1.5 HDFS分布式文件系统-hadoop-最全最完整的保姆级的java大数据学习资料
1.5 HDFS分布式文件系统
1.5.1 HDFS 简介
HDFS(全称:Hadoop Distribute File System,Hadoop 分布式文件系统)是 Hadoop 核心组成,是分布式存储服务。
分布式文件系统横跨多台计算机,在大数据时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力。
HDFS是分布式文件系统中的一种。
1.5.2 HDFS的重要概念
HDFS 通过统一的命名空间目录树来定位文件;另外,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色(分布式本质是拆分,各司其职)
典型的 Master/Slave 架构
HDFS 的架构是典型的 Master/Slave 结构。
HDFS集群往往是一个NameNode(HA架构会有两个NameNode,联邦机制)+ 多个DataNode组成。
NameNode是集群的主节点,DataNode是集群的从节点。
分块存储(block机制)
HDFS中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定。
Hadoop2.x版本中默认的block大小是128M。
命名空间(NameSpace)
HDFS支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动 或重命名文件。
Namenode 负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被 Namenode 记录下来。
HDFS提供给客户单一个抽象目录树,访问形式:hdfs://namenode的hostname:port/test/input
hdfs://linux121:9000/test/input
NameNode元数据管理
我们把目录结构及文件分块位置信息叫做元数据。
NameNode的元数据记录每一个文件所对应的block信息(block的id,以及所在的DataNode节点的信息)
DataNode数据存储
文件的各个 block 的具体存储管理由 DataNode 节点承担。一个block会有多个DataNode来存储,DataNode会定时向NameNode来汇报自己持有的block信息。
副本机制
为了容错,文件的所有 block 都会有副本。每个文件的 block 大小和副本系数都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后改变。 副本数量默认是3个。一次写入,多次读出
HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的随机修改。(支持追加写入, 不只支持随机更新)
正因为如此,HDFS适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用(修改不方便,延迟大,网络开销大,成本太高)
1.5.3 HDFS架构
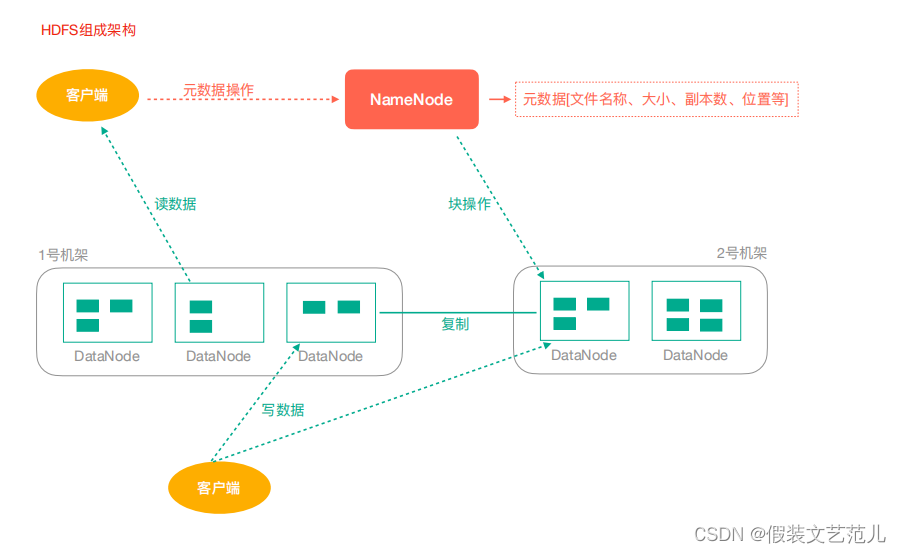
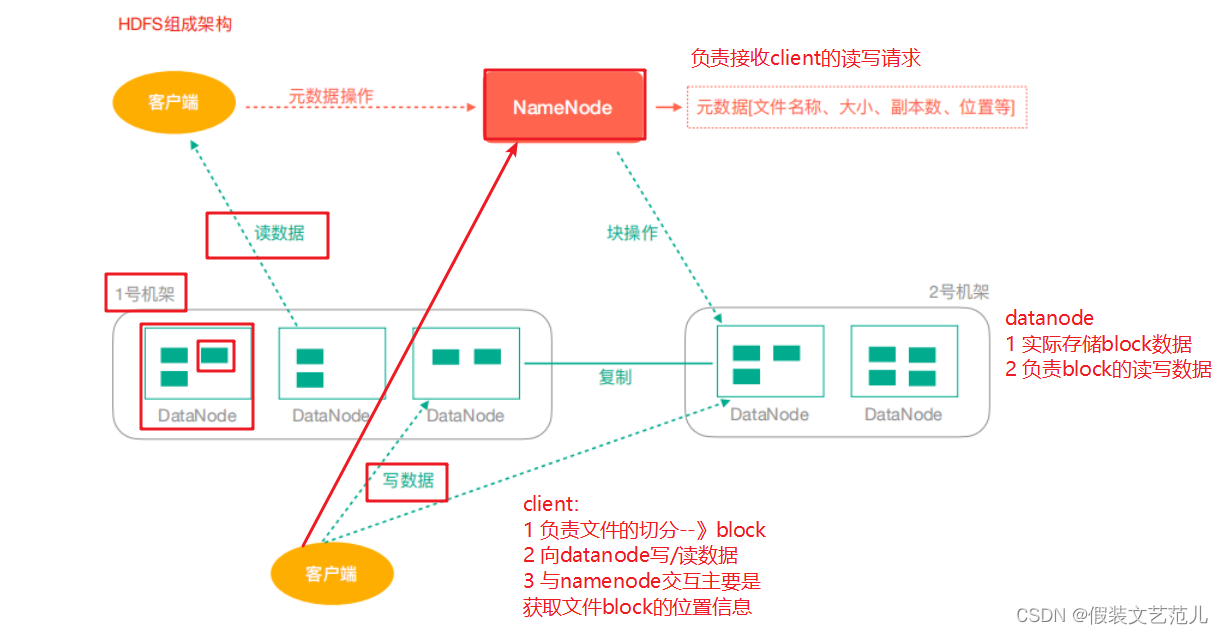
NameNode(nn):hdfs集群的管理者,Master
维护管理hdfs的名称空间(NameSpace)
维护副本策略
记录文件块(Block)的映射信息
负责处理客户端读写请求
DataNode:NameNode下达命令,DataNode执行实际操作,Slave节点。
- 保存实际的数据块
- 负责数据块的读写
Client:客户端
- 上传文件到HDFS的时候,Client负责将文件切分成Block,然后进行上传
- 请求NameNode交互,获取文件的位置信息
- 读取或写入文件,与DataNode交互
- Client可以使用一些命令来管理HDFS或者访问HDFS
1.5 HDFS分布式文件系统-hadoop-最全最完整的保姆级的java大数据学习资料的更多相关文章
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 【史上最全】Hadoop 核心 - HDFS 分布式文件系统详解(上万字建议收藏)
1. HDFS概述 Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用 FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪 ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- 我理解中的Hadoop HDFS分布式文件系统
