基于tcp的应用层消息边界如何定义
聊聊基于tcp的应用层消息边界如何定义

背景
2018年笔者有幸接触一个项目要用到长连接实现云端到设备端消息推送,所以借机了解过相关的内容,最终是通过rabbitmq+mqtt实现了相关功能,同时在心里也打了一个问号“如果自己实现长连接框架,该怎么定义消息的边界呢?”,之后断断续续整理了一些,一直不成体系,最近放假了整理出来跟大家交流一番。
为什么需要消息边界
消息边界并非长连接场景才需要,即使是短连接也可能需要,拿我们比较常用的http1.0协议(http1.1稍微复杂一些,后面会单独说)来说,它基于tcp这个传输协议来传递消息,而tcp协议又是一个面向流的协议,怎么能识别出已经到了流的末尾呢?我们需要一种规则来定义消息的边界,告诉对方读取已经到了末尾,可以结束了。
举一个生活中的例子来帮助理解,2020年由于疫情的原因,平日里都是在线下会议室开会,特殊时期演变成了线上会议。不知道大家有没有遇到过这种情况,线下开会时通过观察别人的动作、神情很容易知道他说完了,这时候下一个人就可以接着发言了,但是线上开会时这样就行不通了,你如果想发言是不是得先确认下别人有没有说完,如果直接发言可能会打断别人,这样很不礼貌,为什么会出现这种情况呢?因为你不知道他到底有没有结束发言,更专业一点说你不知道是否到达了消息的边界。那怎么改进呢,如果每个人发言完毕都显示的告诉别人“我说完了”,是不是会好一些呢,“我说完了”这四个字就是一种消息的边界,给接收方传达一种消息结束的讯息。
TCP层面的分析
(本节来源于https://netty.io/wiki/user-guide-for-4.x.html#wiki-h3-10)
在基于流的传输(例如TCP / IP)中,将接收到的数据存储到套接字接收缓冲区中。不幸的是,基于流的传输的缓冲区不是数据包队列而是字节队列。这意味着,即使您将两个消息作为两个独立的数据包发送,操作系统也不会将它们视为两个消息,而只是一堆字节。因此,不能保证读取的内容与远端写的完全一样。例如,假设操作系统的TCP / IP栈已收到三个数据包:
由于是基于流的协议,因此很有可能在应用程序中读到以下四个分段:

因此,无论是服务器端还是客户端,接收方都应将接收到的数据整理到一个或多个有意义的帧中,以使应用程序逻辑易于理解。在上面的示例中,正确的数据应采用以下格式:
消息边界的种类
前面介绍了消息边界的定义以及作用,这一节我们来看看大概会有哪几种消息边界。
1.特殊字符:比如上面提到的“我说完了”这就是一种特殊字符作为消息边界的例子,以特殊字符为边界的典型产品有我们熟知的redis,客户端和服务器发送的命令或数据一律以 \r\n (CRLF)结尾,还有Netty中的DelimiterBasedFrameDecoder。
2.基于消息长度:比如约定了消息长度为4k字节,接收方每次读取4k字节以后就认为已到达消息边界,结束本次读取。当然现实中消息长度一般是变长的,这样就需要设计一个约定好的消息头部,将消息长度作为头部的一部分传输过去,以长度为边界的例子有Dubbo、http
、websocket,Netty中的FixedLengthFrameDecoder、LengthFieldBasedFrameDecoder等。
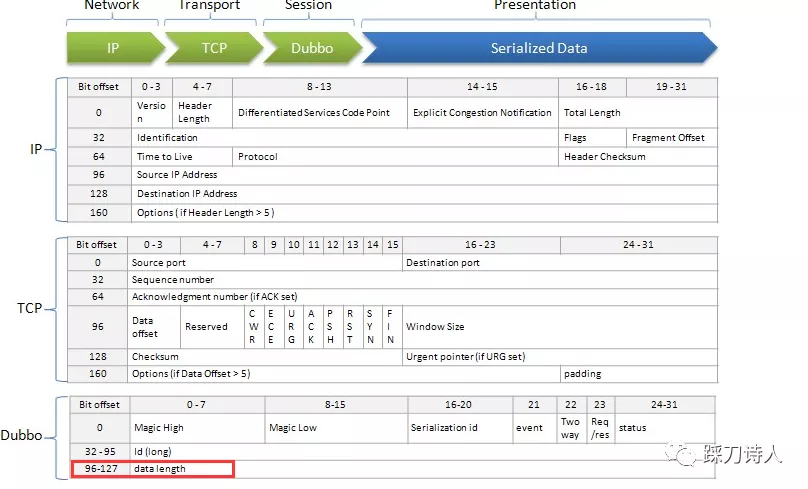
附上一张dubbo协议头,供大家体会
redis如何解析完整消息
上面说过,redis是通过\r\n来作为消息边界的,下面我将从源码角度分析下redis具体是如何处理的。
1.这里通过telnet来发送内联格式命令请求redis,之所以没有选用redis-cli是想模拟一条指令redis-server分多次收到的情况,在telnet模式下,每输入一个字符,就会发送给redis-server端,而redis-cli不是,它是按下回车时才会发送整体输入的命令,redis-server端是分多次还是一次收到完整的命令,这个取决于底层,如果想模拟分多次收到,这个过程较为复杂。
2.redis-server端每次有输入时会触发readQueryFromClient(networking.c)函数,对redis执行流程感兴趣的可以参考我之前的文章“redis源码学习之工作流程初探”。
3.redis-server将收到的内容暂存到redisClient的querybuf中,如果没有收到\r\n就等待,直到收到\r\n才将querybuf中的内容解析成指令执行。
测试步骤如下:
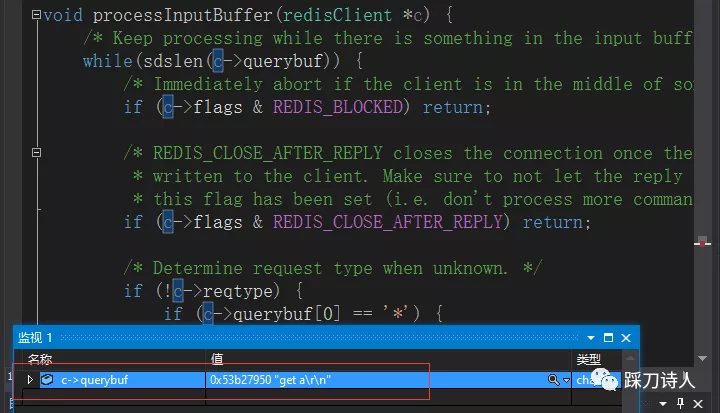
- telnet 中输入g

- debug查看redisClient中querybuf的值,目前只有g

- telnet中输完get a按回车以后,redisClient中querybuf保存了所有的输入get a \r\n
源码分析如下:
readQueryFromClient
