AI学习---分类算法[K-近邻 + 朴素贝叶斯 + 决策树 + 随机森林 ]
分类算法:对目标值进行分类的算法
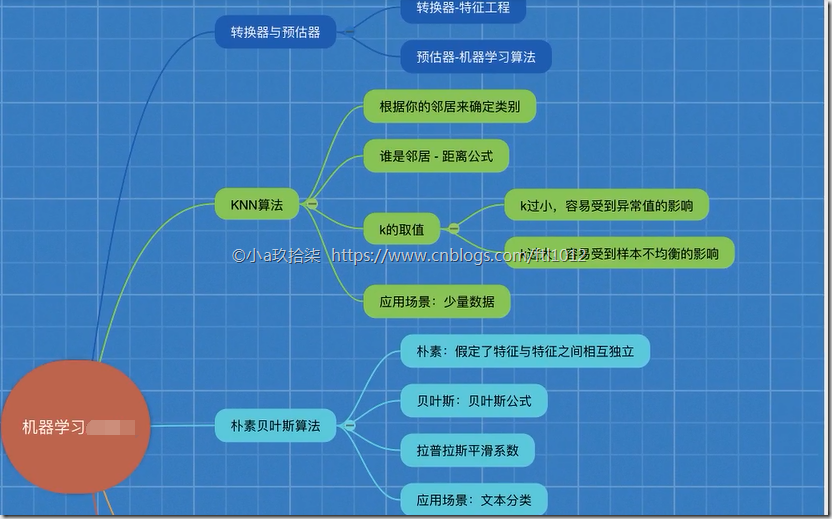
1、sklearn转换器(特征工程)和预估器(机器学习)
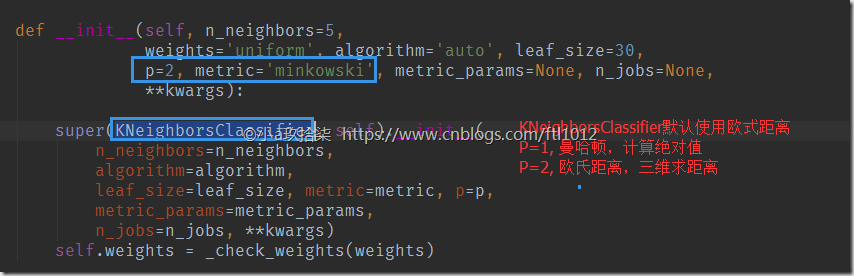
2、KNN算法(根据邻居确定类别 + 欧氏距离 + k的确定),时间复杂度高,适合小数据
3、模型选择与调优
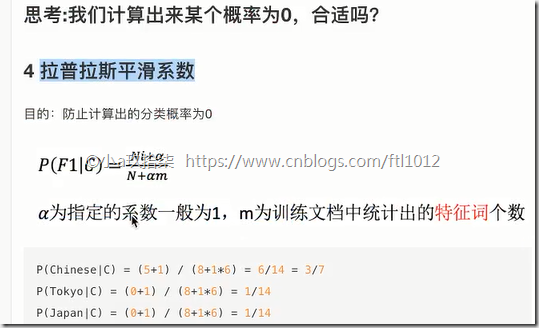
4、朴素贝叶斯算法(假定特征互独立 + 贝叶斯公式(概率计算) + 拉普拉斯平滑系数),假定独立,对缺失数据不敏感,用于文本分类
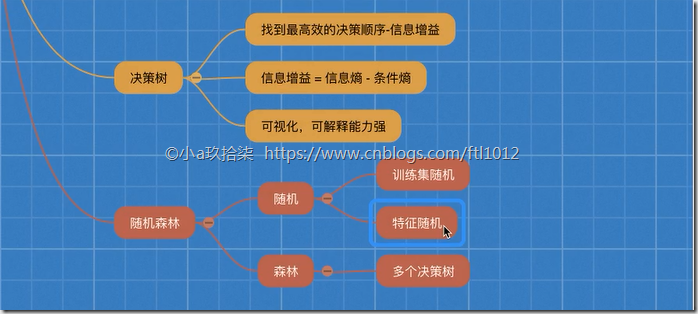
5、决策树(找到最高效的决策顺序--信息增益(关键特征=信息熵-条件熵) + 可以可视化)
6、随机森林(bootstarp(又放回的抽取) + 特征随机(抽取小特征) + 多个决策树)
sklearn转换器(transfer)与估计器(estimeter)简介
1、转换器 - 特征工程的父类
转换器 - 特征工程的父类
1、API的实现过程:
1 实例化 (实例化的是一个转换器类(Transformer))
2 调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
2、sklearn的标准化:
计算公式:(x - mean) / std
x: 数据
mean: 该列的平均值
std: 标准差
我们调用fit_transform()实际上发生了2个步骤:
fit() 计算 每一列的平均值、标准差
transform() (x - mean) / std进行最终的转换
# 转换器的实例讲解
import sklearn
# 特征预处理
from sklearn.preprocessing import StandardScaler def stand_demo():
data = [[1, 2, 3], [4, 5, 6]]
# 1、实例化一个类
std = StandardScaler()
# 2、调用fit_transform()
new_data = std.fit_transform(data) ''' fit = std.fit(data): # 已经完成了列的平均值和标准差的计算
StandardScaler(copy=True, with_mean=True, with_std=True) std = std.transform(data): # 根据公式(x - mean) / std进行最终的转换
[[-1. -1. -1.]
[ 1. 1. 1.]] new_data = std.fit_transform(data):
[[-1. -1. -1.]
[ 1. 1. 1.]]
'''
print(new_data) if __name__ == '__main__':
stand_demo()
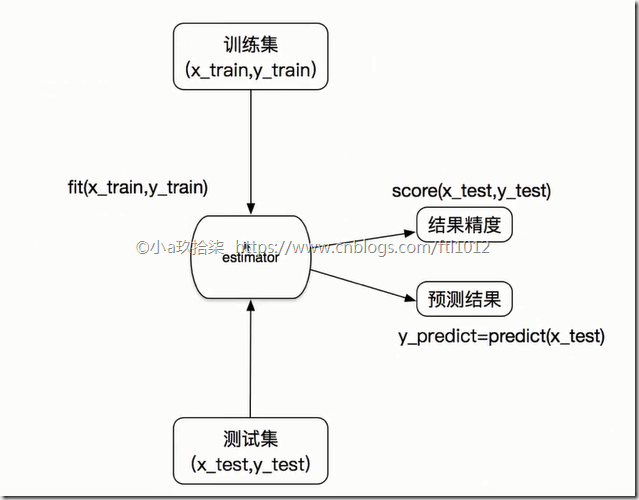
2、估计器--sklearn机器学习算法的实现
基于估计器的算法API

