hadoop本地调试方法
Mapreduce 是Hadoop上一个进行分布式数据运算和统计的框架,但是每次运行程序的时候都需要将程序打包并上传的集群环境中运行,这就会让程序的调试变得十分不方便。所以在这里写下这篇博客和大家交流学习如何在本地调试Mapreduce程序。
本地是windows系统,文件路径也是本地
首先需要将编译后的windos 放入解压后的hadoop解压包的bin目录下,还有hadoop,dll文件不同版本的windows对应的winutils.exe是不同的。具体编译方法,网上可以找到相关教程
放入解压后的hadoop解压包的bin目录下,还有hadoop,dll文件不同版本的windows对应的winutils.exe是不同的。具体编译方法,网上可以找到相关教程
这里就不详说了。当然网上也有好心人编译好的,来后就能用。
然后将hadoop的HADOOP_HOME配置到环境变量中去。在PATH中配置PATH=“%HADOOP—HOME\bin%”;
可能有些同学运行程序后仍会包报错NullPointException。需要将bin目录下的hadoop.dll考到C盘的system32下一份。
再次运行,非常好。
在本地运行需要配置两个参数
- conf.set("mapred.job.tracker", "local");
- conf.set("fs.default.name", "local");
其实这两个参数也可以不用配置,因为系统默认的就是本地
package worldcount; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WorldCountDrive { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration();
/* conf.set("mapred.job.tracker", "local");
conf.set("fs.default.name", "local"); */ Job job = Job.getInstance(conf); job.setJarByClass(WorldCountDrive.class); job.setMapperClass(WorldcountMap.class);
job.setReducerClass(WorldCountReduce.class); job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path("C:/README.txt"));
FileOutputFormat.setOutputPath(job, new Path("C:/output")); boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
这样我们写的mapreduce程序就可以在本地打断点进行调试了
log4j的配置
hadoop.root.logger=DEBUG, console
log4j.rootLogger = DEBUG, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
本地系统运行,文件系统用HDFS
conf.set("mapred.job.tracker", "local");
conf.set("fs.defaultFS", "hdfs://Hadoop:9000");
………………
FileInputFormat.setInputPaths(job, new Path("/Users/admin/Telephone_Summary")); //hdfs的文件路径
FileOutputFormat.setOutputPath(job, new Path("/Users/admin/mapreduceTestOutput"));//hdfs的文件路径</span>
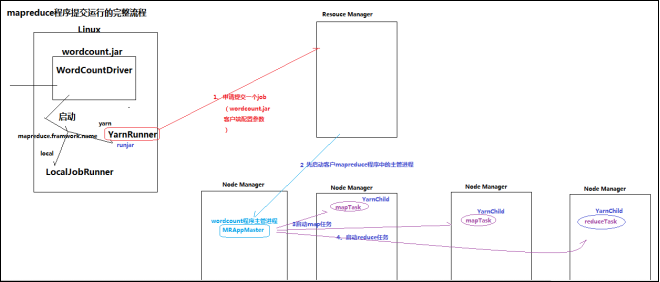
集群运行模式
(1)将mapreduce程序提交给yarn集群resourcemanager,分发到很多的节点上并发执行
(2)处理的数据和输出结果应该位于hdfs文件系统
(3)提交集群的实现步骤:
A、将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
$ hadoop jar wordcount.jar cn.itcast.bigdata.mrsimple.WordCountDriver inputpath outputpath
B、直接在linux的eclipse中运行main方法
(项目中要带参数:mapreduce.framework.name=yarn以及yarn的两个基本配置)
C、如果要在windows的eclipse中提交job给集群,则要修改YarnRunner类
mapreduce程序在集群中运行时的大体流程:
hadoop本地调试方法的更多相关文章
- Hive 本地调试方法
关键词:hive, debug 本地调试(local debug) Hive 可分为 exec (hive-exec,主要对应源码里的ql目录) 和 metastore 两部分,其中exec对外有两种 ...
- lucene-solr本地调试方法
1.下载并编译lucene-solr的源代码,并导入 eclipse sts等 2.修改SolrDispatchFilter的solr.solr.home属性,我们这里将其直接修改为一个本地绝对路径, ...
