Annoy 近邻算法
Annoy
随机选择两个点,以这两个节点为初始中心节点,执行聚类数为2的kmeans过程,最终产生收敛后两个聚类中心点
二叉树底层是叶子节点记录原始数据节点,其他中间节点记录的是分割超平面的信息


但是上述描述存在两个问题:
(1)查询过程最终落到叶子节点的数据节点数小于 我们需要的Top N相似邻居节点数目怎么办?
(2)两个相近的数据节点划分到二叉树不同分支上怎么办?
针对这个问题可以通过两个方法来解决:
(1)如果分割超平面的两边都很相似,那可以两边都遍历
(2) 建立多棵二叉树树,构成一个森林
(3)所有树返回近邻点都插入到优先队列中,求并集去重, 然后计算和查询点距离, 最终根据距离值从近距离到远距离排序, 返回Top N近邻节点集合
Summary of features
- Euclidean distance, Manhattan distance, cosine distance, Hamming distance, or Dot (Inner) Product distance
- Cosine distance is equivalent to Euclidean distance of normalized vectors = sqrt(2-2*cos(u, v))
- Works better if you don't have too many dimensions (like <100) but seems to perform surprisingly well even up to 1,000 dimensions
- Small memory usage
- Lets you share memory between multiple processes
- Index creation is separate from lookup (in particular you can not add more items once the tree has been created)
- Native Python support, tested with 2.7, 3.6, and 3.7.
- Build index on disk to enable indexing big datasets that won't fit into memory (contributed by Rene Hollander)
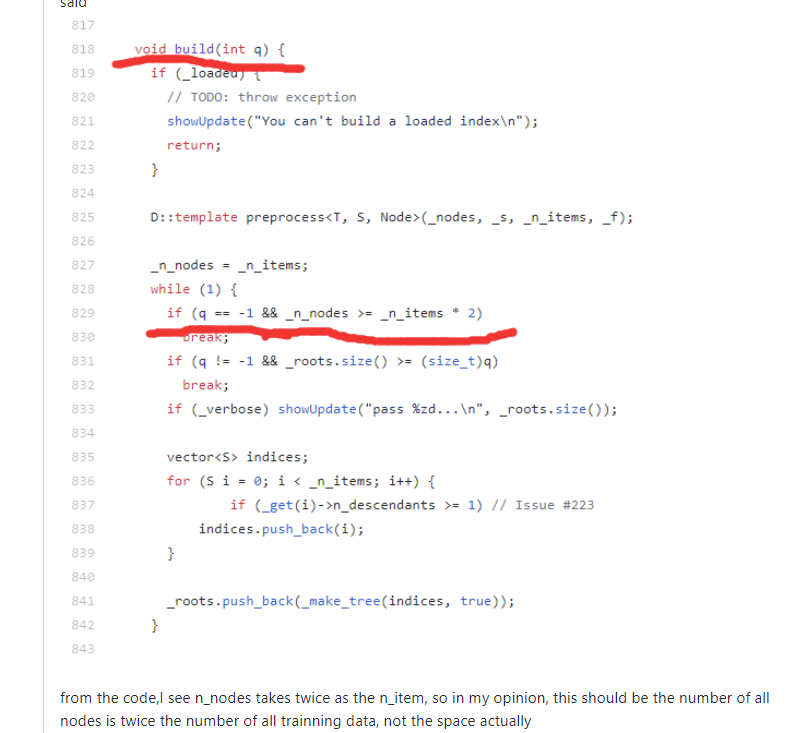
build(-1)的树的颗数问题
:所有节点的个数是trainning data的2倍左右:https://github.com/spotify/annoy/issues/338
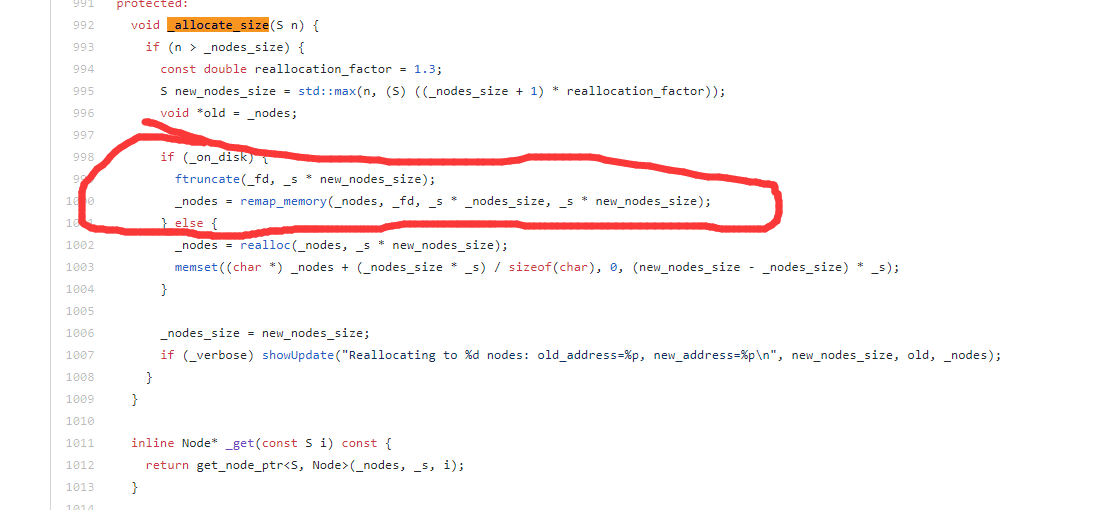
build_on_disk 问题
写文件时候,会向磁盘写
Annoy 近邻算法的更多相关文章
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- KNN近邻算法
K近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表.kNN算法的核 ...
- k近邻算法的Java实现