估计器的工作流程:
估计器(estimator)
1 实例化一个estimator
2 estimator.fit(x_train, y_train) --> 用于计算x_train: 训练集的特征值, y_train: 训练集的目标值
—— 调用完毕,模型生成
3 模型评估(有2种方法实现):
1)直接比对真实值和预测值
y_predict = estimator.predict(x_test) # x_test: 测试集的特征值, y_predict: 测试集的预测值y_test == y_predict # 对比测试集的预测值(y_predict)与测试集的目标值(y_test)是否一致
2)计算准确率
accuracy = estimator.score(x_test, y_test) # 传递测试集特征值和测试集目标值进行准确率计算
KNN算法(K-近邻算法)
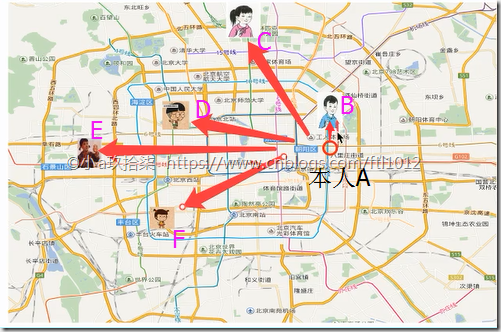
KNN的核心算法: 通过计算A到邻居(B、C、D、E、F)的距离可以判断A属于哪个类别(区域)。K就是相似特征
距离计算公式:
0、欧式距离
1、曼哈顿距离 (绝对值距离)
2、明可夫斯基距离(基于0和1实现)

K-近邻算法对目标数据的处理:
无量纲化的处理,即【标准化】(归一化会受到异常数据影响)
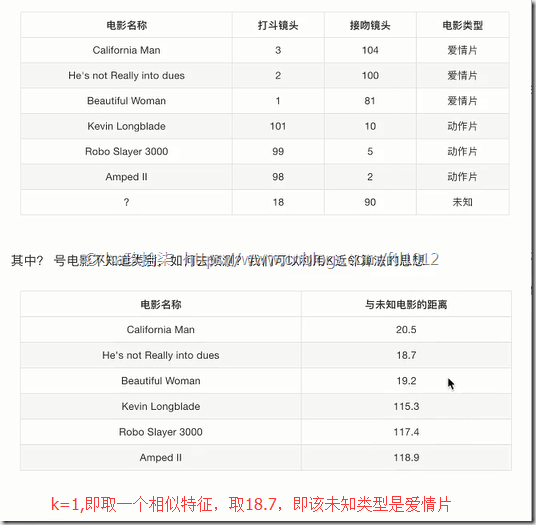
如果取的最近的电影数量不一样?会是什么结果?
k 值取得过小(即1个样本点),容易受到异常点的影响
k 值取得过大(即取出多样本),样本不均衡的影响
K-近邻算法API