- Hadoop本地调试
windows上先调试该程序,然后再转到linux下. 程序运行的过程中, 报 Failed to locate the winutils binary in the hadoop binary pa ...
- fiddler本地调试
参考:https://blog.csdn.net/letasian/article/details/75021656 有关fiddler基础用法的介绍详见我的上一篇博客:http://www.cnbl ...
- hadoop本地运行模式调试
一:简介 最近学习hadoop本地运行模式,在运行期间遇到一些问题,记录下来备用:以运行hadoop下wordcount为例子. hadoop程序是在集群运行还是在本地运行取决于下面两个参数的设置,第 ...
- 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试
相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(二) -- 在集群上运行与监控 用python + hadoop streami ...
- windows本地调试安装hadoop(idea) : ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path
1,本地安装hadoop https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/ 下载hadoop对应版本 (我本意是想下载hadoop ...
- windows下本地调试hadoop代码,远程调试hadoop节点。
1.在github上搜索下载winutils.exe相关的一套文件,下载对应hadoop的版本. 2.将所有文件复制到hadoop的bin目录下 3.将hadoop.dll复制到windows\sys ...
- Oracle在本地调试成功读取数据,但是把代码放到服务器读不出数据的解决方法。
用MVC EF框架开发项目,数据库用的是Oracle,本地调试的时候一切正常,但是把代码编译之后放到服务器就会读不出数据. 原因:本地调试环境与服务器环境不一致. 办法:在服务器上装ODT.NET组件 ...
随机推荐
- angularJS中directive父子组件的数据交互
angularJS中directive父子组件的数据交互 1. 使用共享 scope 的时候,可以直接从父 scope 中共享属性.使用隔离 scope 的时候,无法从父 scope 中共享属性.在 ...
- BZOJ3528: [Zjoi2014]星系调查
唉,看到这题直接想起自己的Day1,还是挺难受的,挺傻一题考试的时候怎么就没弄出来呢…… 这两天CP让我给他写个题解,弄了不是很久就把这个题给弄出来了,真不知道考试的时候在干嘛. 明天就出发去北京了, ...
- webservice SOAP WSDL UDDI简介
WebServices简介 先给出一个概念 SOA ,即Service Oriented Architecture ,中文一般理解为面向服务的架构, 既然说是一种架构的话,所以一般认为 SOA 是包含 ...
- JQuery直接调用asp.net后台WebMethod方法(转)
转自 http://blog.csdn.net/handsometone1982/article/details/7684894 利用JQuery的$.ajax()可以很方便的调用asp.net的后 ...
- Leetcode22. Generate Parentheses(生成有效的括号组合)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/74937307冷血之心的博客) 题目如下:
- HTTP返回结果状态码小结
HTTP 状态码负责表示客户端 HTTP 请求的返回结果.标记服务器端的处理是否正常.通知出现的错误等工作. 一.状态码的类别 状态码的职责是当客户端向服务器端发送请求时,描述返回的请求结果.借助状态 ...
- web应用程序安全攻防---sql注入和xss跨站脚本攻击
kali视频学习请看 http://www.cnblogs.com/lidong20179210/p/8909569.html 博文主要内容包括两种常见的web攻击 sql注入 XSS跨站脚本攻击 代 ...
- python的一些开源库
SQLAlchemy——数据持久层框架 简介 SQLAlchemy 主要由两部分组成,一个 SQL 工具包和一个关系对象映射(ORM),它能让开发者完全发挥出 SQL 的灵活性与强大的能量.他实现了一 ...
- [Luogu3769][CH弱省胡策R2]TATT
luogu 题意 其实就是四维偏序. sol 第一维排序,然后就只需要写个\(3D-tree\)了. 据说\(kD-tree\)的单次查询复杂度是\(O(n^{1-\frac{1}{k}})\).所以 ...
- 【eclipse】 怎么解决java.lang.NoClassDefFoundError错误
前言 在日常Java开 发中,我们经常碰到java.lang.NoClassDefFoundError这样的错误,需要花费很多时间去找错误的原因,具体是哪个类不见了?类 明明还在,为什么找不到?而且我 ...