轻量级CNN模型之squeezenet
SqueezeNet
论文地址:https://arxiv.org/abs/1602.07360
和别的轻量级模型一样,模型的设计目标就是在保证精度的情况下尽量减少模型参数.核心是论文提出的一种叫"fire module"的卷积方式.
设计策略

- 主要用1x1卷积核,而不是3x3.
- 减少3x3卷积核作用的channel.
- 推迟下采样的时间.以获取更大尺寸的feature map.这一点是处于精度的考虑.毕竟feature map的resolution越大,信息越丰富.下采样主要通过pool来完成或者卷积的时候控制stride大小.
Fire Module
这个就是网络的核心组件了.
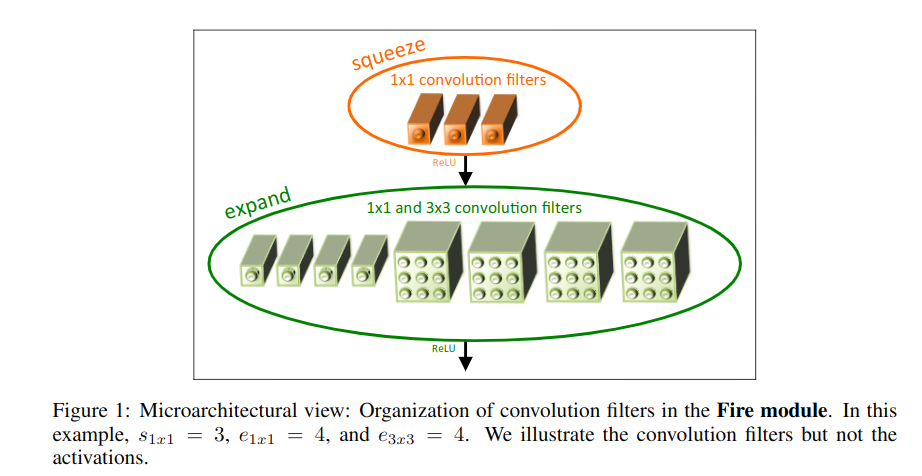
分2部分:
- squeeze convolution layer
- expand layer
其中squeeze只有1x1filter,expand layer由1x1和3x3filter组成.
在squeeze层卷积核数记为\(s_{1x1}\),在expand层,记1x1卷积核数为\(e_{1x1}\),而3x3卷积核数为\(e_{3x3}\),这三个属于超参数,可调。为了尽量降低3x3的输入通道数,让\(s_{1x1}<e_{1x1}+e_{3x3}\)。
这两层的设计分别体现了策略1(多用1x1filter)和策略2(减少3x3filter作用channel).
首先,squeeze convolution layer通过控制1x1卷积核数量达到把输入的channel数目降低的目的.这个是降低参数的最关键的一步.
然后,分别用1x1卷积核和3x3卷积核去做卷积.然后得到不同depth的输出,concat起来.([x,x,depth1],[x,x,depth2]-->[x,x,depth1+depth2])
代码实现
torch的官方实现:https://pytorch.org/docs/stable/_modules/torchvision/models/squeezenet.html
import torch
import torch.nn as nn
class Fire(nn.Module):
def __init__(self, inplanes, squeeze_planes,
expand1x1_planes, expand3x3_planes):
super(Fire, self).__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, x):
x = self.squeeze_activation(self.squeeze(x))
print(x.shape)
e_1 = self.expand1x1(x)
print(e_1.shape)
e_3 = self.expand3x3(x)
print(e_3.shape)
return torch.cat([
self.expand1x1_activation(e_1),
self.expand3x3_activation(e_3)
], 1)
很显然地,squeeze convolution layer把channel数量降下来了,所以参数少了很多.
以输入tensor为[n,c,h,w]=[1,96,224,224]举例,假设fire module的squeeze layer的卷积核数量为6,expand layer中1x1卷积核数量为5,3x3卷积核数量为4.
则fire module的参数数量为1x1x96x6 + 1x1x6x5 + 3x3x6x4=822.
普通的3x3卷积,得到depth=9的feature map的话需要3x3x96x9=7776个参数.
所以模型才可以做到很小.
网络结构