k近邻算法是机器学习算法中最简单的算法之一,工作原理是:存在一个样本数据集合,即训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据和所属分类的对应关系.输入没有标签的新数据之后, ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- k近邻算法
k 近邻算法是一种基本分类与回归方法.我现在只是想讨论分类问题中的k近邻法.k近邻算法的输入为实例的特征向量,对应于特征空间的点,输出的为实例的类别.k邻近法假设给定一个训练数据集,其中实例类别已定. ...
- KNN K~近邻算法笔记
K~近邻算法是最简单的机器学习算法.工作原理就是:将新数据的每一个特征与样本集中数据相应的特征进行比較.然后算法提取样本集中特征最相似的数据的分类标签.一般来说.仅仅提取样本数据集中前K个最相似的数据 ...
随机推荐
- 【题解】亚瑟王 HNOI 2015 BZOJ 4008 概率 期望 动态规划
传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=4008 一道不简单的概率和期望dp题 根据期望的线性性质,容易想到,可以算出每张卡的期望伤害, ...
- Qt Designer 的使用
1. Qt Designer 快速入门 Qt Designer 是交互式可视化GUI设计工具,可以帮助我们快速开发 PyQt 程序的速度. 它生成的 UI 界面是一个后缀为 .ui 的文件,可以通过 ...
- H5新特性之拖拽文件
H5新增了drag事件,在H5中拖拽是十分常见的. 可以拖拽的分为页面内的和页面外的 页面内的一般默认可以拖拽的是img和a标签 页面外的常指的是文件 上代码吧~ let zoom = documen ...
- LVM基本概念及工作原理
LVM基本概念及工作原理 背景知识: 一直困惑于LVM,特地找资料查了查,终于对LVM的概念和工作原理有了深入的理解.接下来记录下.新的技术出来必定是为了改变现有的不足,所以LVM的出现是由于对现有磁 ...
- 函数和常用模块【day05】:文件目录开发规范(七)
本节内容 1.背景 2.设计目录结构的好处 3.关于readme的内容 4.关于requirements.txt和setup.py 5.关于配置文件的使用方法 一.背景 "设计项目目录结构& ...
- 微信现金红包 python
微信现金红包发送接口,好像没法限制一个用户一个活动只能领取一次红包,在调用红包接口上,自己做了限制 REDPACK_RECORD 建表sql -- Create table create table ...
- 如何理解<base href="<%=basePath%>"
原文链接http://316325524.blog.163.com/blog/static/6652052320111118111620897/ "base href " 今天在写 ...
- 树的dfs序.欧拉序
dfs序 ==先序,连续一段区间就是子树
- android BroadcastReceiver组件简单的使用
1.清单文件 <?xml version="1.0" encoding="utf-8"?> <manifest xmlns:android=& ...
- 第4月第20天 python re xls2lua
1. import re replace_values = ['one', 'two', 'three'] replace_keys = [str(i) for i in xrange(1, 4)] ...