KNN算法案例1:鸢尾花种类预测

案例分析:
1. 获取数据(sklearn自带的数据即可)
2. 数据处理(可省略,数据已经处理的很好了,目的是取出不完整的数据)
3. 特征工程
1. 数据集的划分(训练数据 + 测试数据)
2. 特征抽取(可省略,4个特征)
3. 特征预处理(标准化) --》 训练数据和测试数据都需要
4. 降维(可省略,降维的目的是减少特征,这里就4个特征)
4. KNN预估计流程
5. 模型评估
基于KNN实现鸢尾花的分类完整Demo:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier def knn_demo():
'''
基于KNN实现鸢尾花的分类
:return:
''' # 1、获取数据
iris = load_iris()
print('iris', iris.data.shape)
# 2、数据划分
# 结果跟随机数种子random_state有关
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=6)
# 3、特征工程: 标准化
stand_transfer = StandardScaler()
'''
原则: 训练集的数据做的操作,测试集也是需要做同样的操作
实现:
训练集:
stand_transfer对训练集进行了fit()和transfer(),即fit用于计算平均值和标准差,tranfer用于公式计算
测试集:
stand_transfer对训练集进行了transfer(),即用训练集求出来的平均值和标准差进行最后的公式计算(标准化)
如果对测试集用了fit_tranform(),即对测试集测试的仅仅是自己的数据内容,与训练内容无关
'''
x_train = stand_transfer.fit_transform(x_train) # 要对训练标准化
print('x_train', x_train.shape)
x_test = stand_transfer.transform(x_test) # 用训练集的平均值和标准差对测试集进行标准化
print('x_test', x_test.shape) # 4、KNN算法评估器
knn_estimater = KNeighborsClassifier(n_neighbors=3) # 邻居数量,默认是5
knn_estimater.fit(x_train, y_train) # 训练完成,产生模型;x_train: 训练集的特征值, y_train: 训练集的目标值 # 5、模型评估
# 方法1;直接对比真实值和预测值
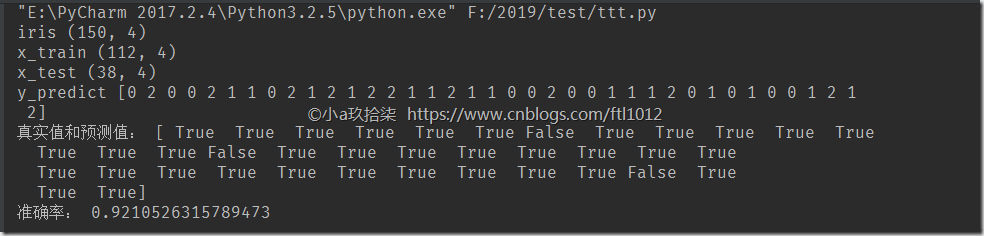
y_predict = knn_estimater.predict(x_test)
print('y_predict', y_predict)
print('真实值和预测值:', y_predict == y_test) # 方法2:计算准确率
score = knn_estimater.score(x_test, y_test) # 传递测试集特征值和测试集目标值进行准确率计算
print('准确率:',score)
return None if __name__ == '__main__':
knn_demo()
KNN算法总结

附: 我们可以利用【模型与调优】进行K的确定
模型选择与调优

模型选择与调优的方案:
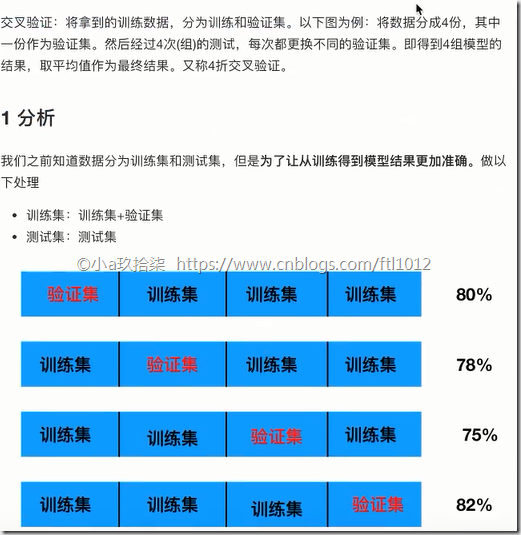
1、交叉验证(Cross Validate)
2、超参数搜索 –> 网格搜索(Grid Search)
方案一:交叉验证(cross validate, 即有限数据多次验证,被评估的模型更加可信)
方案二:超参数搜索--网格搜索(Grid Search)

