读取XML文件的几种方式的效率分析
第一种:使用XmlReader来读取。
Stopwatch sw = Stopwatch.StartNew();
List<Dictionary<string, string>> entityInfo = new List<Dictionary<string, string>>();
using (XmlReader reader = new XmlTextReader(compareXmlName))
{
Dictionary<string, string> xmlValue = null;
string key = string.Empty;
while (reader.Read())
{
switch (reader.NodeType)
{
case XmlNodeType.Element:
if (string.Compare(reader.LocalName, "MultiTable",
StringComparison.OrdinalIgnoreCase) == )
{
xmlValue = new Dictionary<string, string>();
}
else if(string.Compare(reader.LocalName,"NewDataSet",
StringComparison.OrdinalIgnoreCase) != )
{
key = reader.LocalName;
}
break;
case XmlNodeType.EndElement:
if (string.Compare(reader.LocalName, "MultiTable",
StringComparison.OrdinalIgnoreCase) == )
{
if (xmlValue != null)
{
entityInfo.Add(xmlValue);
xmlValue = null;
}
}
break;
case XmlNodeType.Text:
if (xmlValue != null)
{
xmlValue.Add(key, reader.Value);
}
break;
}
}
}
TimeSpan ts = sw.Elapsed; List<Customers> packData = new List<Customers>();
foreach (var item in entityInfo)
{
Customers temp = new Customers();
foreach (var sub in item)
{
if (sub.Key == "CustomerID")
{
temp.CustomerID = int.Parse(sub.Value);
}
else if (sub.Key == "CustomerName")
{
temp.CustomerName = sub.Value;
}
else if (sub.Key == "Description")
{
temp.Description = sub.Value;
}
else if (sub.Key == "Boolean")
{
temp.IsEnabled = sub.Value == "true" ? true : false;
}
}
packData.Add(temp);
} dataGridView3.DataSource = packData;
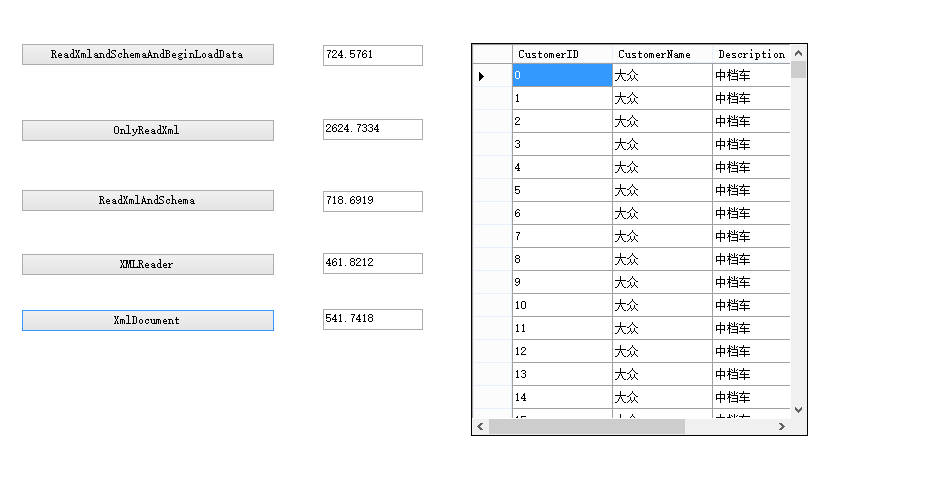
this.textBox9.Text = ts.TotalMilliseconds.ToString();
这种方式其实是最原始的读取方法,读取的时候一个一个的节点来读取,节点的类型有很多,比如Element类型,EndElement类型,Text类型等等,通过这种方式,我们来读取我们需要的数据。这种方式效率最高。
第二种:使用XmlDocument的方式来读取:
Stopwatch sw = Stopwatch.StartNew();
XmlDocument doc = new XmlDocument();
doc.Load(compareXmlName);
XmlNode root = doc.DocumentElement;
XmlNode child = root.FirstChild;
List<Customers> results = new List<Customers>();
while (child != null)
{
XmlNode grandSon = child.FirstChild;
Customers temp = new Customers();
while (grandSon != null)
{
if (grandSon.Name == "CustomerID")
{
temp.CustomerID = int.Parse(grandSon.FirstChild.Value);
}
else if (grandSon.Name == "CustomerName")
{
temp.CustomerName = grandSon.FirstChild.Value;
}
