Hadoop2.0环境安装
0. Hadoop源码包下载
http://mirror.bit.edu.cn/apache/hadoop/common
1. 集群环境
操作系统
CentOS7
集群规划
Master 192.168.1.210
Slave1 192.168.1.211
Slave2 192.168.1.203
2. 关闭系统防火墙及内核防火墙
#Execute in Master、Slave1、Slave2
#关闭一次防火墙
systemctl stop firewalld
#永久关闭防火墙
systemctl disable firewalld
#临时关闭内核防火墙
setenforce 0
#永久关闭内核防火墙
vim /etc/selinux/config
SELINUX=disabled

3. 修改主机名
#Execute in Master
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master
#Execute in Slave1
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave1
#Execute in Slave2
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave2
4. 修改IP地址
#Execute in Master、Slave1、Slave2
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=00:50:56:89:25:3E
TYPE=Ethernet
UUID=de38a19e-4771-4124-9792-9f4aabf27ec4
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
#下列信息需要根据实际情况设置
IPADDR=192.168.1.101
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
DNS1=119.29.29.29
5. 修改主机文件
#Execute in Master、Slave1、Slave2
vim /etc/hosts
172.16.11.97 master
172.16.11.98 slave1
172.16.11.99 slave2
6. SSH互信配置
#Execute in Master、Slave1、Slave2
#生成密钥对(公钥和私钥)
ssh-keygen -t rsa
#三次回车生成密钥
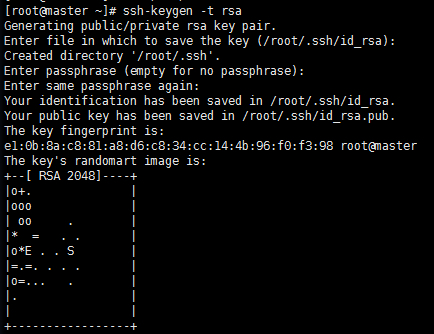
#Execute in Maste
cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys
chmod 600 /root/.ssh/authorized_keys
#追加密钥到Master
ssh slave1 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
ssh slave2 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
#复制密钥到从节点
scp /root/.ssh/authorized_keys root@slave1:/root/.ssh/authorized_keys
scp /root/.ssh/authorized_keys root@slave2:/root/.ssh/authorized_keys
7. 安装JDK
http://www.oracle.com/technetwork/java/javase/downloads/index.html
#Master
cd /usr/local/src
wget 具体已上面的链接地址为准
tar zxvf jdk1.8.0_152.tar.gz
8. 配置JDK环境变量
#Executer in Maste
#配置JDK环境变量
vim ~/.bashrc
JAVA_HOME=/usr/local/src/jdk1.8.0_152
JAVA_BIN=/usr/local/src/jdk1.8.0_152/bin
JRE_HOME=/usr/local/src/jdk1.8.0_152/jre
CLASSPATH=/usr/local/jdk1.8.0_152/jre/lib:/usr/local/jdk1.8.0_152/lib:/usr/local/jdk1.8.0_152/jre/lib/charsets.jar
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
#分发到其他节点
scp /root/.bashrc root@slave1:/root/.bashrc
scp /root/.bashrc root@slave2:/root/.bashrc
9. JDK拷贝到Slave主机
#Executer in Master
scp -r /usr/local/src/jdk1.8.0_152 root@slave1:/usr/local/src/jdk1.8.0_152
scp -r /usr/local/src/jdk1.8.0_152 root@slave2:/usr/local/src/jdk1.8.0_152
10. 下载安装包
#Master
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.2/hadoop-2.8.2.tar.gz
tar zxvf hadoop-2.8.2.tar.gz
11. 修改Hadoop配置文件
#Master
cd hadoop-2.8.2/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
vim yarn-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
vim slaves
slave1
slave2
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.16.11.97:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop-2.8.2/tmp</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop-2.8.2/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop-2.8.2/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
#创建临时目录和文件目录
mkdir /usr/local/src/hadoop-2.8.2/tmp
mkdir -p /usr/local/src/hadoop-2.8.2/dfs/name
mkdir -p /usr/local/src/hadoop-2.8.2/dfs/data
12. 配置环境变量
#Master、Slave1、Slave2
vim ~/.bashrc
HADOOP_HOME=/usr/local/src/hadoop-2.8.2
export PATH=$PATH:$HADOOP_HOME/bin::$HADOOP_HOME/sbin
#刷新环境变量
source ~/.bashrc
13. 拷贝安装包
#Master
scp -r /usr/local/src/hadoop-2.8.2 root@slave1:/usr/local/src/hadoop-2.8.2
scp -r /usr/local/src/hadoop-2.8.2 root@slave2:/usr/local/src/hadoop-2.8.2
14. 启动集群
#Master
#初始化Namenode
hadoop namenode -format
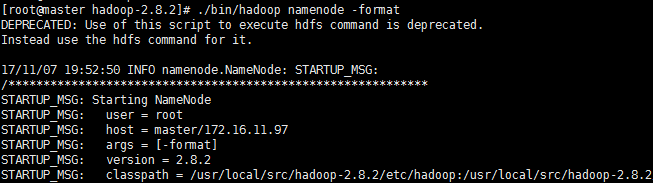