模型选择与调优API
说明:GridSearchCV实际上也是一个评估器,用法与上面相同

基于KNN实现鸢尾花的分类,添加网格搜索和交叉验证,用于确定最优的K值完整Demo:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier def knn_gridSearch_demo():
'''
基于KNN实现鸢尾花的分类,添加网格搜索和交叉验证,用于确定最优的K值
:return:
''' # 1、获取数据
iris = load_iris()
print('iris', iris.data.shape)
# 2、数据划分
# 结果跟随机数种子random_state有关
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=3)
# 3、特征工程: 标准化
stand_transfer = StandardScaler()
'''
原则: 训练集的数据做的操作,测试集也是需要做同样的操作
实现:
训练集:
stand_transfer对训练集进行了fit()和transfer(),即fit用于计算平均值和标准差,tranfer用于公式计算
测试集:
stand_transfer对训练集进行了transfer(),即用训练集求出来的平均值和标准差进行最后的公式计算(标准化)
如果对测试集用了fit_tranform(),即对测试集测试的仅仅是自己的数据内容,与训练内容无关
'''
x_train = stand_transfer.fit_transform(x_train) # 要对训练标准化
print('x_train', x_train.shape)
x_test = stand_transfer.transform(x_test) # 用训练集的平均值和标准差对测试集进行标准化
print('x_test', x_test.shape) # 4、KNN算法评估器
knn_estimater = KNeighborsClassifier() # 5、加入网格搜索与交叉验证
param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]} # 这里只能是字典
'''
estimator : estimator object.
param_grid : dict or list of dictionaries
'''
knn_estimater = GridSearchCV(estimator=knn_estimater, param_grid=param_dict, cv=10)
knn_estimater.fit(x_train, y_train) # 训练完成,产生模型;x_train: 训练集的特征值, y_train: 训练集的目标值 # 6、模型评估
# 方法1;直接对比真实值和预测值
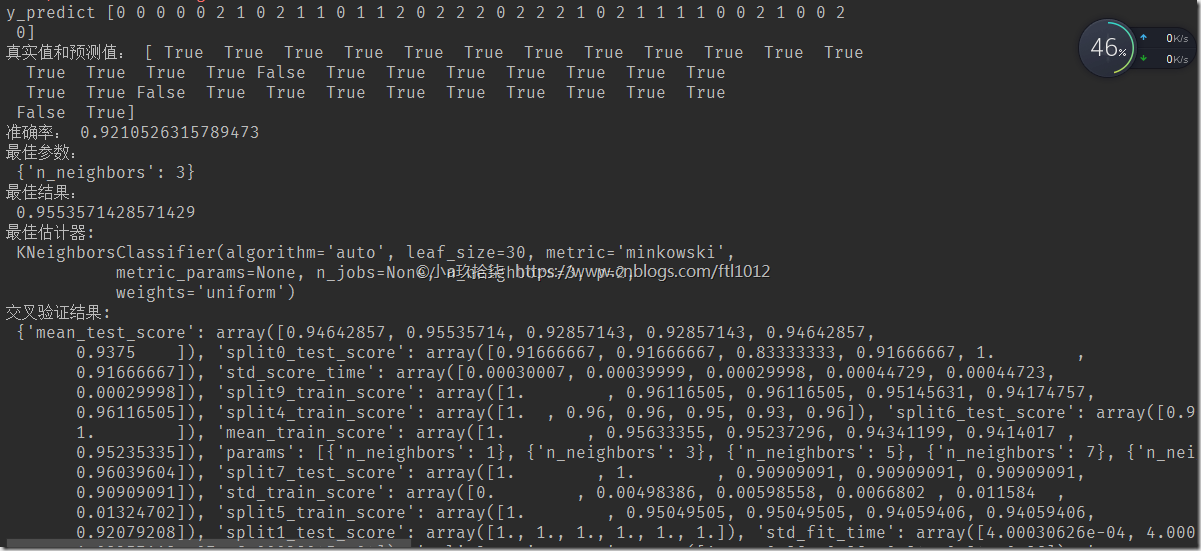
y_predict = knn_estimater.predict(x_test)
print('y_predict', y_predict)
print('真实值和预测值:', y_predict == y_test) # 方法2:计算准确率
score = knn_estimater.score(x_test, y_test) # 传递测试集特征值和测试集目标值进行准确率计算
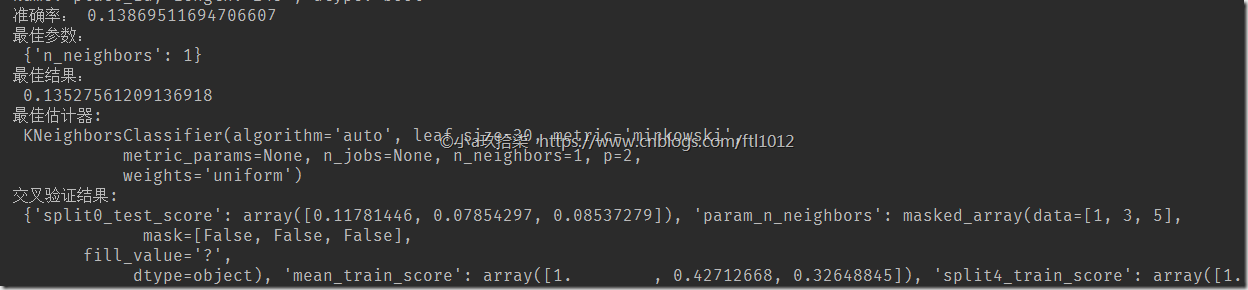
print('准确率:', score) # 最佳参数:best_params
print("最佳参数:\n", knn_estimater.best_params_)
# 最佳结果:best_score_
print("最佳结果:\n", knn_estimater.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\n", knn_estimater.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\n", knn_estimater.cv_results_) return None if __name__ == '__main__':
knn_gridSearch_demo()
拓展:
Facebook的预测签到位置案例:


Facebook的预测签Demo
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier def facebook_demo():
# 1、获取数据
data = pd.read_csv("F:\instacart\\train.csv") # 2、基本的数据处理
# 1)缩小数据范围
data = data.query("x < 3 & x > 2 & y < 3 & y > 2")
# 2)处理时间特征
time_value = pd.to_datetime(data["time"], unit="s")
date = pd.DatetimeIndex(time_value)
data["day"] = date.day
data["weekday"] = date.weekday
data["hour"] = date.hour # 3)过滤签到次数少的地点
place_count = data.groupby("place_id").count()["row_id"] # 仅仅显示place_id的签到次数和row_id信息
# data_final --> pandas.core.frame.DataFrame类型
data_final = data[data["place_id"].isin(place_count[place_count > 3].index.values)] # 过滤出来次数大于3的数据 # 4)筛选特征值和目标值
x = data_final[["x", "y", "accuracy", "day", "weekday", "hour"]]
y = data_final["place_id"] # 5)数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y) # 传入特征值和目标值 # 3、特征工程:标准化
stand_transfer = StandardScaler()
x_train = stand_transfer.fit_transform(x_train) # 要对训练标准化
print('x_train', x_train.shape)
x_test = stand_transfer.transform(x_test) # 用训练集的平均值和标准差对测试集进行标准化
print('x_test', x_test.shape) # 4、KNN算法评估器
knn_estimater = KNeighborsClassifier() # 5、加入网格搜索与交叉验证
param_dict = {"n_neighbors": [1, 3, 5]} # 这里只能是字典
'''
estimator : estimator object.
param_grid : dict or list of dictionaries
'''
knn_estimater = GridSearchCV(estimator=knn_estimater, param_grid=param_dict, cv=5)
knn_estimater.fit(x_train, y_train) # 训练完成,产生模型;x_train: 训练集的特征值, y_train: 训练集的目标值 # 6、模型评估
# 方法1;直接对比真实值和预测值
y_predict = knn_estimater.predict(x_test)
print('y_predict', y_predict)
print('真实值和预测值:', y_predict == y_test) # 方法2:计算准确率
score = knn_estimater.score(x_test, y_test) # 传递测试集特征值和测试集目标值进行准确率计算
print('准确率:', score) # 最佳参数:best_params
print("最佳参数:\n", knn_estimater.best_params_)
# 最佳结果:best_score_
print("最佳结果:\n", knn_estimater.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\n", knn_estimater.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\n", knn_estimater.cv_results_) return None if __name__ == '__main__':
facebook_demo()
朴素贝叶斯算法
概率(Probability):
联合概率、条件概率与相互独立
联合概率:包含多个条件,且所有条件同时成立的概率
条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
相互独立: P(A, B) = P(A)P(B) <=> 事件A与事件B相互独立
朴素:
假设:特征与特征之间是相互独立朴素贝叶斯算法: 朴素 + 贝叶斯
应用场景:
文本分类
单词作为特征
概率

朴素贝叶斯

拉普拉斯平滑系数

朴素贝叶斯API(naive表示朴素的意思)


20类新闻分类DEMO

案例分析:20类新闻分类(sklean会从官网下载数据,约14M)
1)获取数据
2)划分数据集
3)特征工程 -->文本特征抽取(TF-IDF)
4)朴素贝叶斯预估器流程
5)模型评估
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
def nb_news():
"""
用朴素贝叶斯算法对新闻进行分类
:return:
"""
# 1)获取数据
news = fetch_20newsgroups(subset="all")
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 3)特征工程:文本特征抽取-tfidf
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)朴素贝叶斯算法预估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 5)模型评估
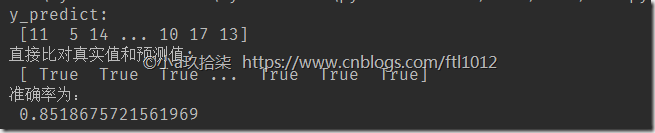
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
if __name__ == '__main__':
nb_news()
决策树

