Python 爬虫从入门到进阶之路(一)
通用爬虫和聚焦爬虫
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种.
通用爬虫
通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
通用搜索引擎(Search Engine)工作原理
通用网络爬虫 从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。
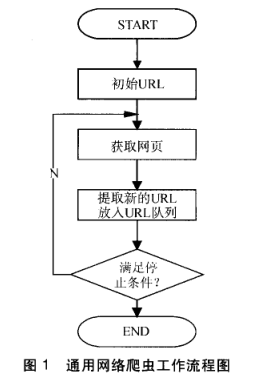
第一步:抓取网页
搜索引擎网络爬虫的基本工作流程如下:
首先选取一部分的种子URL,将这些URL放入待抓取URL队列;
取出待抓取URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,并且将这些URL放进已抓取URL队列。
分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环....

搜索引擎如何获取一个新网站的URL:
1. 新网站向搜索引擎主动提交网址:(如百度http://zhanzhang.baidu.com/linksubmit/url)
2. 在其他网站上设置新网站外链(尽可能处于搜索引擎爬虫爬取范围)
3. 搜索引擎和DNS解析服务商(如DNSPod等)合作,新网站域名将被迅速抓取。
但是搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容,如标注为nofollow的链接,或者是Robots协议。
Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
第二步:数据存储
搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。
搜索引擎蜘蛛在抓取页面时,也做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
第三步:预处理
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。
- 提取文字
- 中文分词
- 消除噪音(比如版权声明文字、导航条、广告等……)
- 索引处理
- 链接关系计算
- 特殊文件处理
- ....
除了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。
但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序。
第四步:提供检索服务,网站排名
搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户。
同时会根据页面的PageRank值(链接的访问量排名)来进行网站排名,这样Rank值高的网站在搜索结果中会排名较前,当然也可以直接使用 Money 购买搜索引擎网站排名,简单粗暴。


但是,这些通用性搜索引擎也存在着一定的局限性:
通用搜索引擎所返回的结果都是网页,而大多情况下,网页里90%的内容对用户来说都是无用的。
不同领域、不同背景的用户往往具有不同的检索目的和需求,搜索引擎无法提供针对具体某个用户的搜索结果。
万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎对这些文件无能为力,不能很好地发现和获取。
通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询,无法准确理解用户的具体需求。
针对这些情况,聚焦爬虫技术得以广泛使用。
聚焦爬虫
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
而我们今后要学习的,就是聚焦爬虫。
Python 爬虫从入门到进阶之路(一)的更多相关文章
- Python 爬虫从入门到进阶之路(八)
在之前的文章中我们介绍了一下 requests 模块,今天我们再来看一下 Python 爬虫中的正则表达的使用和 re 模块. 实际上爬虫一共就四个主要步骤: 明确目标 (要知道你准备在哪个范围或者网 ...
- Python 爬虫从入门到进阶之路(二)
上一篇文章我们对爬虫有了一个初步认识,本篇文章我们开始学习 Python 爬虫实例. 在 Python 中有很多库可以用来抓取网页,其中内置了 urllib 模块,该模块就能实现我们基本的网页爬取. ...
- Python 爬虫从入门到进阶之路(六)
在之前的文章中我们介绍了一下 opener 应用中的 ProxyHandler 处理器(代理设置),本篇文章我们再来看一下 opener 中的 Cookie 的使用. Cookie 是指某些网站服务器 ...
- Python 爬虫从入门到进阶之路(九)
之前的文章我们介绍了一下 Python 中的正则表达式和与爬虫正则相关的 re 模块,本章我们就利用正则表达式和 re 模块来做一个案例,爬取<糗事百科>的糗事并存储到本地. 我们要爬取的 ...
- Python 爬虫从入门到进阶之路(十二)
之前的文章我们介绍了 re 模块和 lxml 模块来做爬虫,本章我们再来看一个 bs4 模块来做爬虫. 和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也 ...
- Python 爬虫从入门到进阶之路(十五)
之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取<糗事百科>的糗事进行丰富和完善. 在 Xpath 模块的爬取糗百的案例中我 ...
- Python 爬虫从入门到进阶之路(十六)
之前的文章我们介绍了几种可以爬取网站信息的模块,并根据这些模块爬取了<糗事百科>的糗百内容,本章我们来看一下用于专门爬取网站信息的框架 Scrapy. Scrapy是用纯Python实现一 ...
- Python 爬虫从入门到进阶之路(十七)
在之前的文章中我们介绍了 scrapy 框架并给予 scrapy 框架写了一个爬虫来爬取<糗事百科>的糗事,本章我们继续说一下 scrapy 框架并对之前的糗百爬虫做一下优化和丰富. 在上 ...
- Python 爬虫从入门到进阶之路(五)
在之前的文章中我们带入了 opener 方法,接下来我们看一下 opener 应用中的 ProxyHandler 处理器(代理设置). 使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的. 很 ...
- Python 爬虫从入门到进阶之路(七)
在之前的文章中我们一直用到的库是 urllib.request,该库已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Hum ...
随机推荐
- 备战“金九银十”10道String高频面试题解析
前言 String 是我们实际开发中使用频率非常高的类,Java 可以通过 String 类来创建和操作字符串,使用频率越高的类,我们就越容易忽视它,因为见的多所以熟悉,因为熟悉所以认为它很简单,其实 ...
- C语言每日一练——第7题
一.题目要求 已知数据文件in.dat中存有200个四位数,把这些数存到数组a中,编写函数jsVal(),其功能是:把千位数字和十位数字重新组成一个新的含有两位数字的数ab(新数的十位数字是原四位数的 ...
- round分析
Python 所谓的奇进偶弃,因为浮点数的表示在计算机中并不准确,用的时候可能要注意一下. 测试如下 print() 由运行得出结论: 当小数点左边为偶数:小数点右边X<6,舍 当小数点左边为偶 ...
- Android(常用)主流UI开源库整理
这几天刚做完一个项目..有点空余时间,就想着吧这一两年做的项目中的UI界面用到的一些库整理一下.后来想了一下,既然要整理,就把网上常用的 AndroidUI界面的主流开源库 一起整理一下,方便查看. ...
- jq触发oninput事件
之前一直在用jq的change()方法来处理输入框的值变化事件,以及触发输入框的变化事件. 后来发现change()方法有个弊端,change事件的发生条件是:输入框的值value发生变化,并且输入框 ...
- ES6 promise 使用示例
new Promise(function (resolve, reject) { $.ajax({ type : 'post', data : formData, dataType : 'json', ...
- 第二次作业-titanic数据集练习
一.读入titanic.xlsx文件,按照教材示例步骤,完成数据清洗. titanic数据集包含11个特征,分别是: Survived:0代表死亡,1代表存活Pclass:乘客所持票类,有三种值(1, ...
- Openstack简述
1.Openstack项目发展概况: Nova 计算服务 Swift 对象存储服务 Glance 镜像服务 Neturon 网络服务 Keystone 身份认证服务 Celimeter 计 ...
- Python面向对象-多重继承之MixIN
以Animal类为例,假设要实现以下4种动物: Dog(狗).Bat(蝙蝠).Parrot(鹦鹉)和Ostrich(鸵鸟) 如果按照哺乳类和鸟类来区分的话,可以这样设计: Animal: |--Mam ...
- vue-practice
vue-完整代码 这是一个完整的vue案例,但是接口似乎都失效了,单是代码本身还是很有参考价值的呦!~ 里面包含了:vue,vue-router,....,还是直接看json文件吧 { "n ...