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
redisClient *c = (redisClient*) privdata;
int nread, readlen;
size_t qblen;
REDIS_NOTUSED(el);
REDIS_NOTUSED(mask);
server.current_client = c;
readlen = REDIS_IOBUF_LEN;
/* If this is a multi bulk request, and we are processing a bulk reply
* that is large enough, try to maximize the probability that the query
* buffer contains exactly the SDS string representing the object, even
* at the risk of requiring more read(2) calls. This way the function
* processMultiBulkBuffer() can avoid copying buffers to create the
* Redis Object representing the argument. */
if (c->reqtype == REDIS_REQ_MULTIBULK && c->multibulklen && c->bulklen != -1
&& c->bulklen >= REDIS_MBULK_BIG_ARG)
{
int remaining = (int)((unsigned)(c->bulklen+2)-sdslen(c->querybuf));
if (remaining < readlen) readlen = remaining;
}
qblen = sdslen(c->querybuf);
if (c->querybuf_peak < qblen) c->querybuf_peak = qblen;
c->querybuf = sdsMakeRoomFor(c->querybuf, readlen);
//从fd中读取内容,读取的内容存到redisClient的querybuf中
nread = read(fd, c->querybuf+qblen, readlen);
if (nread == -1) {
if (errno == EAGAIN) {
nread = 0;
} else {
#ifdef _WIN32
redisLog(REDIS_VERBOSE, "Reading from client: %s",wsa_strerror(errno));
#else
redisLog(REDIS_VERBOSE, "Reading from client: %s",strerror(errno));
#endif
freeClient(c);
return;
}
} else if (nread == 0) {
redisLog(REDIS_VERBOSE, "Client closed connection");
freeClient(c);
return;
}
#ifdef WIN32_IOCP
aeWinReceiveDone(fd);
#endif
if (nread) {
sdsIncrLen(c->querybuf,nread);
c->lastinteraction = server.unixtime;
if (c->flags & REDIS_MASTER) c->reploff += nread;
} else {
server.current_client = NULL;
return;
}
if (sdslen(c->querybuf) > server.client_max_querybuf_len) {
sds ci = getClientInfoString(c), bytes = sdsempty();
bytes = sdscatrepr(bytes,c->querybuf,64);
redisLog(REDIS_WARNING,"Closing client that reached max query buffer length: %s (qbuf initial bytes: %s)", ci, bytes);
sdsfree(ci);
sdsfree(bytes);
freeClient(c);
return;
}
//正常的读取,继续执行processInputBuffer
processInputBuffer(c);
server.current_client = NULL;
}
processInputBuffer
void processInputBuffer(redisClient *c) {