简单讲,决策树就是我们Py语言中的if-elif-else语句,通过对特征的先后顺序进行选择,从而达到高效的决策
决策树的原理
信息论基础
1)信息(香农定义) :消除随机不定性的东西
小明 年龄 “我今年18岁” - 信息
小华 ”小明明年19岁” - 不是信息
2)信息的衡量 –》 信息量 -》 信息熵
信息的单位:比特(bit)
g(D,A) = H(D) - 条件熵H(D|A)
4 决策树的划分依据之一------信息增益




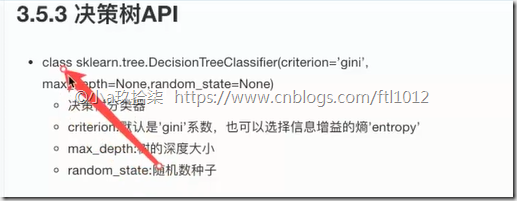
决策树的API

案例一: 鸢尾花决策树demo –> 结果表明KNN算法更好
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz def decision_iris():
"""
用决策树对鸢尾花进行分类
:return:
"""
# 1)获取数据集
iris = load_iris() # 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22) # 3)决策树预估器
estimator = DecisionTreeClassifier(criterion="entropy")
estimator.fit(x_train, y_train) # 4)模型评估
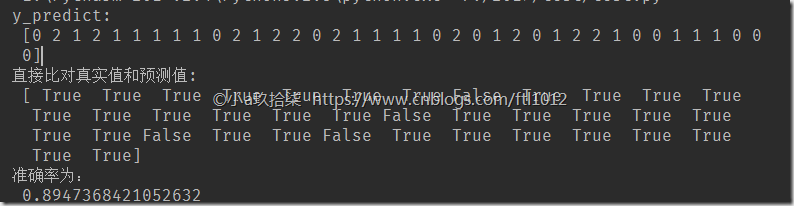
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict) # 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score) # 可视化决策树
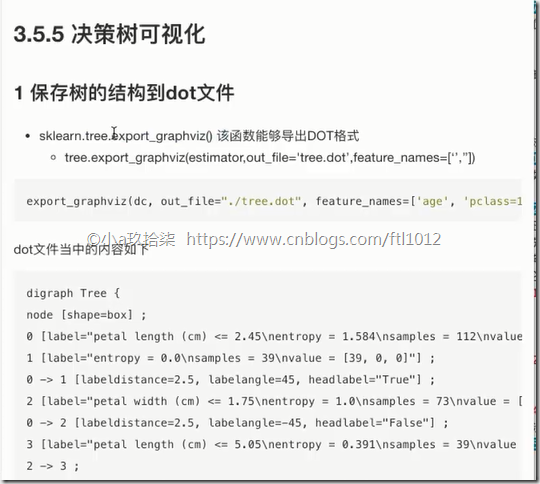
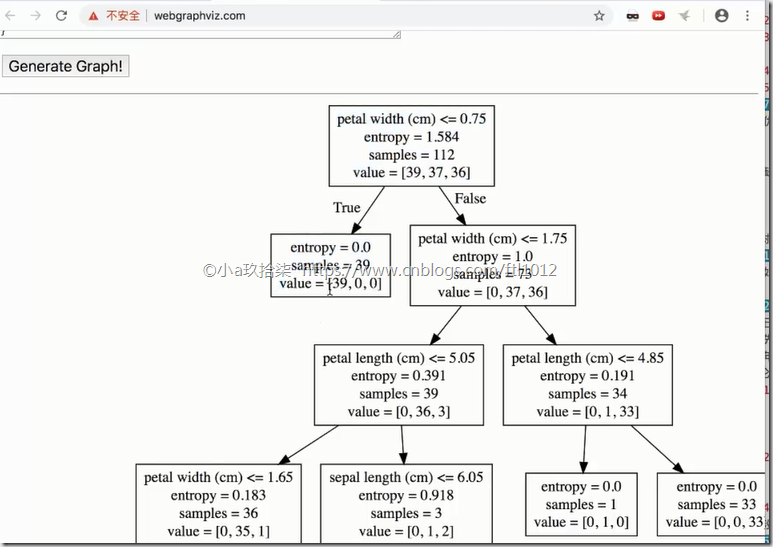
export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names) return None if __name__ == '__main__':
decision_iris()
可视化:
案例二:泰坦尼克号乘客生存预测
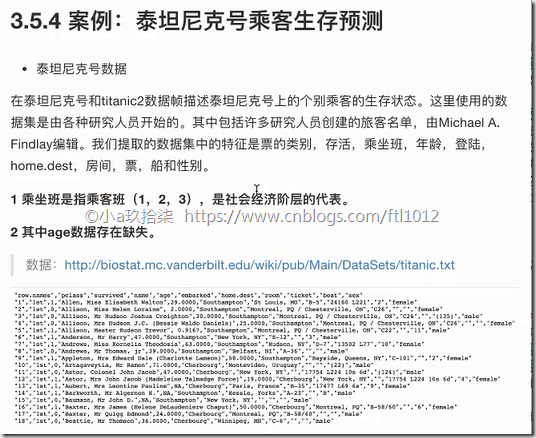
流程分析:获取特征值&目标值
1)获取数据
2)数据处理
缺失值处理
特征值 -> 字典类型
3)准备好特征值 目标值
4)划分数据集
5)特征工程:字典特征抽取
6)决策树预估器流程
7)模型评估