else if (grandSon.Name == "Description")
{
temp.Description = grandSon.FirstChild.Value;
}
else if (grandSon.Name == "Boolean")
{
temp.IsEnabled = grandSon.FirstChild.Value == "true" ? true : false;
}
grandSon = grandSon.NextSibling;
}
results.Add(temp);
child = child.NextSibling;
}
TimeSpan ts = sw.Elapsed; dataGridView3.DataSource = results;
textBox10.Text = ts.TotalMilliseconds.ToString();
这种方式其实也是通过xmlLoader来构造节点的,xmlLoader里面也是XmlReader完成的任务,这种方式的效率也比较高。
第三种:直接使用DataSet来读取,自动判断Schema信息。
DataSet compareDataSet1 = new DataSet("CompareDataSet");
Stopwatch sw = Stopwatch.StartNew();
//读取架构信息
compareDataSet1.ReadXml(compareXmlName, XmlReadMode.Auto);
TimeSpan ts = sw.Elapsed;
this.dataGridView3.DataSource = compareDataSet1.Tables[];
textBox7.Text = ts.TotalMilliseconds.ToString();
这种方式时效率最不高的,在调用ReadXml的时候,也是通过XmlReader来完成的工作,调用XmlLoader来加载数据,加载数据是通过XmlLoader的LoadTable来构造表的数据的。
第四种:也是使用DataSet来读取数据,但是先读取架构信息,并且调用BeginLoadData来关闭通知,索引维护等,这样的速度比第三种要快。
DataSet compareDataSet1 = new DataSet("CompareDataSet");
Stopwatch sw = Stopwatch.StartNew();
//读取架构信息
compareDataSet1.ReadXmlSchema(compareXmlSchemaName);
//防止在修改数据的过程中引发各种约束的检查,并可以提高速度
foreach (DataTable dt in compareDataSet.Tables)
{
dt.BeginLoadData();
}
compareDataSet1.ReadXml(compareXmlName, XmlReadMode.IgnoreSchema);
foreach (DataTable dt in compareDataSet1.Tables)
{
dt.EndLoadData();
}
TimeSpan ts = sw.Elapsed;
this.dataGridView3.DataSource = compareDataSet1.Tables[];
textBox6.Text = ts.TotalMilliseconds.ToString();
第五种:也还是使用DataSet来读取数据,也读取架构信息,但是不调用BeginLoadData方法,在这里,因为没有添加任何的索引,约束等,所以速度和第四种差不多。
DataSet compareDataSet1 = new DataSet("CompareDataSet");
Stopwatch sw = Stopwatch.StartNew();
//读取架构信息
compareDataSet1.ReadXmlSchema(compareXmlSchemaName);
compareDataSet1.ReadXml(compareXmlName, XmlReadMode.IgnoreSchema);
TimeSpan ts = sw.Elapsed;
this.dataGridView3.DataSource = compareDataSet1.Tables[];
textBox8.Text = ts.TotalMilliseconds.ToString();
五种的比较结果,读取10万条数据的结果如下:
http://files.cnblogs.com/files/monkeyZhong/DataSetXML.zip
读取XML文件的几种方式的效率分析的更多相关文章
- java读取XML文件的四种方式
java读取XML文件的四种方式 Xml代码 <?xml version="1.0" encoding="GB2312"?> <RESULT& ...
- 解析Xml文件的三种方式及其特点
解析Xml文件的三种方式 1.Sax解析(simple api for xml) 使用流式处理的方式,它并不记录所读内容的相关信息.它是一种以事件为驱动的XML API,解析速度快,占用内存少.使用 ...