一,什么是分布式文件系统,分布式文件系统能干什么 在学习一个文件系统时,首先我先想到的是,学习它能为我们提供什么样的服务,它的价值在哪里,为什么要去学它.以这样的方式去理解它之后在日后的深入学习中才能 ...
- HDFS分布式文件系统资源管理器开发总结
HDFS,全称Hadoop分布式文件系统,作为Hadoop生态技术圈底层的关键技术之一,被设计成适合运行在通用硬件上的分布式文件系统.它和现有的分布式文件系统有很多共同点,但同时,它和其他的分布式 ...
- 通过Thrift访问HDFS分布式文件系统的性能瓶颈分析
通过Thrift访问HDFS分布式文件系统的性能瓶颈分析 引言 Hadoop提供的HDFS布式文件存储系统,提供了基于thrift的客户端访问支持,但是因为Thrift自身的访问特点,在高并发的访问情 ...
- 认识HDFS分布式文件系统
1.设计基础目标 (1) 错误是常态,需要使用数据冗余 (2)流式数据访问.数据批量读而不是随机速写,不支持OLTP,hadoop擅长数据分析而不是事物处理. (3)文件采用一次性写多次读的模型, ...
- 1、HDFS分布式文件系统
1.HDFS分布式文件系统 分布式存储 分布式计算 2.hadoop hadoop含有四个模块,分别是 common. hdfs和yarn. common 公共模块. HDFS hadoop dist ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
随机推荐
- 查找Linux下的大目录或文件
目录 du -h --max-depth=1 du -h --max-depth=2 | sort -n du -hm --max-depth=2 | sort -n du -hm --max-dep ...
- SkyWalking简要介绍
什么是 SkyWalking 分布式系统的应用程序性能监视工具,专为微服务.云原生架构和基于容器(Docker.K8s.Mesos)架构而设计.提供分布式追踪.服务网格遥测分析.度量聚合和可视化一体化 ...
- Oracle安装和卸载
Oracle安装: 1. 检查是否安装net framework 3.5 2. 安装win64_11gR2_database服务端 更改安装目录,设置密码 2. 检查服务 services.msc,两 ...
- JSP脚本知识
JSP脚本元素 1.在jsp中嵌入的服务端运行的小程序称为脚本.实质是java程序. 2.脚本元素可以分为三类:表达式.Scriptlet.声明. 表达式 计算java表达式的值,得到的结果转化为字符 ...
- 『现学现忘』Git分支 — 39、Git中分支与对象的关系
目录 1.Git对象之间的关系 2.提交对象与分支的关系 (1)提交对象与分支的关系 (2)分支说明 (3)HEAD与分支的关系 1.Git对象之间的关系 我们之前学了Git的三个对象:提交对象.树对 ...
- 齐博x1动态改变标签调用不同频道的数据
标签默认需要设置标签参数 type 指定调用哪个频道的数据,比如下面的代码,需要默认指定商城的数据, {qb:tag name="qun_pcshow_shop001" type= ...
- 2.签名&初始化&提交
Git设置签名 签名的作用是区分不同操作者的身份,用户的签名信息在每一个版本的提交信息中能够看到, 以此确认本次提交是谁做的,git首次安装必须设置用户签名,否则无法提交代码 这里设置的用户签名和 ...
- vue中push()和splice()的使用方法
vue中push()和splice()的使用方法 push()使用 push() 方法可向数组的末尾添加一个或多个元素,并返回新的长度.注意:1. 新元素将添加在数组的末尾. 2.此方法改变数组的长度 ...
- PCA降维的原理及实现
PCA可以将数据从原来的向量空间映射到新的空间中.由于每次选择的都是方差最大的方向,所以往往经过前几个维度的划分后,之后的数据排列都非常紧密了, 我们可以舍弃这些维度从而实现降维 原理 内积 两个向量 ...
- Java函数式编程:二、高阶函数,闭包,函数组合以及柯里化
承接上文:Java函数式编程:一.函数式接口,lambda表达式和方法引用 这次来聊聊函数式编程中其他的几个比较重要的概念和技术,从而使得我们能更深刻的掌握Java中的函数式编程. 本篇博客主要聊聊以 ...