import pandas as pd def titanic_demo():
# 1、获取数据
path = "http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt"
# titanic = pd.read_csv("F:\instacart\\titanic_demo.txt") # 小数据,仅部分
titanic = pd.read_csv(path) # 大数据
# 筛选特征值和目标值
x = titanic[["pclass", "age", "sex"]]
y = titanic["survived"] # 2、数据处理
# 1)缺失值处理
x["age"].fillna(x["age"].mean(), inplace=True) # 填补平均值,inplace表示填补数据到原数据
# 2) 转换成字典
x = x.to_dict(orient="records") # x代表dataform, orient=”record”代表json格式
from sklearn.model_selection import train_test_split
# 3、数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 4、字典特征抽取
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier, export_graphviz
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 3)决策树预估器
estimator = DecisionTreeClassifier(criterion="entropy", max_depth=8)
estimator.fit(x_train, y_train) # 4)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict) # 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score) # 可视化决策树
export_graphviz(estimator, out_file="titanic_tree.dot", feature_names=transfer.get_feature_names()) if __name__ == '__main__':
titanic_demo()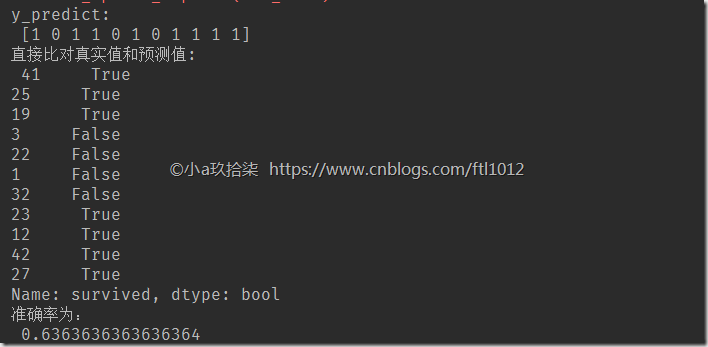
随机森林

