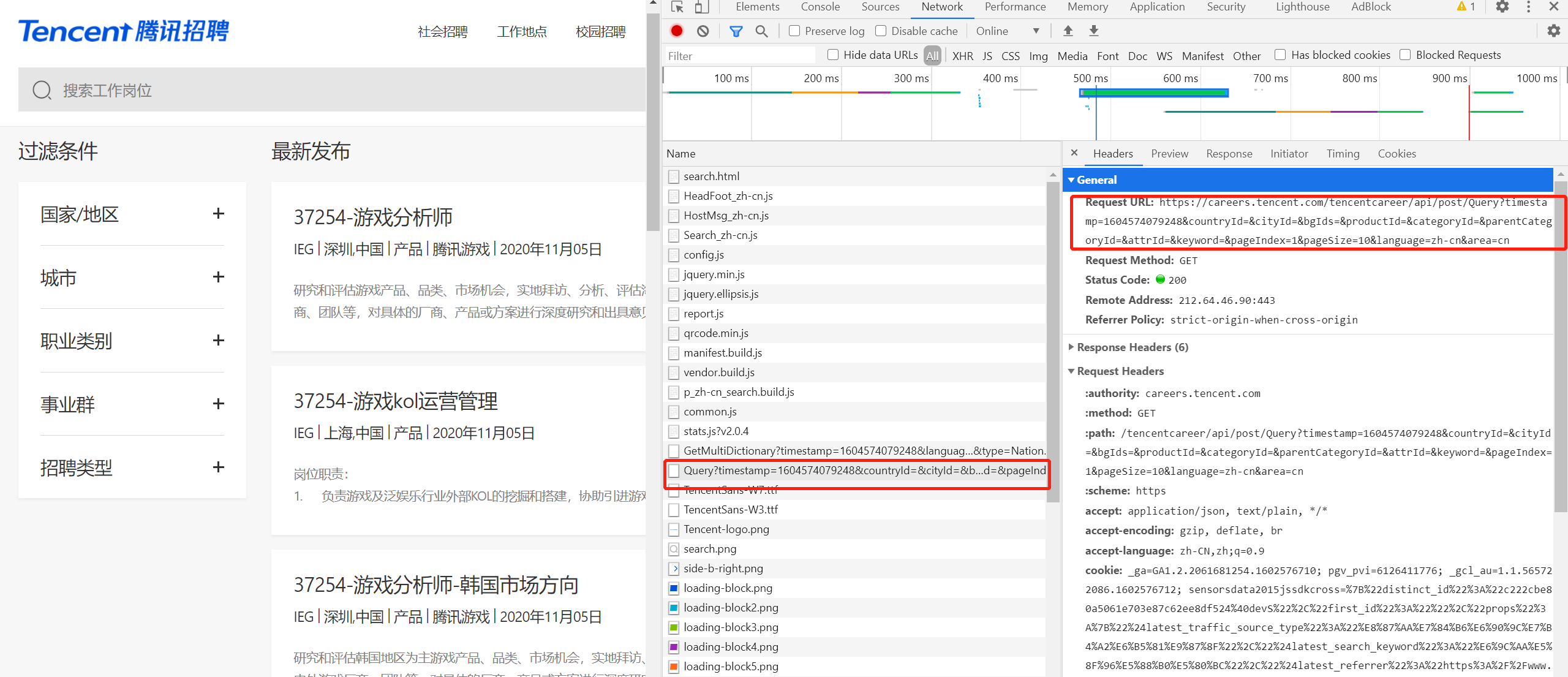
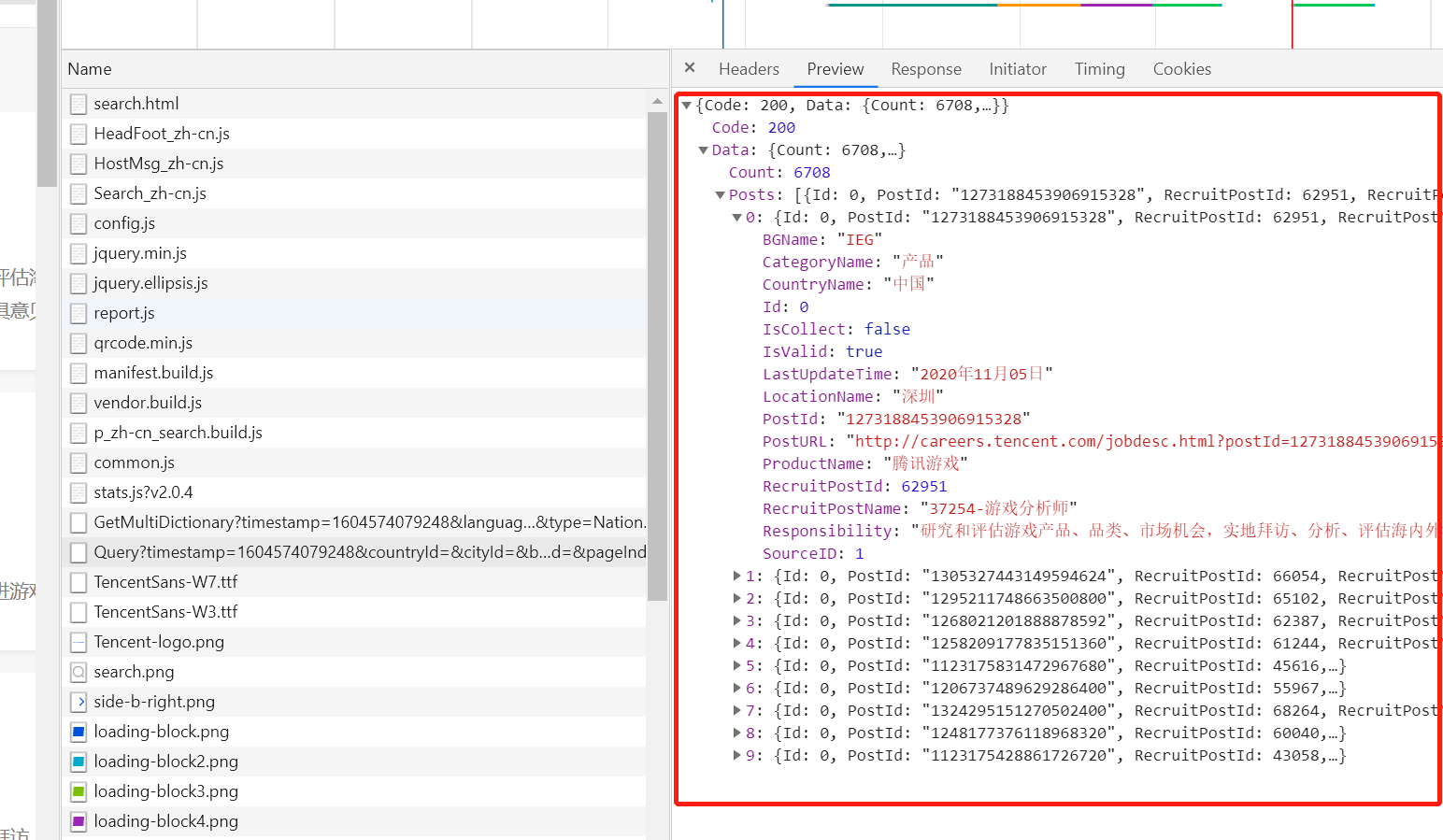
2、请求url地址过长,考虑去除某些部分,经测试得到
'https://careers.tencent.com/tencentcareer/api/post/Query?keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn'
3、寻找url地址,pageIndex=页码,可构造爬虫循环的URL列表
4、书写爬虫代码
- scrapy startproject tencent tencent.com
- cd tencent.com
- scrapy genspider hr tencent.com
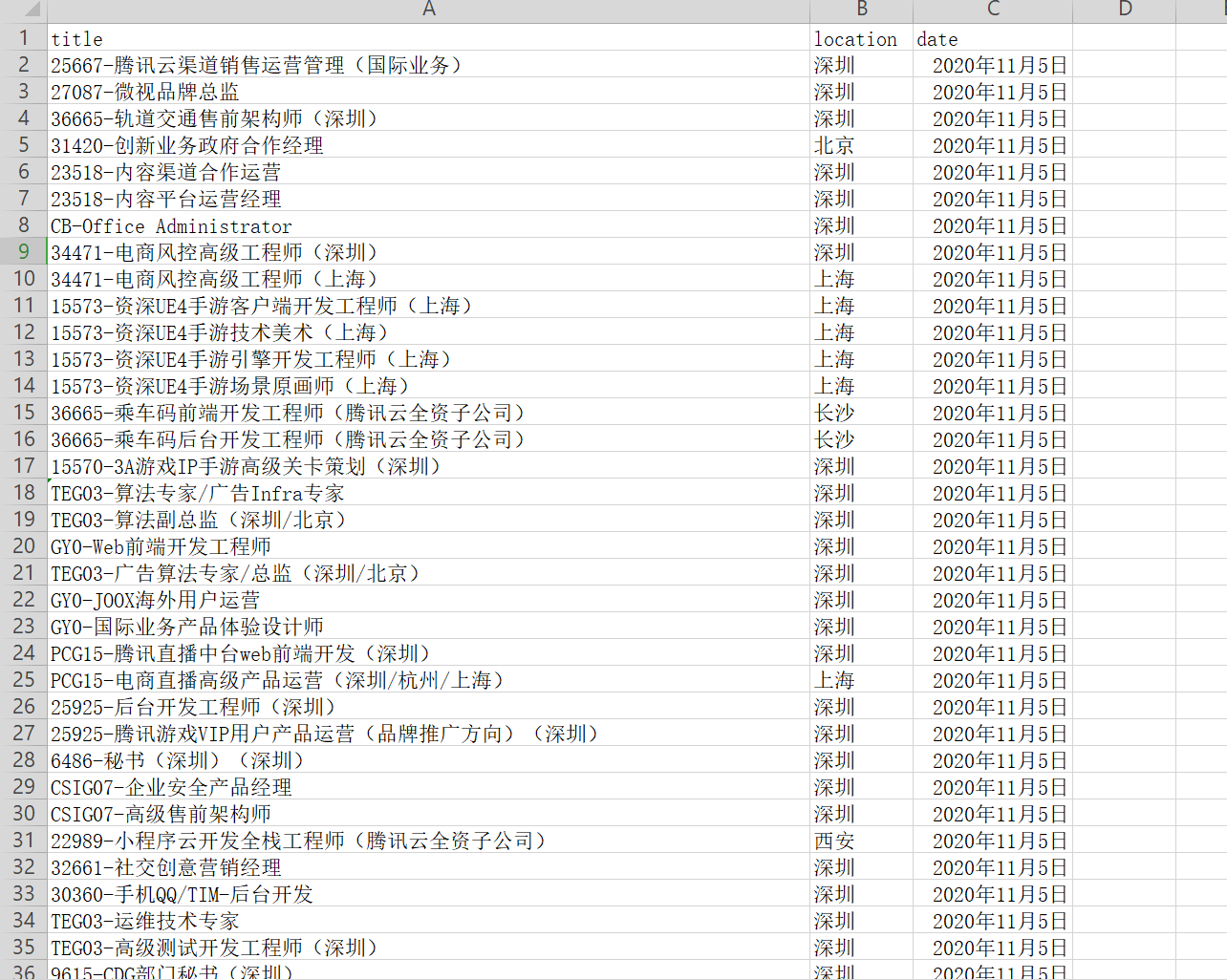
5、保存为CSV文件
1 import scrapy
2 import json
