大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵。
一、概述
本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建hadoop平台(2.1)。hadoop独立环境和伪分布式环境都无法发挥hadoop的价值,若想利用hadoop进行一些有价值的工作,必须搭建hadoop分布式集群环境。
下文以三台虚拟机为基础搭建集群环境,系统版本为CentOS-7,虚拟机地址分别为:192.168.1.106、192.168.1.109、192.168.1.110
二、修改主机名
编辑network文件,文件位于/etc/sysconfig路径下,若文件为空则添加如下内容,如不为空,则修改:HOSTNAME=namenode,namenode为修改的主机名。
NETWORKING=yes
HOSTNAME=namenode
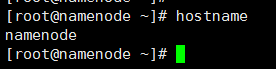
修改192.168.1.106的主机名为namenode、192.168.1.109的主机名为datanode01、192.168.1.110的主机名为datanode02。修改后键入命令hostname验证是否修改成功,如在192.168.1.106上键入hostname后出现namenode则表示修改成功,如下图所示:
三、修改hosts
修改hosts是为了配置前面修改的主机名和IP的映射关系。hosts文件位于/etc路径下,三台虚拟机都需要添加如下内容:
192.168.1.106 namenode
192.168.1.109 datanode01
192.168.1.110 datanode02
修改hosts
修改后效果如图所示:

四、关闭防火墙(三台机器均需关闭)
1、查看防火墙状态
firewall-cmd --state
查看防火墙状态
如下则表示防火墙处于开启状态:

2、关闭防火墙
systemctl stop firewalld.service
临时关闭防火墙
再通过service iptables status查看防火墙状态,如下则表示防火墙已经关闭:

但是,这仅仅是在当前状态下关闭防火墙,系统重启后防火墙仍然会自动开启,所以需要禁止开机启动防火墙
systemctl disable firewalld.service
禁止开机启动防火墙
执行命令后重启系统生效。
五、关闭selinux(三台机器均需关闭)
selinux是一个防护程序,类似于防火墙。编辑selinux文件,文件位于:/etc/sysconfig路径下
修改SELINUX=enforcing为SELINUX=disabled,修改后效果如下:

六、ssh免密码登录设置
hadoop集群模式下,各主机之间需要互相通信,比如上传文件到HDFS文件系统上时,都需要对文件进行备份。所以需要各机器之间能够进行免密码登录。
1、生成秘钥:输入命令:ssh-keygen -t rsa,按3次回车之后会生成秘钥。
2、拷贝秘钥到本机和其他两台机器上:分别执行命令:ssh-copy-id 192.168.1.109,ssh-copy-id 192.168.1.110拷贝秘钥。
3、免密码登录验证:执行命令ssh 192.168.1.109,如果不需要输入密码就能登录到109机器上,则免密码登录设置成功,110也执行相同的测试。
七、安装JDK并配置环境变量(三台机器均需要做相同的设置)
1、创建目录/home/software,上传JDK到该目录下并解压,此处使用的JDK版本是jdk1.8.0_131
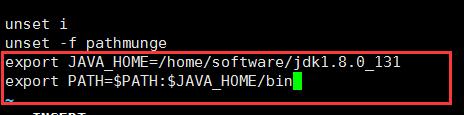
2、配置环境变量:编辑文件profile,文件位于:/etc目录下,在文件尾部添加如下内容:
export JAVA_HOME=/home/software/jdk1.8.0_131
export PATH=$PATH:$JAVA_HOME/bin
配置java环境变量
如图所示:
3、输入命令source /etc/profile是文件立即生效
4、测试:在任意路径下输入命令:java -version,若打印出java的版本信息,则代表java安装成功。如下所示:

八、安装hadoop集群
1、下载hadoop安装包
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/,这是hadoop-2.7.3的项目存档地址。随着Apache各项目的版本更新,各项目的网站上只上架最新版本和近期历史重要版本,如果网站下架的项目,需要到Apache存档地址上寻找,该地址是:https://archive.apache.org/dist/,hadoop存档地址是:https://archive.apache.org/dist/hadoop/。在hadoop2.7.3版本的地址下,下载hadoop-2.7.3.tar.gz文件包。如下图所示:

2、安装hadoop并配置环境变量
①、上传hadoop安装包hadoop-2.7.3.tar.gz到/home/software目录下并解压,当然,也可以放在其他目录下。
②、编辑文件profile,文件位于/etc目录下,添加如下代码:
export HADOOP_HOME=/home/software/hadoop-2.7.3
配置hadoop环境变量
并在PATH变量后追加如下代码:
$HADOOP_HOME/bin:$HADOOP_HOME/sbin
追加PATH变量
输入命令source /etc/profile使profile配置文件立即生效。最终profile文件效果如下所示:

③、验证hadoop环境变量是否配置成功:在任何路径下输入命令hadoop,如果打印相关信息,则代表hadoop的安装和环境变量配置成功,如下图所示:

至此,hadoop安装和配置环境变量成功,但是,这仅仅是进行了基础的安装,还需要进行一些配置,使hadoop能真正的工作。
以上第八小节的操作,在一台机器上(我使用namenode机器)配置即可,其他两台机器只需要按第②、③点编辑profile文件,因为在接下来的内容中会接着配置hadoop,全部配置完成后,把hadoop-2.7.3文件拷贝到其他机器即可。
九、hadoop配置
1、修改hadoop-env.sh文件,文件位于/home/software/hadoop-2.7.3/etc/hadoop目录下。
修改java_home,找到代码 export JAVA_HOME=${JAVA_HOME} ,修改为JAVA_HOME的值,即:export JAVA_HOME=/home/software/jdk1.8.0_131
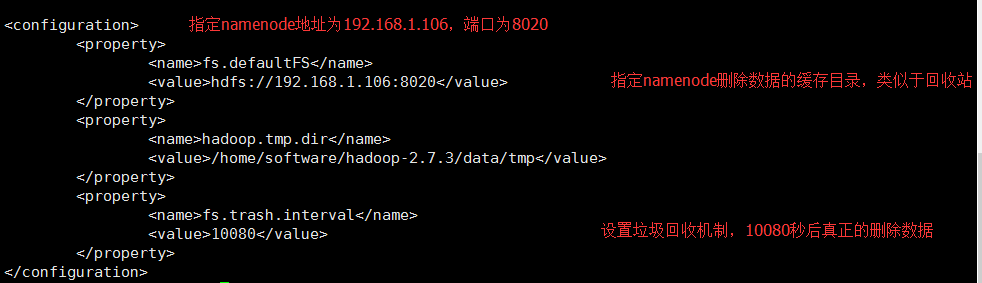
2、修改core-site.xml文件,文件同样位于/home/software/hadoop-2.7.3/etc/hadoop目录下。
找到<configuration>节点,在该节点下添加如下代码:
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.106:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-2.7.3/data/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
修改core-site.xml
修改后效果如下:
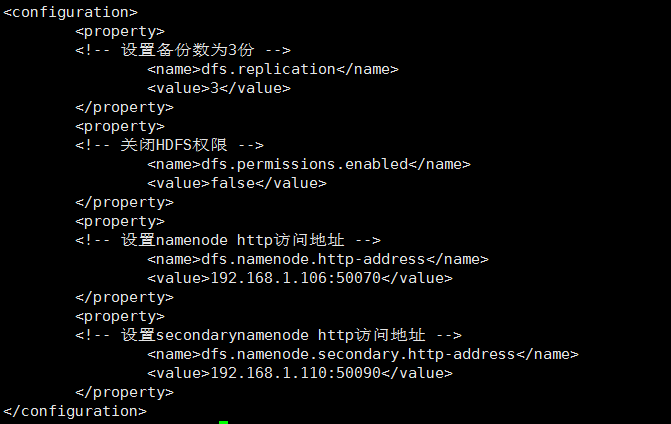
3、 修改hdfs-site.xml文件,文件同样位于/home/software/hadoop-2.7.3/etc/hadoop目录下。
找到<configuration>节点,在该节点下添加如下代码:
<property>
<!-- 设置备份数为3份 -->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!-- 关闭HDFS权限 -->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<!-- 设置namenode http访问地址 -->
<name>dfs.namenode.http-address</name>
<value>192.168.1.106:50070</value>
</property>
<property>
<!-- 设置secondarynamenode http访问地址 -->
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.110:50090</value>
</property>
修改hdfs-site.xm
修改后效果如下:
4、修改mapred-site.xml文件,文件同样位于/home/software/hadoop-2.7.3/etc/hadoop目录下,但是该路径下并不存在mapred-site.xml文件,只存在mapred-site.xml.template文件,将mapred-site.xml.template文件修改为mapred-site.xml即可。
找到<configuration>节点,在该节点下添加如下代码:
<property>
