verilog乘法器的设计
在verilog编程中,常数与寄存器变量的乘法综合出来的电路不同于寄存器变量乘以寄存器变量的综合电路。知乎里的解释非常好https://www.zhihu.com/question/45554104,总结乘法器模块的实现https://blog.csdn.net/yf210yf/article/details/70156855
乘法的实现是移位求和的过程
乘法器模块的实现主要有以下三种方法
1.串行实现方法
占用资源最多,需要的时钟频率高些,但是数据吞吐量却不大
两个N位二进制数x、y的乘积用简单的方法计算就是利用移位操作来实现。
其框图如下:
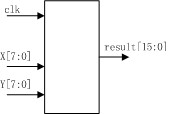
其状态图如下:
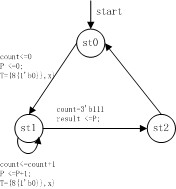
代码:
module multi_CX(clk, x, y, result);
input clk;
input [:] x, y;
output [:] result;
reg [:] result;
parameter s0 = , s1 = , s2 = ;
reg [:] count = ;
reg [:] state = ;
reg [:] P, T;
reg [:] y_reg;
always @(posedge clk) begin
case (state)
s0: begin
count <= ;
P <= ;
y_reg <= y;
T <= {{{'b0}}, x};
state <= s1;
end
s1: begin
if(count == 'b111)
state <= s2;
else begin
if(y_reg[] == 'b1)
P <= P + T;
else
P <= P;
y_reg <= y_reg >> ;
T <= T << ;
count <= count + ;
state <= s1;
end
end
s2: begin
result <= P;
state <= s0;
end
default: ;
endcase
end
endmodule
慢速信号处理中常用到的。
2.并行流水线实现方法
将操作数的N位并行提交给乘法器,这种方法并不是最优的实现架构,在FPGA中进位的速度远大于加法的速度,因此将相临的寄存器相加,相当于一个二叉树的结构,实际上对于n位的乘法处理,需要logn级流水来实现。
一个8位乘法器,其原理图如下图所示:
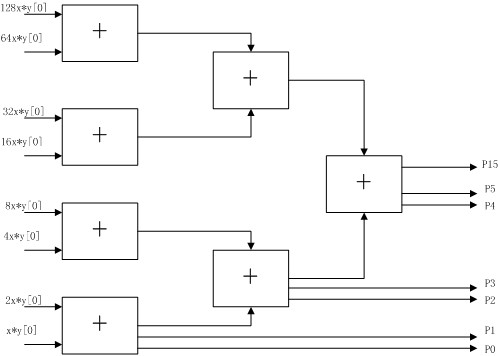
其实现的代码如下:
module multi_4bits_pipelining(mul_a, mul_b, clk, rst_n, mul_out);
input [:] mul_a, mul_b;
input clk;
input rst_n;
output [:] mul_out; reg [:] mul_out;
reg [:] stored0;
reg [:] stored1;
reg [:] stored2;
reg [:] stored3;
reg [:] stored4;
reg [:] stored5;
reg [:] stored6;
reg [:] stored7; reg [:] mul_out01;
reg [:] mul_out23; reg [:] add01;
reg [:] add23;
reg [:] add45;
reg [:] add67; always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
mul_out <= ;
stored0 <= ;
stored1 <= ;
stored2 <= ;
stored3 <= ;
stored4 <= ;
stored5 <= ;
stored6 <= ;
stored7 <= ; add01 <= ;
add23 <= ;
add45 <= ;
add67 <= ;
end
else begin
stored0 <= mul_b[]? {'b0, mul_a} : 16'b0;
stored1 <= mul_b[]? {'b0, mul_a, 1'b0} : 'b0;
stored2 <= mul_b[]? {'b0, mul_a, 2'b0} : 'b0;
stored3 <= mul_b[]? {'b0, mul_a, 3'b0} : 'b0;
stored4 <= mul_b[]? {'b0, mul_a, 4'b0} : 'b0;
stored5 <= mul_b[]? {'b0, mul_a, 5'b0} : 'b0;
stored6 <= mul_b[]? {'b0, mul_a, 6'b0} : 'b0;
stored7 <= mul_b[]? {'b0, mul_a, 7'b0} : 'b0;
add01 <= stored1 + stored0;
add23 <= stored3 + stored2;
add45 <= stored5 + stored4;
add67 <= stored7 + stored6; mul_out01 <= add01 + add23;
mul_out23 <= add45 + add67; mul_out <= mul_out01 + mul_out23; end
end
endmodule
流水线乘法器比串行乘法器的速度快很多很多,在非高速的信号处理中有广泛的应用。至于高速信号的乘法一般需要利用FPGA芯片中内嵌的硬核DSP单元来实现。
3.booth算法
看了原文献,有基2和基4两种实现
最常用的主要还是基2实现也就是用被除数的每两位做编码,Booth算法对乘数从低位开始判断,根据两个数据位的情况决定进行加法、减法还是仅仅移位操作。判断的两个数据位为当前位及其右边的位(初始时需要增加一个辅助位0),移位操作是向右移动。
代码
module booth( start_sig, a, b, done_sig , product)
wire [:] start_sig;
wire [:] a;
wire [:] b;
wire [:] product;
/********************************/
reg[:] i;
reg[:] ra;
reg[:] rs;
reg[:] rp;
reg[:] x;
reg isdone;
always @(posedge clk or negedge rst_n)
if(!rst_n)
begin
i<='d0;
ra<='d0;
rs<='d0;
rp<='d0;
x<='d0;
isdone<='b0;
end
else if(start_sig)
case(i)
:
begin
ra<=a;
rs<=(~a+);
rp<={'d0,b,1'b0};
i<=i+;
end
:
if(x==)
begin
x<='d0;
i<=i+;
end
else if(rp[:]=='b01)
begin
rp<={rp[:]+ra,rp[:]};
i<=i+;
end
else if(rp[:]=='b10)
begin
rp<={rp[:]+rs,rp[:]};
i<=i+;
end
else
i<=i+;
:
begin
rp<={rp[],rp[:]};
x<=x+;//返回去检测对应寄存器值的方法
i<=i-;
end
:
begin
isdone<='b1;
i<=i+;
end
:
begin
isdone<='b0;
i<='d0;
end
endcase
assign product=rp[:];
assign done_sig=isdone;
endmodule
verilog乘法器的设计的更多相关文章
- Verilog学习笔记设计和验证篇(三)...............同步有限状态机的指导原则
因为大多数的FPGA内部的触发器数目相当多,又加上独热码状态机(one hot code machine)的译码逻辑最为简单,所以在FPGA实现状态机时,往往采用独热码状态机(即每个状态只有一个寄存器 ...