- 浅谈JS中的!=、== 、!==、===的用法和区别 JS中Null与Undefined的区别 读取XML文件 获取路径的方式 C#中Cookie,Session,Application的用法与区别? c#反射 抽象工厂
浅谈JS中的!=.== .!==.===的用法和区别 var num = 1; var str = '1'; var test = 1; test == num //tr ...
- Java 读取 .properties 文件的几种方式
Java 读取 .properties 配置文件的几种方式 Java 开发中,需要将一些易变的配置参数放置再 XML 配置文件或者 properties 配置文件中.然而 XML 配置文件需要通过 ...
- 解析xml文件的四种方式
什么是 XML? XML 指可扩展标记语言(EXtensible Markup Language) XML 是一种标记语言,很类似 HTML XML 的设计宗旨是传输数据,而非显示数据 XML 标签没 ...
- Android-----解析xml文件的三种方式
SAX解析方法介绍: SAX(Simple API for XML)是一个解析速度快并且占用内存少的XML解析器,非常适合用于Android等移动设备.SAX解析XML文件采用的是事件驱动,也就是说, ...
- 【开发笔记】- Java读取properties文件的五种方式
原文地址:https://www.cnblogs.com/hafiz/p/5876243.html 一.背景 最近,在项目开发的过程中,遇到需要在properties文件中定义一些自定义的变量,以供j ...
- Spring 读取XML配置文件的两种方式
import org.springframework.context.ApplicationContext; import org.springframework.context.support.Cl ...
- 解析XML文件的几种方式及其比较
解析xml文件目前比较流行的主要有四种方式: 1. DOM(Document Object Model)它把整个XML文档当成一个对象加载到内 存,不管文档有多大.它一般处理小文件 2.SAX(Si ...
随机推荐
- xilinx FPGA普通IO作PLL时钟输入
本帖转自于 :http://www.cnblogs.com/jamesnt/p/3535073.html 在xilinx ZC7020的片子上做的实验; [结论] 普通IO不能直接作PLL的时钟输入, ...
- centos7 install mongodb
$vi /etc/yum.repos.d/mongodb-org-3.0.repo [mongodb-org-3.0] name=MongoDB Repository baseurl=http://r ...
- strcmp() Anyone?
uva11732:http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_prob ...
- 属性动画(Property Animation)资源
Animator 代表一个属性动画,但它只是一个抽象类,通常会使用它的子类:AnimatorSet.ValueAnimator.ObjectAnimator.TimeAnimator. 定义属性动画的 ...
- Android Service 简介
Service是Android系统中的一种组件,它跟Activity的级别差不多,但是它不能自己运行,只能后台运行,并且可以和其他组件进行交互.Service是没有界面的长生命周期的代码.Servic ...
- POJ3041 Asteroids(二分图最大匹配)
题目链接. 分析: 暂略. AC代码: #include <iostream> #include <cstdio> #include <cstring> #incl ...
- Graph Search图谱搜索
来自百度百科的解释: Graph Search为2013年1月16日,Facebook首席执行官马克·扎克伯格(Mark Zuckerberg)在门罗帕克公司总部召开的新闻发布会上宣布推出社交搜索工具 ...
- 【转】Android中的内存管理--不错不错,避免使用枚举类型
原文网址:http://android-performance.com/android/2014/02/17/android-manage-memory.html 本文内容翻译自:http://dev ...
- 帕累托分析法(Pareto Analysis)(柏拉图分析)
帕累托分析法(Pareto Analysis)(柏拉图分析) ABC分类法是由意大利经济学家帕雷托首创的.1879年,帕累托研究个人收入的分布状态图是地,发现少数人收入占全部人口收入的大部分,而多数人 ...
- Reverse Linked List II——LeetCode
Reverse a linked list from position m to n. Do it in-place and in one-pass. For example:Given 1-> ...