#启动集群
./sbin/start-all.sh

15. 集群状态
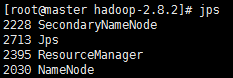
jps
#Master
#Slave1

#Slave2
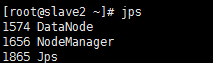
16. 监控网页
http://master:8088
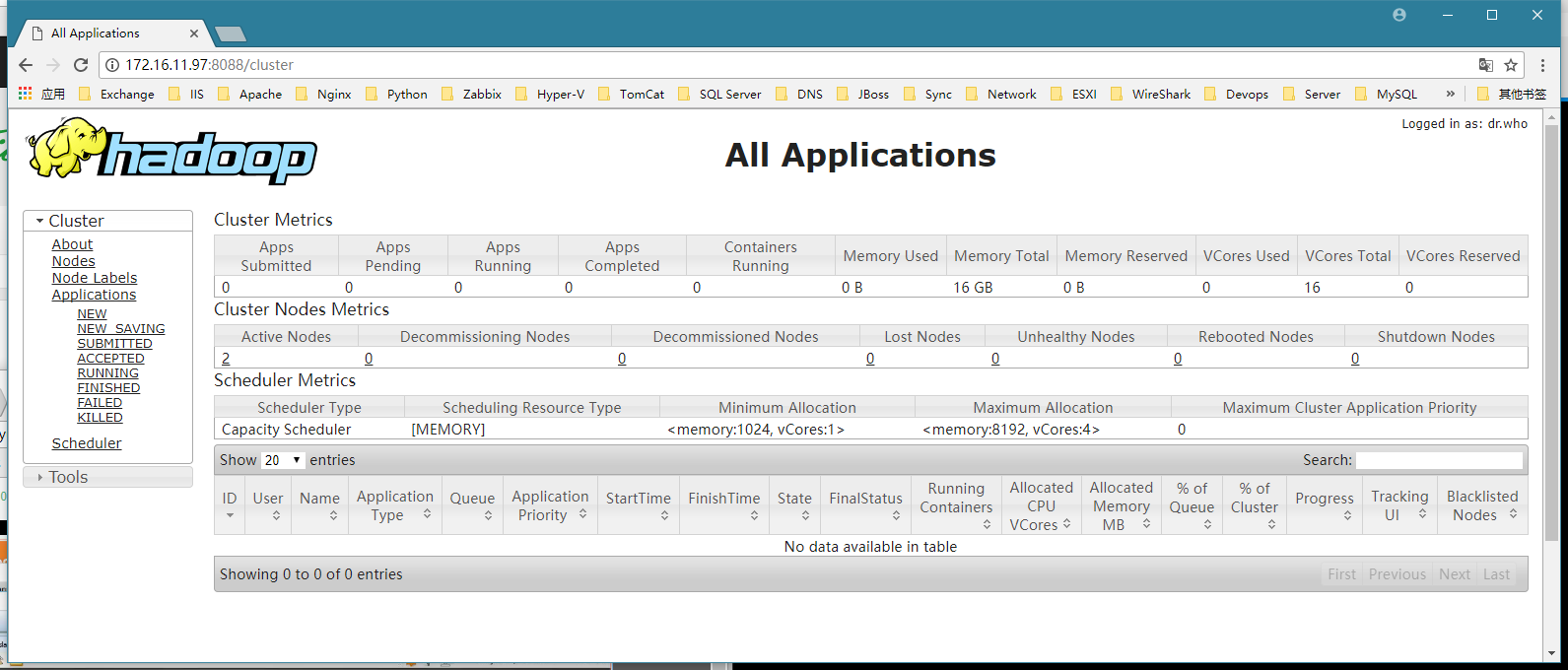
17. 操作命令
#和Hadoop1.0操作命令是一样的