- Verilog乘法器
乘法器,不能用乘号直接表示,略坑呀 坑归坑,做还是要做的 思路:首先乘法分为有符号乘与无符号乘,所以建立两个module分别运算有符号与无符号.然后在总module中用case语句判断输出应赋的值. ...
- verilog分频模块设计
verilog设计: 分频器的设计: 分频器就是将一个时钟源的频率降低的过程(可以通过观察分频之后周期中包含几个原时钟周期来看是几分频),分频分为基数分频也分为偶数分频, 偶数分频的代码如下:(其中就 ...
- 8421BCD转余3码Verilog HDL的设计(1)
近期阅读Verilog HDL高级数字设计(第二版)中,遇到了串行比特流BCD码转余3码转换器的设计,比较独特的是: (1)该转换器的输入为1位串行比特流,输出也为1位串行比特流. BCD码与余三码的 ...
- Verilog学习笔记设计和验证篇(五)...............层次化事件队列
详细的了解层次化事件队列有助于理解Verilog的阻塞赋值和非阻塞赋值功能.所谓层次化事件队列指的是用于调度仿真时间的不同Verilog事件队列.在IEEE的5.3节中定义了层次化事件队列在逻辑上分为 ...
- Verilog学习笔记设计和验证篇(一)...............总线和流水线
总线 总线是运算部件之间数据流通的公共通道.在硬线逻辑构成的运算电路中只要电路的规模允许可以比较自由的确定总线的位宽,从而大大的提高数据流通的速度.各个运算部件和数据寄存器组可以通过带有控制端的三态门 ...
- Verilog学习笔记设计和验证篇(二)...............同步有限状态机
上图表示的就是数字电路设计中常用的时钟同步状态机的结构.其中共有四个部分产生下一状态的组合逻辑F.状态寄存器组.输出组合逻辑G.流水线输出寄存器组.如果状态寄存器组由n个寄存器组成,就可以记忆2^n个 ...
- 转载Verilog乘法器
1. 串行乘法器 两个N位二进制数x.y的乘积用简单的方法计算就是利用移位操作来实现. module multi_CX(clk, x, y, result); input clk; input [7: ...
- Verilog分频器的设计
大三都要结束了,才发现自己太多东西没深入学习. 对于偶分频:(计数到分频数的一半就翻转) 注: 图中只用了一个计数器,当然也可以用多个: 图中只计数到需要分频的一半,当然也可计数到更多: 图中从第一个 ...
随机推荐
- 神经网络 参数计算--直接解析CKPT文件读取
1.tensorflow的模型文件ckpt参数获取 import tensoflow as tf from tensorflow.python import pywrap_tensorflow mod ...
- html属性,上传图片选择时只显示图片文件
这个实现比较简单,就是用到accept属性: 注意这里我们对这个file元素进行了隐藏,因为它默认呈现是下面这个样子的,并不好看. <div style="display:none;& ...
- 写一个读取Excel表格的接口
# -*- coding: gbk -*-import xlrd class Canshu: def __init__(self,filepath): """ 创建文件对 ...
- Linux不进入网卡配置文件更改静态ip
1.找到网卡配置文件名ls /etc/sysconfig/network-scripts/ 2.备份并查看原始配置文件(若原先有配置IP的,则按照第五点方式修改) 3.修改随机自启和IP地址echo ...
- Codeforces 1294E - Obtain a Permutation
题目大意: 给定一个n*m的矩阵 可以更改任意一个位置的值 也可以选择一整列全部往上移动一位,最上方的数移动到最下方 问最少操作多少次可以把这个矩阵移动成 1 2 3 ... m m+1 m+2 m+ ...
- Window RabbitMq安装
rabbitMQ是一个在AMQP协议标准基础上完整的,可服用的企业消息系统.它遵循Mozilla Public License开源协议,采用 Erlang 实现的工业级的消息队列(MQ)服务器,Rab ...
- amazon中文文档
在线调试器 https://mws.amazonservices.com.cn/scratchpad/index.html mws 中心 https://developer.amazonservice ...
- socker通信-struct模块-粘包问题
Socket概念 Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口.在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对 ...
- python学习——tuple
tuple 上次谈到了列表,而这次所谈的元组其实和列表有许多相似的地方,故元组又叫"戴上了枷锁的列表".这是因为元组不能改动内部的元素,所以就不能使用上次谈到的append.ext ...
- Tokyocabinet/Tokyotyrant文档大合集
1. 前言 这里不是我个人原创,是我对网络上整理到的资料的再加工,以更成体系,更方便研究阅读.主要是对其中跟主题无关的文字删除,部分人称稍做修改;本人无版权,您可以将本页面视为对参考页面的镜像.第二部 ...