随机森林原理过程
训练集: N个样本,包含特征值+目标值
特征值: M个特征
随机 = 两个随机(训练随机 + 特征随机)
1、训练集随机 --》 从N个样本中随机有放回的抽样N个
bootstrap(随机有放回抽样)
假设有原始数据集合:[1, 2, 3, 4, 5],第一次抽取到了2,然后放回原数据集,抽到下一个数字还是2,放回后下个是3,以此类推,产生新的树的训练集[2, 2, 3, 1, 5]2、特征随机 - 从M个特征中随机抽取m个特征
M >> m(M远远大于m),相当于我们之前的【降维】,特征数量减少了,
随机森林的API

随机森林-泰坦尼克号demo
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV def random_tree_titanic_demo():
# 1、获取数据
path = "http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt"
titanic = pd.read_csv("F:\instacart\\titanic_demo.txt") # 小数据,仅部分
# titanic = pd.read_csv(path) # 大数据
# 筛选特征值和目标值
x = titanic[["pclass", "age", "sex"]]
y = titanic["survived"] # 2、数据处理
# 1)缺失值处理
x["age"].fillna(x["age"].mean(), inplace=True)
# 2) 转换成字典
x = x.to_dict(orient="records")
from sklearn.model_selection import train_test_split
# 3、数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 4、字典特征抽取 transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 3)决策树预估器
estimator = RandomForestClassifier()
# 加入网格搜索与交叉验证
# 参数准备
param_dict = {"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
estimator.fit(x_train, y_train) # 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict) # 方法2:计算准确率
score = estimator.score(x_test, y_test)
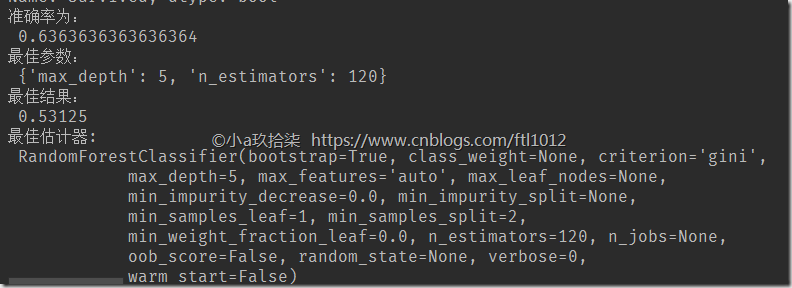
print("准确率为:\n", score) # 最佳参数:best_params_
print("最佳参数:\n", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\n", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\n", estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\n", estimator.cv_results_) if __name__ == '__main__':
random_tree_titanic_demo()
其他
资料链接:https://pan.baidu.com/s/1apbuwSIfSx7OqcFS9KqVBg
提取码:lvaq
AI学习---分类算法[K-近邻 + 朴素贝叶斯 + 决策树 + 随机森林 ]的更多相关文章
- 检测用户命令序列异常——使用LSTM分类算法【使用朴素贝叶斯,类似垃圾邮件分类的做法也可以,将命令序列看成是垃圾邮件】
通过 搜集 Linux 服务器 的 bash 操作 日志, 通过 训练 识别 出 特定 用户 的 操作 习惯, 然后 进一步 识别 出 异常 操作 行为. 使用 SEA 数据 集 涵盖 70 多个 U ...
- 第4章 最基础的分类算法-k近邻算法
思想极度简单 应用数学知识少 效果好(缺点?) 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 distances = [] for x_train in X_train ...
- 机器学习算法实践:朴素贝叶斯 (Naive Bayes)(转载)
前言 上一篇<机器学习算法实践:决策树 (Decision Tree)>总结了决策树的实现,本文中我将一步步实现一个朴素贝叶斯分类器,并采用SMS垃圾短信语料库中的数据进行模型训练,对垃圾 ...
- [机器学习] 分类 --- Naive Bayes(朴素贝叶斯)
Naive Bayes-朴素贝叶斯 Bayes' theorem(贝叶斯法则) 在概率论和统计学中,Bayes' theorem(贝叶斯法则)根据事件的先验知识描述事件的概率.贝叶斯法则表达式如下所示 ...
- 【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 用例子来理解k-近邻算法 电影可以按 ...
- 分类算法----k近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
随机推荐
- 翻译:man getopt(1)中文手册
NAME getopt - 解析命令行选项(加强版) SYNOPSIS getopt optstring parameters getopt [options] [--] optstring para ...
- JavaScript 系列博客(三)
JavaScript 系列博客(三) 前言 本篇介绍 JavaScript 中的函数知识. 函数的三种声明方法 function 命令 可以类比为 python 中的 def 关键词. functio ...
- 数据挖掘(二)——Knn算法的java实现
1.K-近邻算法(Knn) 其原理为在一个样本空间中,有一些已知分类的样本,当出现一个未知分类的样本,则根据距离这个未知样本最近的k个样本来决定. 举例:爱情电影和动作电影,它们中都存在吻戏和动作,出 ...
- [转]NET Core静态文件的缓存方式
本文转自:https://www.cnblogs.com/Leo_wl/p/6059349.html 阅读目录 NET Core静态文件的缓存方式 一.前言 二.StaticFileMiddlewar ...
- [转]centos每天自动备份mysql数据库
本文转自:https://www.cnblogs.com/chongchong88/p/5566645.html #!/bin/bash PATH=/bin:/sbin:/usr/bin:/usr/s ...
- SQL去除数据库表中tab、空格、回车符等特殊字符的解决方法
按照ASCII码, SELECT char(64) 例如64 对应 @,则 ), 'kk'); 则结果为 abckkqq.com 依此类推, 去掉其他特殊符号,参考ASCII码对照表, 去掉tab符号 ...
- Linux学习笔记之基本指令
1.ll 注:详细展示当前文件夹下的所有文件及目录 ,与 ls -al 有异曲同工的作用 2.free -m/-h 注:-m:显示当前的内存信息,-m表示以MB为单位显示:-h:以人类能读懂的形式显 ...
- Java 数组声明的几种方式
Java数组定义声明的几种方法: 1. 类型名称[] 变量名=new 类型名称[length]; 2.类型名称[] 变量名={?,?,?}; 3.类型名称[] 变量名=new 类型名称[]{?,?,? ...
- JS 操作svg画图
背景: 一共有3个文件:svg文件,html文件,js文件. 有一个svg图,使用embed标签,引入到了html文件中 svg文件: <svg width="640" he ...
- @Value取不到值的原因(引用application.properties中自定义的值)
在spring mvc架构中,如果希望在程序中直接使用properties中定义的配置值,通常使用一下方式来获取: @Value("${tag}") private String ...