基本就是fire module的堆叠.中间穿插了一些maxpool对feature map下采样. 注意一下最后用了dropout以及全局平均池化而不是全连接来完成分类.
最左边的就是类似vgg的堆叠式的结构.中间和右边的参考了resnet的skip-connection.
class SqueezeNet(nn.Module):
def __init__(self, version='1_0', num_classes=1000):
super(SqueezeNet, self).__init__()
self.num_classes = num_classes
if version == '1_0':
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(96, 16, 64, 64),
Fire(128, 16, 64, 64),
Fire(128, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 32, 128, 128),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(512, 64, 256, 256),
)
elif version == '1_1':
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(64, 16, 64, 64),
Fire(128, 16, 64, 64),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(128, 32, 128, 128),
Fire(256, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
Fire(512, 64, 256, 256),
)
else:
# FIXME: Is this needed? SqueezeNet should only be called from the
# FIXME: squeezenet1_x() functions
# FIXME: This checking is not done for the other models
raise ValueError("Unsupported SqueezeNet version {version}:"
"1_0 or 1_1 expected".format(version=version))
# Final convolution is initialized differently from the rest
final_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
final_conv,
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1))
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m is final_conv:
init.normal_(m.weight, mean=0.0, std=0.01)
else:
init.kaiming_uniform_(m.weight)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return torch.flatten(x, 1)
https://pytorch.org/hub/pytorch_vision_squeezenet/
这里有一个用torch中的模型做推理的例子,
.....
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
print(torch.nn.functional.softmax(output[0], dim=0))
CNN结构设计的探索
主要从2个方面做实验探讨了不同结构对模型精度和模型大小的影响.

- fire module怎么设计,squeeze layer和expand layer的filter数量怎么设计
- fire module怎么串起来形成一个网络,是简单堆叠还是引入bypass
关于第一点fire module中各种filter占比的实验结果如下图:

这里的sr指的是squeeze layer的卷积核数量/expand layer比例.3x3filter比例指expand layer里3x3filter比例.
具体设计参考论文:

一点思考:
1x1的卷积核关联了某个位置的feature所有channel上的信息.3x3的卷积核关联了多个位置的feature的所有channel的信息.按道理说3x3的越多应该模型精度越好,但实验数据显示并非如此.可能有些是噪音,3x3卷积参考太多周围的feature反而导致精度下降. 这也是深度学习现在被比较多诟病的一点,太黑盒了.只知道能work,为啥work不好解释.不同的数据集可能不同的参数表现会不一样,很难讲哪个最优,调参比较依赖经验.
关于第二点在layer之间采用不同的连接方式,实验结果如下:

轻量级CNN模型之squeezenet的更多相关文章
- 轻量级CNN模型mobilenet v1
mobilenet v1 论文解读 论文地址:https://arxiv.org/abs/1704.04861 核心思想就是通过depthwise conv替代普通conv. 有关depthwise ...
- 深度学习方法(七):最新SqueezeNet 模型详解,CNN模型参数降低50倍,压缩461倍!
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 继续前面关于深度学习CNN经典模型的 ...
- CNN 模型压缩与加速算法综述
本文由云+社区发表 导语:卷积神经网络日益增长的深度和尺寸为深度学习在移动端的部署带来了巨大的挑战,CNN模型压缩与加速成为了学术界和工业界都重点关注的研究领域之一. 前言 自从AlexNet一举夺得 ...
- 基于Pre-Train的CNN模型的图像分类实验
基于Pre-Train的CNN模型的图像分类实验 MatConvNet工具包提供了好几个在imageNet数据库上训练好的CNN模型,可以利用这个训练好的模型提取图像的特征.本文就利用其中的 “im ...
- 卷积神经网络(CNN)模型结构
在前面我们讲述了DNN的模型与前向反向传播算法.而在DNN大类中,卷积神经网络(Convolutional Neural Networks,以下简称CNN)是最为成功的DNN特例之一.CNN广泛的应用 ...
- FaceRank-人脸打分基于 TensorFlow 的 CNN 模型
FaceRank-人脸打分基于 TensorFlow 的 CNN 模型 隐私 因为隐私问题,训练图片集并不提供,稍微可能会放一些卡通图片. 数据集 130张 128*128 张网络图片,图片名: 1- ...
- Keras入门(四)之利用CNN模型轻松破解网站验证码
项目简介 在之前的文章keras入门(三)搭建CNN模型破解网站验证码中,笔者介绍介绍了如何用Keras来搭建CNN模型来破解网站的验证码,其中验证码含有字母和数字. 让我们一起回顾一下那篇文 ...
- keras训练cnn模型时loss为nan
keras训练cnn模型时loss为nan 1.首先记下来如何解决这个问题的:由于我代码中 model.compile(loss='categorical_crossentropy', optimiz ...
- keras入门(三)搭建CNN模型破解网站验证码
项目介绍 在文章CNN大战验证码中,我们利用TensorFlow搭建了简单的CNN模型来破解某个网站的验证码.验证码如下: 在本文中,我们将会用Keras来搭建一个稍微复杂的CNN模型来破解以上的 ...
随机推荐
- FPGA 内部详细架构你明白了吗?
FPGA 芯片整体架构如下所示,大体按照时钟域划分的,即根据不同的工艺.器件速度和对应的时钟进行划分: FPGA 内部详细架构又细分为如下六大模块: 1.可编程输入输出单元(IOB)(Input Ou ...
- JSR303 后端校验包的使用
1.首先通过Maven导入JSR303架包. <!-- https://mvnrepository.com/artifact/org.hibernate.validator/hibernate- ...
- 数据库系统概论——SQL
[toc] 一.SQL查询语言概览 视图 从一个或几个基本表导出的表 数据库中只存放视图的定义而不存放视图对应的数据 视图是一个虚表 用户可以在视图上再定义视图 基本表 本身独立存在的表 SQL中一个 ...
- Dedecms手机站三种不同建设方法和优劣分析
dedecms简单易用功能强大,是国内使用最多的cms建站系统,百度站长平台专门推出了“织梦移动化指南”,由此可见dedecms的影响力.织梦也是站长使用和学习最早的cms建站系统,解放了我的双手,让 ...
- vertical-align之见
ertical-align 英文翻译为垂直对齐 ,常用来应用于table 表格中文字的垂直居中:脱离表格后不常用: 有朋友问起:故总结记之: 开局一张图,下来全靠编 这是一个简单的四线表格,小学时 ...
- docker 使用及基本命令
一.docker简单使用 a.列出镜像 docker images b.从docker hub拉取最新版本镜像 docker pull xxx 错误: Error response from daem ...
- 死磕 java线程系列之线程池深入解析——体系结构
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 简介 Java的线程池是块硬骨头,对线程池的源码做深入研究不仅能提高对Java整个并发编程的理解,也能提高自己 ...
- Ubuntu安装Chrome浏览器及解决启动no-sandbox问题
1.安装浏览器 # apt-get install gonme # apt-get update # apt-get install google-chrome-stable 2.启动Chrome浏览 ...
- Mint(Linux)系统设置优化及其常用软件安装笔记
LInux /home下中文目录如何修改成英文? 打开终端,在终端中输入命令: export LANG=en_US xdg-user-dirs-gtk-update 跳出对话框询问是否将目录转化为英文 ...
- Spring中@Import的各种用法以及ImportAware接口
@Import 注解 @Import注解提供了和XML中<import/>元素等价的功能,实现导入的一个或多个配置类.@Import即可以在类上使用,也可以作为元注解使用. @Target ...