<!-- 指定mapreduce使用yarn框架来调度 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!-- 指定jobhistory地址 -->
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.106:10020</value>
</property>
<property>
<!-- 指定jobhistorywebapp地址 -->
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.106:19888</value>
</property>
<property>
<!-- 开启uber模式 -->
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
修改mapred-site.xm
修改后效果如下:
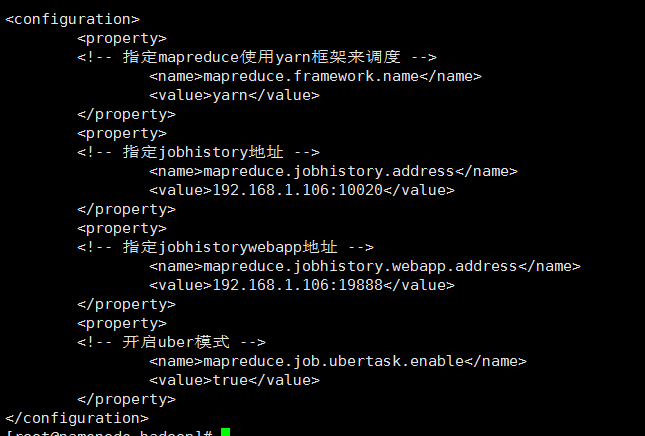
5、修改yarn-site.xml文件,文件同样位于/home/software/hadoop-2.7.3/etc/hadoop目录下。
找到<configuration>节点,在该节点下添加如下代码:
<property>
<!-- mapreduce为shuffle -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 设置resourcemanager主机 -->
<name>yarn.resourcemanager.hostname</name>
<value>192.168.1.109</value>
</property>
<property>
<!-- 设置web安全任务的主机和端口 -->
<name>yarn.web-proxy.address</name>
<value>192.168.1.109:8089</value>
</property>
<property>
<!-- 开启日志,可以在yarn中查看日志 -->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!-- 设置yarn删除日志的时间 -->
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<!-- 设置yarn的内存 -->
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
<property>
<!-- 设置yarn的cpu为8核 -->
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>8</value>
</property>
修改yarn-site.xml
修改后效果如下:
6、修改slaves文件,文件同样位于/home/software/hadoop-2.7.3/etc/hadoop目录下。
hadoop可以通过脚本命令在整合集群范围内启动和停止守护进程,但是,需要告诉命令hadoop集群中有哪些机器,slaves文件的作用正是如此,slaves文件中包含了机器的主机名或者是IP地址,每行代表一个机器信息,该文件列举了可以运行datanode和节点管理器(nodemanager)的机器。当然,slaves文件可以不放在/home/software/hadoop-2.7.3/etc/hadoop目录下,通过修改hadoop-env.sh配置文件中的HADOOP_SLAVES设置可以把slaves放到别的地方并赋予一个别名。
在slaves中添加如下内容:
192.168.1.106
192.168.1.109
192.168.1.110
hadoop集群主机地址
修改后效果如下:
7、分发hadoop-2.7.3
进行如上配置之后,把hadoop-2.7.3文件拷贝到其他机器上,注意,先格式化namenode之后再拷贝。
· ①、格式化hadoop:进入到hadoop-2.7.3文件下,及/home/software/hadoop-2.7.3路径下,输入命令:bin/hadoop namenode -format,等待格式化完成,格式化完成之后,在屏幕上打印出来的最后几行,可以看到has been successfully formatted代表格式化成功:

②、分发hadoop-2.7.3文件到其他机器上:使用scp -r hadoop-2.7.3 192.168.1.109:/home/software、scp -r hadoop-2.7.3 192.168.1.110:/home/software命令把hadoop-2.7.3文件拷贝到192.168.1.109和192.168.1.110机器上的/home/software路径下。
8、 启动服务
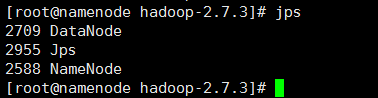
①、启动hdfs服务:在namenode主机上,进入/home/software/hadoop-2.7.3目录下,输入命令sbin/start-dfs.sh,等待服务启动。启动服务的过程中,会提示是否确定连接其他机器(Are you sure you want to continue connecting (yes/no)?),输入yes即可。启动成功之后,输入jps命令可以看到启动了NameNode和DataNode守护进程;其他两台机器上分别启动了DataNode,SecondaryNameNode、DataNode。
②、启动yarn服务:启动yarn服务需要在192.168.1.109机器上启动,因为在yarn-site.xml配置文件中,配置了yarn的服务地址为192.168.1.109。进入目录/home/software/hadoop-2.7.3下,输入命令:sbin/start-yarn.sh,等待服务启动。
③、启动jobhistory:在192.168.1.106机器上启动jobhistory,进入目录/home/software/hadoop-2.7.3下,输入命令:sbin/mr-jobhistory-daemon.sh start historyserver,等待服务启动。
④、启动proxyserver防护进程:在192.168.1.109机器上启动proxyserver,进入目录/home/software/hadoop-2.7.3下,输入命令:sbin/yarn-daemon.sh start proxyserver,等待服务启动。
9、通过web界面查看hdfs和yarn
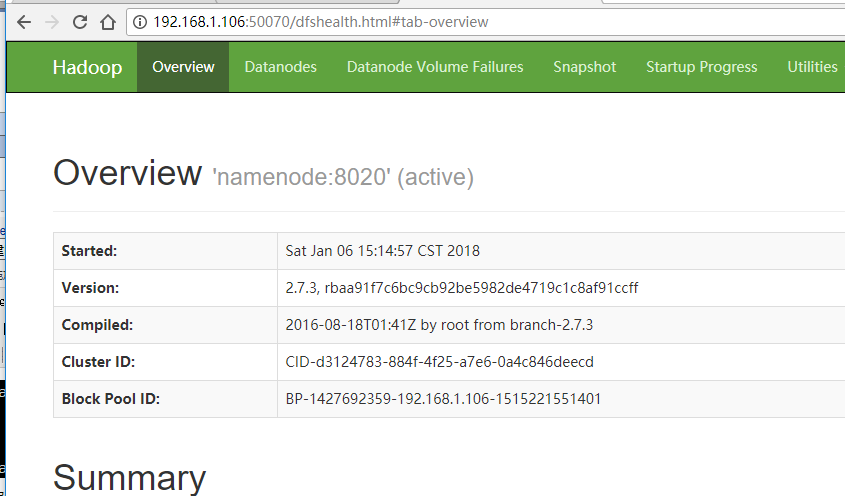
①、在浏览器输入地址:192.168.1.106:50070,能看到如下hdfs web界面:
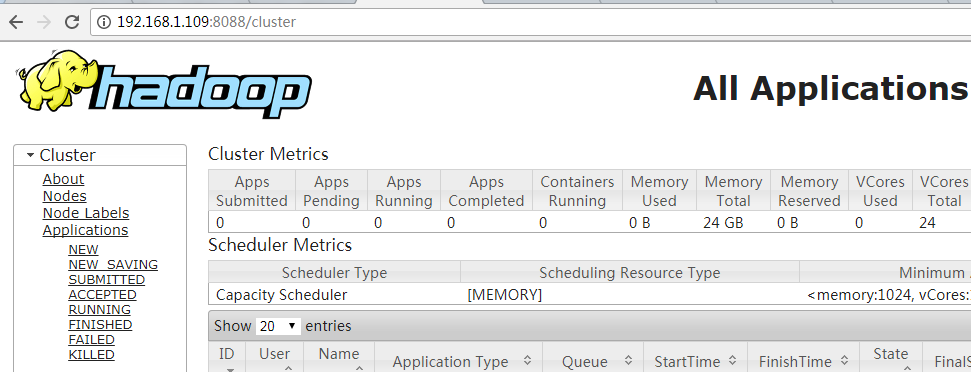
②、在浏览器输入地址:192.168.1.109:8088,能看到如下yarn web界面:
十、结语
至此,hadoop集群模式安装并配置成功,可以在该集群环境上部署hadoop的应用,比如hive、hue、impala等应用,使hadoop投入工作。但是,此时的集群并不健壮,还需要进一步配置hadoop。在接下来的博文中会详细记录。
大数据Hadoop学习之搭建hadoop平台(2.2)的更多相关文章
- 大数据Hadoop学习之搭建Hadoop平台(2.1)
关于大数据,一看就懂,一懂就懵. 一.简介 Hadoop的平台搭建,设置为三种搭建方式,第一种是"单节点安装",这种安装方式最为简单,但是并没有展示出Hadoop的技术优势,适合 ...
- 【大数据系列】windows搭建hadoop开发环境
一.安装JDK配置环境变量 已经安装略过 二.安装eclipse 已经安装略过 三.安装Ant 1.下载http://ant.apache.org/bindownload.cgi 2.解压 3.配置A ...
- 大数据开发学习之构建Hadoop集群-(0)