3
4
5 class HrSpider(scrapy.Spider):
6 name = 'hr'
7 allowed_domains = ['tencent.com']
8 start_urls = ['https://careers.tencent.com/tencentcareer/api/post/Query?keyword=&pageIndex=1&pageSize=10&language'
9 '=zh-cn&area=cn']
10 url = 'https://careers.tencent.com/tencentcareer/api/post/Query?keyword=&pageIndex={' \
11 '}&pageSize=10&language=zh-cn&area=cn '
12 pageIndex = 1
13
14 def parse(self, response):
15 json_str = json.loads(response.body)
16 for content in json_str["Data"]["Posts"]:
17 content_dic = {"title": content["RecruitPostName"], "location": content["LocationName"],
18 "date": content["LastUpdateTime"]}
19 print(content_dict)20
yield content_dic
21
23 if self.pageIndex < 10:
24 self.pageIndex += 1
25 next_url = self.url.format(self.pageIndex)
26 yield scrapy.Request(url=next_url, callback=self.parse)
运行爬虫
- scrapy crawl hr
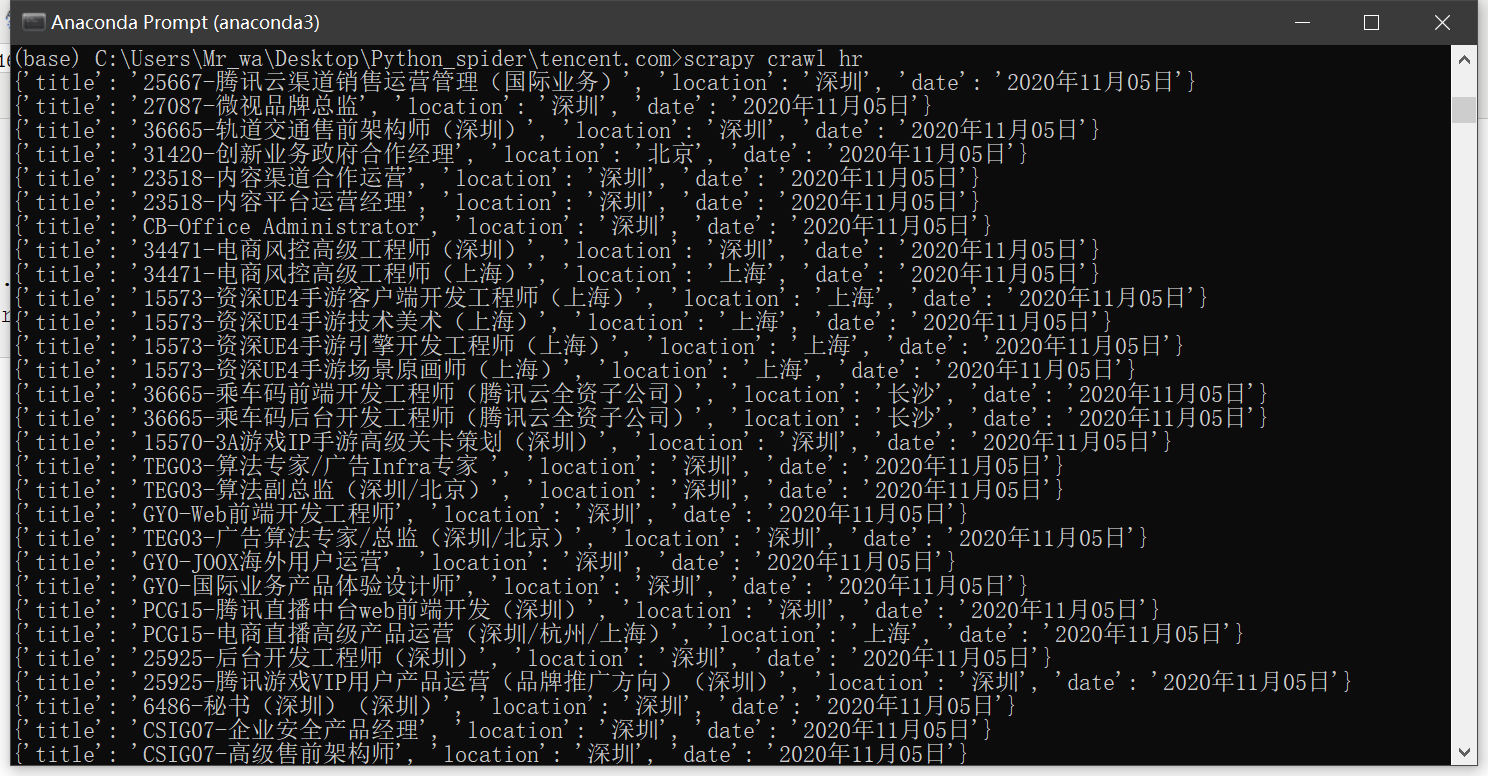
保存命令
- scrapy crawl hr -o tencent.csv
Scrapy 项目:腾讯招聘的更多相关文章
- Scrapy实现腾讯招聘网信息爬取【Python】
一.腾讯招聘网 二.代码实现 1.spider爬虫 # -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentIte ...
- Scrapy:腾讯招聘整站数据爬取
项目地址:https://hr.tencent.com/ 步骤一.分析网站结构和待爬取内容 以下省略一万字 步骤二.上代码(不能略了) 1.配置items.py import scrapy class ...
- Scrapy案例02-腾讯招聘信息爬取
目录 1. 目标 2. 网站结构分析 3. 编写爬虫程序 3.1. 配置需要爬取的目标变量 3.2. 写爬虫文件scrapy 3.3. 编写yield需要的管道文件 3.4. setting中配置请求 ...
- Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计
通过使Scrapy框架,进行数据挖掘和对web站点页面提取结构化数据,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 数据简析 - 实现腾讯网站社会招聘信息爬取的爬虫设计
一.数据分析截图 本例实验,使用Weka 3.7对腾讯招聘官网中网页上所罗列的招聘信息,如:其中的职位名称.链接.职位类别.人数.地点和发布时间等信息进行数据分析,详见如下图: 图1-1 Weka ...
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- python爬虫scrapy项目详解(关注、持续更新)
python爬虫scrapy项目(一) 爬取目标:腾讯招聘网站(起始url:https://hr.tencent.com/position.php?keywords=&tid=0&st ...
- pymongodb的使用和一个腾讯招聘爬取的案例
一.在python3中操作mongodb 1.连接条件 安装好pymongo库 启动mongodb的服务端(如果是前台启动后就不关闭窗口,窗口关闭后服务端也会跟着关闭) 3.使用 import pym ...
- 亲测——pycharm下运行第一个scrapy项目 ©seven_clear
最近在学习scrapy,就想着用pycharm调试,但不知道怎么弄,从网上搜了很多方法,这里总结一个我试成功了的. 首先当然是安装scrapy,安装教程什么的网上一大堆,这里推荐一个详细的:http: ...
随机推荐
- UML——活动图
宏观导图 是森马? 活动图,属于UML中动态建模工具图,它描述活动的顺序,展现从一个活动到另一个活动的控制流.活动图着重表现从一个活动到另一个活动的控制流,是内部处理驱动的流程. 其实,说白了 ...
- TCP/IP__IP寻址及ARP解析
ARP解析过程中MAC地址以及IP地址的变化情况 1.两主机要通信传送数据时,就要把应用数据封装成IP包,然后再交给下一层数据链路层继续封装成帧:之后根据MAC地址才能把数据从一台主机,准确无误的传送 ...
- 如何将下载到本地的JAR包手动添加到Maven仓库,妈妈再也不用担心我下载不下来依赖啦
我们有时候使用maven下载jar包的时候,可能maven配置都正确,但是部分jar包就是不能下载下来,如果maven设置都不正确的,可以查看我的maven系列文章,这里仅针对maven配置正确,但是 ...
- Codeforces Round #589 (Div. 2) D. Complete Tripartite(模拟)
题意:给你n个点 和 m条边 问是否可以分成三个集合 使得任意两个集合之间的任意两个点都有边 思路:对于其中一个集合v1 我们考虑其中的点1 假设点u和1无边 那么我们可以得到 u一定和点1在一个集合 ...
- Codeforces Round #627 (Div. 3) D - Pair of Topics(双指针)
题意: 有长为n的a,b两序列,问满足ai+aj>bi+bj(i<j)的i,j对数. 思路: 移项得:(ai-bi)+(aj-bj)>0,i<j即i!=j,用c序列保存所有ai ...
- Codeforces Round #647 (Div. 2) D. Johnny and Contribution(BFS)
题目链接:https://codeforces.com/contest/1362/problem/D 题意 有一个 $n$ 点 $m$ 边的图,每个结点有一个从 $1 \sim n$ 的指定数字,每个 ...
- zjnu1707 TOPOVI (map+模拟)
Description Mirko is a huge fan of chess and programming, but typical chess soon became boring for h ...
- c语言实现--带头结点单链表操作
可能是顺序表研究的细致了一点,单链表操作一下子就实现了.这里先实现带头结点的单链表操作. 大概有以下知识点. 1;结点:结点就是单链表中研究的数据元素,结点中存储数据的部分称为数据域,存储直接后继地址 ...
- Codeforces Round #648 (Div. 2) F. Swaps Again
题目链接:F.Swaps Again 题意: 有两个长度为n的数组a和数组b,可以选择k(1<=k<=n/2)交换某一个数组的前缀k和后缀k,可以交换任意次数,看最后是否能使两个数组相等 ...
- Codeforces Round #672 (Div. 2) D. Rescue Nibel! (思维,组合数)
题意:给你\(n\)个区间,从这\(n\)区间中选\(k\)个区间出来,要求这\(k\)个区间都要相交.问共有多少种情况. 题解:如果\(k\)个区间都要相交,最左边的区间和最右边的区间必须要相交,即 ...