/* Keep processing while there is something in the input buffer */
while(sdslen(c->querybuf)) {
/* Immediately abort if the client is in the middle of something. */
if (c->flags & REDIS_BLOCKED) return;
/* REDIS_CLOSE_AFTER_REPLY closes the connection once the reply is
* written to the client. Make sure to not let the reply grow after
* this flag has been set (i.e. don't process more commands). */
if (c->flags & REDIS_CLOSE_AFTER_REPLY) return;
/* Determine request type when unknown. */
//判断协议类型,如果是*开头的就是redis的统一请求协议,否则就是内联协议
if (!c->reqtype) {
if (c->querybuf[0] == '*') {
c->reqtype = REDIS_REQ_MULTIBULK;
} else {
c->reqtype = REDIS_REQ_INLINE;
}
}
//走内联协议的处理函数processInlineBuffer
if (c->reqtype == REDIS_REQ_INLINE) {
//如果命令不完整或者解析失败,不会执行命令
if (processInlineBuffer(c) != REDIS_OK) break;
} else if (c->reqtype == REDIS_REQ_MULTIBULK) {
if (processMultibulkBuffer(c) != REDIS_OK) break;
} else {
redisPanic("Unknown request type");
}
/* Multibulk processing could see a <= 0 length. */
if (c->argc == 0) {
resetClient(c);
} else {
/* Only reset the client when the command was executed. */
//命令解析完成,执行具体的命令对应的函数
if (processCommand(c) == REDIS_OK)
resetClient(c);
}
}
}
processInlineBuffer
int processInlineBuffer(redisClient *c) {
char *newline;
int argc, j;
sds *argv, aux;
size_t querylen;
/* Search for end of line */
newline = strchr(c->querybuf,'\n');
/* Nothing to do without a \r\n */
//最后一个字符不是\n,返回REDIS_ERR,说明命令不完整,继续等待
if (newline == NULL) {
if (sdslen(c->querybuf) > REDIS_INLINE_MAX_SIZE) {
addReplyError(c,"Protocol error: too big inline request");
setProtocolError(c,0);
}
return REDIS_ERR;
}
/* Handle the \r\n case. */
//继续判断是否是以\r\n结尾的,如果是就截取\r\n前面的内容为参数
if (newline && newline != c->querybuf && *(newline-1) == '\r')
newline--;
/* Split the input buffer up to the \r\n */
querylen = newline-(c->querybuf);
aux = sdsnewlen(c->querybuf,querylen);
argv = sdssplitargs(aux,&argc);
sdsfree(aux);
if (argv == NULL) {
addReplyError(c,"Protocol error: unbalanced quotes in request");
setProtocolError(c,0);
return REDIS_ERR;
}
/* Newline from slaves can be used to refresh the last ACK time.