有多种方式来获取hadoop集群,包括从其他人获取或是自行搭建专属集群,抑或是从Cloudera Manager 或apach ambari等管理工具来构建hadoop集群等,但是由自己搭建则可以了解 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据攻城狮之Hadoop伪分布式篇
对于初学大数据的萌新来说,初次接触Hadoop伪分布式搭建的同学可能是一脸萌笔的,那么这一次小编就手把手的教大家在centos7下搭建Hadoop伪分布式. 底层环境: VMware Workstat ...
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
随机推荐
- 文件系统常用命令df、du、fsck、dumpe2fs
df 查看文件系统 [root@localhost ~]# df 文件系统 1K-块 已用 可用 已用% 挂载点 /dev/sda5 16558080 1337676 15220404 9% / de ...
- cocoapods使用 swift注意事项
版权声明:本文为博主原创文章,未经博主允许不得转载. 说明:2015年12月2日更新,增加一个可能遇到的问题,优化排版.使用CocoaPods过程中遇到问题,欢迎评论交流. 一.CocoaPods的安 ...
- 3.Nginx常用功能介绍
Nginx常用功能介绍 Nginx反向代理应用实例 反向代理(Reverse Proxy)方式是指通过代理服务器来接受Internet上的连接请求,然后将请求转发给内部网络上的服务器,并且从内部网络服 ...
- rabbitMQ教程(三) spring整合rabbitMQ代码实例
一.开启rabbitMQ服务,导入MQ jar包和gson jar包(MQ默认的是jackson,但是效率不如Gson,所以我们用gson) 二.发送端配置,在spring配置文件中配置 <?x ...
- 【quickhybrid】iOS端的项目实现
前言 18年元旦三天内和朋友突击了下,勉强是将雏形做出来了,后续的API慢慢完善.(当然了,主力还是那个朋友,本人只是初涉iOS,勉强能看懂,修修改改而已) 大致内容如下: JSBridge核心交互部 ...
- java接入创蓝253短信验证码
说明 项目是springboot框架 1.短信配置文件 包含验证码发送路径.用户名.密码 chuanglan.requesturl= chuanglan.account= chuanglan.pswd ...
- idea激活网站地址,亲测可用(windows7,idea 2016)
help-register-license server,然后输入 http://idea.iteblog.com/key.php
- Python+selenium+eclipse+pydev自动化测试环境搭建
一. 安装python 1.下载安装python 可访问python的官方网站:http://www.Python.prg找到下载页面下载需要的版本,可下载python2.x或者pyth ...
- 关于 Python 入门的一些问题?
一.用 python 能够做什么?解决什么问题? A1:理论上来说,计算机能做什么,python 语言就能让它做什么,也即 python能做什么. 数值计算.机器学习.爬虫.云相关开发.自动化测试.运 ...
- [js高手之路] 跟GhostWu一起封装一个字符串工具库-扩展trim,trimLeft,trimRight方法(2)
我们接着上一篇的继续,在上一篇我们完成了工具库的架构,本文扩展字符串去空格的方法, 一共有3个 1,trimLeft: 去除字符串左边的空格 2,trimRight: 去除字符串右边的空格 3,tri ...