18. 关闭集群
./sbin/hadoop stop-all.sh
Hadoop2.0环境安装的更多相关文章
- Hadoop2.0环境搭建
需准备的前提条件: 1. 安装JDK(自行安装) 2. 关闭防火墙(centos): systemctl stop firewalld.service systemctl disable firewa ...
- 吉特仓库管理系统-.NET4.0环境安装不上问题解决
在给客户实施软件的过程中要,要安装.NET 4.0 环境,而且是在XP的系统上. 目前的客户中仍然有大量使用XP的机器,而且极为不稳定,在安装吉特仓库管理系统客户端的时候出现了如下问题: 产品: Mi ...
- 集群架构03·MySQL初识,mysql8.0环境安装,mysql多实例
官方网址 https://dev.mysql.com/downloads/mysql/社区版本分析 MySQL5.5:默认存储引擎改为InnoDB,提高性能和可扩展性,增加半同步复制 MySQL5.6 ...
- VC6.0环境安装STLport-5.2.1
今天安装STLport,网上搜资料安装好久,都不行,因为STLport 的版本不对,我这是STLport-5.2.1新版本. (注意:下面的步骤都在一个cmd里操作,很简单的原因:环境变量啊) 1.首 ...
- 大数据笔记(三)——Hadoop2.0的安装与配置
一.Hadoop安装部署的预备条件 准备:1.安装Linux和JDK. 安装JDK 解压:tar -zxvf jdk-8u144-linux-x64.tar.gz -C ~/training/ 设置环 ...
- hadoop2.0单机安装
hadoop发行的版本:apache hadoop;HDP;CDH -----这里只使用apache hadoop---可以在网站hadoop.apache.org网站上找到 hadoop安装方式:自 ...
- vue2.0环境安装
参考网站http://www.open-open.com/lib/view/open1476240930270.html (以上博客vue init webpack-simple 工程名字<工程 ...
- fedora gtk+ 2.0环境安装配置
1.安装gtk yum install gtk2 gtk2-devel gtk2-devel-docs 2.测试是否安装成功 pkg-config --cflags --libs gtk+-2.0 执 ...
- 第一节 —— vue2.0 环境安装,工程化开发
vue的开发有两种,一种是直接的在script标签里引入vue.js文件即可,这样子引入的话个人感觉做小型的多页面会比较舒坦,一旦做大型一点的项目,还是离不开webpack. 所以另一种方法也就是基于 ...
随机推荐
- UE4 PostProcessVolume 蓝图操作后期框
如图找到场景里面的后期框,首先我们要获得它的设置,Settings 大概就是属性的意思.通过Settings设置其它的属性.Set members in PostProcessSetting 就是接口 ...
- 《DSP using MATLAB》Problem 7.27
代码: %% ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ %% Output In ...
- 枪弹辩驳(弹丸论破)即将登陆PC
Spike Chunsoft在PSP上的经典推理游戏: 枪弹辩驳1(Danganronpa: Trigger Happy Havoc)即将登陆PC, PC党有福了. 不过我在PSVita上已经玩完了两 ...
- LeetCode - Min Remaining Chess Pieces
假设有一个棋盘(二维坐标系), 棋盘上摆放了一些石子(每个石子的坐标都为整数). 你可以remove一个石子, 当且仅当这个石子的同行或者同列还有其它石子. 输入是一个list of points. ...
- java单例设计模式总结及举例
* 设计模式:前人总结出来的经验,被后人直接拿来使用. * 单例设计模式:一个类只允许有一个对象,将这个对象作为一个全局的访问点,提供出去供大家使用. * 分析: * 1.用户只能有一个对象 * 2. ...
- [双系统linux] ----双系统切换导致系统时间错误
安装了linux双系统以后,发现每次双系统切换以后系统时间总会错误. 原因:Linux和win7(win10)双系统时间错误问题 时间相差8小时 MAC/linux 将系统硬件时间看待为UTC, 即U ...
- c# 中 利用 CookieContainer 对 Cookie 进行序列化和反序列化校验
private void Form1_Load(object sender, EventArgs e) { var cookieStr = @".CNBlogsCookie=1BE76122 ...
- sql语句实例练习
1.最晚入职员工查询 select * from employees where hire_date = (select max(hire_date) from employees) 2.倒数第三 ...
- 前端基础:web语义化
web语义化 一.什么是web语义化? web语义化包含两方面,一是html标签语义化,简单来说就是要用合适的标签来表述适当的内容,标题用<h1>~~<h6>标签,段落用< ...
- Spring Boot - AOP(面向切面)-切入点表达式
切入点指示符用来指示切入点表达式目的,在 Spring AOP 中目前只有执行方法这一个连接点,Spring AOP 支持的 AspectJ 切入点指示符,切入点表达式可以使用 &&. ...