* This is useful for a slave to ping back while loading a big
* RDB file. */
if (querylen == 0 && c->flags & REDIS_SLAVE)
c->repl_ack_time = server.unixtime;
/* Leave data after the first line of the query in the buffer */
sdsrange(c->querybuf,querylen+2,-1);
/* Setup argv array on client structure */
if (c->argv) zfree(c->argv);
c->argv = zmalloc(sizeof(robj*)*argc);
/* Create redis objects for all arguments. */
for (c->argc = 0, j = 0; j < argc; j++) {
if (sdslen(argv[j])) {
c->argv[c->argc] = createObject(REDIS_STRING,argv[j]);
c->argc++;
} else {
sdsfree(argv[j]);
}
}
zfree(argv);
return REDIS_OK;
}
Netty FixedLengthFrameDecoder、LengthFieldBasedFrameDecoder如何解析完整消息
有兴趣的小伙伴可以看看FixedLengthFrameDecoder、LengthFieldBasedFrameDecoder源码的java doc说明,里面讲的比较详细,在此不再重复。
总结
网络上其他作者将这类问题称之为TCP“粘包”和“拆包”,与本文提到的消息边界本质上没有太多区别,之所以没有继续叫“拆包”是不想把概念复杂化,回到本质其实就是需要一种机制来定义消息的边界,帮助应用层来正确的解析消息。
通过redis源码的简单分析,大体可以得到解决这类问题的关键点有以下两步:
1.需要一种边界的定义,基于特殊字符、基于长度等;
2.消息接收端需要暂存收到的内容,不到边界时等待,直到符合边界条件(收到了特殊字符或者收到的字节数达到约定的长度)。
虽说不是一个高大上的知识点,但是通过查资料和阅读源码也解决了心中的困惑,过程中通过发散式的学习也了解到Netty框架针对这类问题的解决方案,算是对Netty的认识又深入了一点。

基于tcp的应用层消息边界如何定义的更多相关文章
- 构建基于TCP的应用层通信模型
各层的关系如下图,表述的是两个应用或CS间通信的过程: 通常使用TCP构建应用时,需要考虑传输层的通信协议,以便应用层能够正确识别消息请求.比如,一个请求的内容很长(如传文件),那肯定要分多次发送 ...
- TCP和UDP的"保护消息边界" (经典)
在socket网络程序中,TCP和UDP分别是面向连接和非面向连接的.因此TCP的socket编程,收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有 ...
- 基于TCP/IP协议的C++网络编程(API函数版)
源代码:http://download.csdn.net/detail/nuptboyzhb/4169959 基于TCP/IP协议的网络编程 定义变量——获得WINSOCK版本——加载WINSOCK库 ...
- 介绍开源的.net通信框架NetworkComms框架之四 消息边界
原文网址: http://www.cnblogs.com/csdev Networkcomms 是一款C# 语言编写的TCP/UDP通信框架 作者是英国人 以前是收费的 目前作者已经开源 许可是 ...
- UDP TCP 消息边界
先明确一个问题,如果定义了一个数据结构,大小是,比方说 32 个字节,然后 UDP 客户端连续向服务端发了两个包.现在假设这两个包都已经到达了服务器,那么服务端调用 recvfrom 来接收数据,并且 ...
- Mina、Netty、Twisted一起学(二):TCP消息边界问题及按行分割消息
在TCP连接开始到结束连接,之间可能会多次传输数据,也就是服务器和客户端之间可能会在连接过程中互相传输多条消息.理想状况是一方每发送一条消息,另一方就立即接收到一条,也就是一次write对应一次rea ...
- TCP和UDP的保护消息边界机制
在socket网络程序中,TCP和UDP分别是面向连接和非面向连接的.TCP的socket编程,收发两端都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化 ...
- TCP和UDP的"保护消息边界”
转自:http://blog.csdn.net/zhangxinrun/article/details/6721427 在socket网络程序中,TCP和UDP分别是面向连接和非面向连接的.因此TCP ...
- Fixed-Length Frames 谈谈网络编程中应用层(基于TCP/UDP)的协议设计
http://blog.sina.com.cn/s/blog_48d4cf2d0101859x.html 谈谈网络编程中应用层(基于TCP/UDP)的协议设计 (2013-04-27 19:11:00 ...
随机推荐
- 通过jenkins构建服务,并发布服务,修改Jenkins以Root用户运行
通过jenkins构建服务,并发布服务,修改Jenkins以Root用户运行 其他博文:从0到1体验Jenkins+Docker+Git+Registry实现CI自动化发布 Jenkins注册中心 一 ...
- cassandra权威指南读书笔记--安全
认证和授权driver,JMX和cassandra服务器支持SSL/TLS,cassandra节点间也支持SSL/TLS.密码认证器cassandra还支持自定义,可插拔的认证机制.默认的认证器:or ...
- 2019 Multi-University Training Contest 7 Kejin Player(期望)
题意:给定在当前等级升级所需要的花费 每次升级可能会失败并且掉级 然后q次询问从l到r级花费的期望 思路:对于单次升级的期望 我们可以列出方程: 所以我们可以统计一下前缀和 每次询问O1回答 #inc ...
- 2020牛客暑期多校训练营(第二场)Fake Maxpooling
传送门:Fake Maxpooling 题意:给出矩阵的行数n和列数m,矩阵 Aij = lcm( i , j ) ,求每个大小为k*k的子矩阵的最大值的和. 题解:如果暴力求解肯定会t,所以要智取 ...
- hdu3565 Bi-peak Number (有上界和下界的数位dp)
Problem Description A peak number is defined as continuous digits {D0, D1 - Dn-1} (D0 > 0 and n & ...
- Codeforces Round #555 (Div. 3) E. Minimum Array (贪心,二分,set)
题意:给你两个长度为\(n\)的数组\(a\)和\(b\),元素值在\([0,n-1]\),可以对\(b\)数组的元素任意排序,求新数组\(c\),满足\(c_i=(a_i+b_i)\ mod\ n\ ...
- Codeforces Round #643 (Div. 2) E. Restorer Distance (贪心,三分)
题意:给你\(n\)个数,每次可以使某个数++,--,或使某个数--另一个++,分别消耗\(a,r,m\).求使所有数相同最少的消耗. 题解:因为答案不是单调的,所以不能二分,但不难发现,答案只有一个 ...
- servlet相关知识点
一.servlet的生命周期 Servlet(Sever Applet),全称是Java Servlet,是用java编写的服务器程序.Servlet是指任何实现了这个Servlet接口的类. ser ...
- UML类图设计神器 AmaterasUML 的配置及使用
最近写论文需要用到UML类图,但是自己画又太复杂,干脆找了个插件,是Eclipse的,也有IDEA的,在这里我简单说下Eclipse的插件AmaterasUML 的配置与使用吧. 点击这里下载Amat ...
- 前端接收后端文件流导出excel文档遇到的问题
先上代码: Vue.prototype.download = function(oUrl, filename) { this.axios .get(oUrl, { responseType: 'arr ...