python内置模块之re模块
内容概要
re模块常用方法
findall
search
match
re模块其他方法
split
sub
subn
compile
finditer
findall 对无名分组优先展示
re实战之爬取红牛分公司数据
内容详细
re模块常用方法
在python要想使用正则必须借助于模块,re就是其中之一
1、findall
查找字符串中所有匹配到的字符,并返回一个列表,
没有匹配数据则返回一个空列表
import re
re.findall('正则表达式','带匹配的文本') # 根据正则匹配除所有符合条件的数据
res = re.findall('b','eva jason jackson')
print(res) # ['a', 'a', 'a']
2、search
查找字符串中的指定的字符,匹配到一个就立刻停止,并返回一个对象,需要用group方法取值
res = re.search('正则表达式','带匹配的文本') # 根据正则匹配到一个符合条件的就结束
res = re.search('a','eva jason jackson')
print(res) # 结果对象
print(res.group()) # 正在的结果
if res:
print(res.group())
else:
print('不好意思 没有找到')
如果没有匹配到字符会返回一个None,并且调用group后会报错
3、match
查找字符串中的指定的字符,只匹配开头的字符,返回一个对象,需要用group方法取值
res = re.match('a','abac') # 根据正则从头开始匹配(文本内容必须在开头匹配上)
print(res)
print(res.group())
if res:
print(res.group())
else:
print('不好意思 没有找到')
如果没有符合条件的数据 那么match返回None 并且使用group会直接报错
re模块其他方法
1、split
类似字符串的切割,不过这里就算切割字母左右没有字符也会切割出一个空 ""
import re
先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
res = re.split('[ab]','abcd')
print(res) # ['', '', 'cd']
2、sub
类似字符串内置方法的replace
# 类似于字符串类型的replace方法
res = re.sub('\d','H','eva3jason4yuan4',1) # 替换正则匹配到的内容
res = re.sub('\d','H','eva3jason4yuan4') # 不写默认替换所有
print(res) # evaHjason4yuan4
3、subn
替换完成后会返回一个元组 ("更换后的字符串", 被更换的个数)
"""返回元组 并提示替换了几处"""
# res = re.subn('\d','H','eva3jason4yuan4',1)
# print(res) # ('evaHjason4yuan4', 1)
# res = re.subn('\d','H','eva3jason4yuan4')
# print(res) # ('evaHjasonHyuanH', 3)
4、compile
定义一个固定的正则表达式,可以多次重复使用匹配不同的字符串
point = re.compile('<a>(.*?)</a>')
res1 = point.findall(date1)
res2 = point.search(date2)
res3 = point.match(date3)
res3 = point.finditer(date4)
regexp_obj = re.compile('\d+')
res = regexp_obj.search('absd213j1hjj213jk')
res1 = regexp_obj.match('123hhkj2h1j3123')
res2 = regexp_obj.findall('1213k1j2jhj21j3123hh')
print(res,res1,res2)
5、finditer
与findall的作用一致,但findall返回的是一个列表,当数据量很大,会特别占用内存空间
而finditer会返回一个可迭代对象,当需要数据时,迭代获取即可
# res = re.finditer('\d+','ashdklah21h23kj12jk3klj112312121kl131')
# print([i.group() for i in res])
6、search对分组的索引取值展示
# res = re.search('^[1-9](\d{14})(\d{2}[0-9x])?$','110105199812067023')
# print(res)
# print(res.group()) # 110105199812067023
# print(res.group(1)) # 10105199812067
# print(res.group(2)) # 023
7、findall 对无名分组优先展示
findall针对分组优先展示 无名分组
res = re.findall("^[1-9]\d{14}(\d{2}[0-9x])?$",'110105199812067023')
print(res) # ['023']
取消分组优先展示 无名分组
res1 = re.findall("^[1-9](?:\d{14})(?:\d{2}[0-9x])?$",'110105199812067023')
print(res1)
8、有名分组
res = re.search('^[1-9](?P<xxx>\d{14})(?P<ooo>\d{2}[0-9x])?$','110105199812067023')
print(res)
print(res.group()) # 110105199812067023
print(res.group(1)) # 10105199812067 无名分组的取值方式(索引取)
print(res.group('xxx')) # 10105199812067
print(res.group('ooo')) # 023
正则实战案例
1、登录红牛官网 点击分支结构网页 http://www.redbull.com.cn/about/branch
2、如图所示,爬取所有分公司名称,地址,邮箱,电话等信息
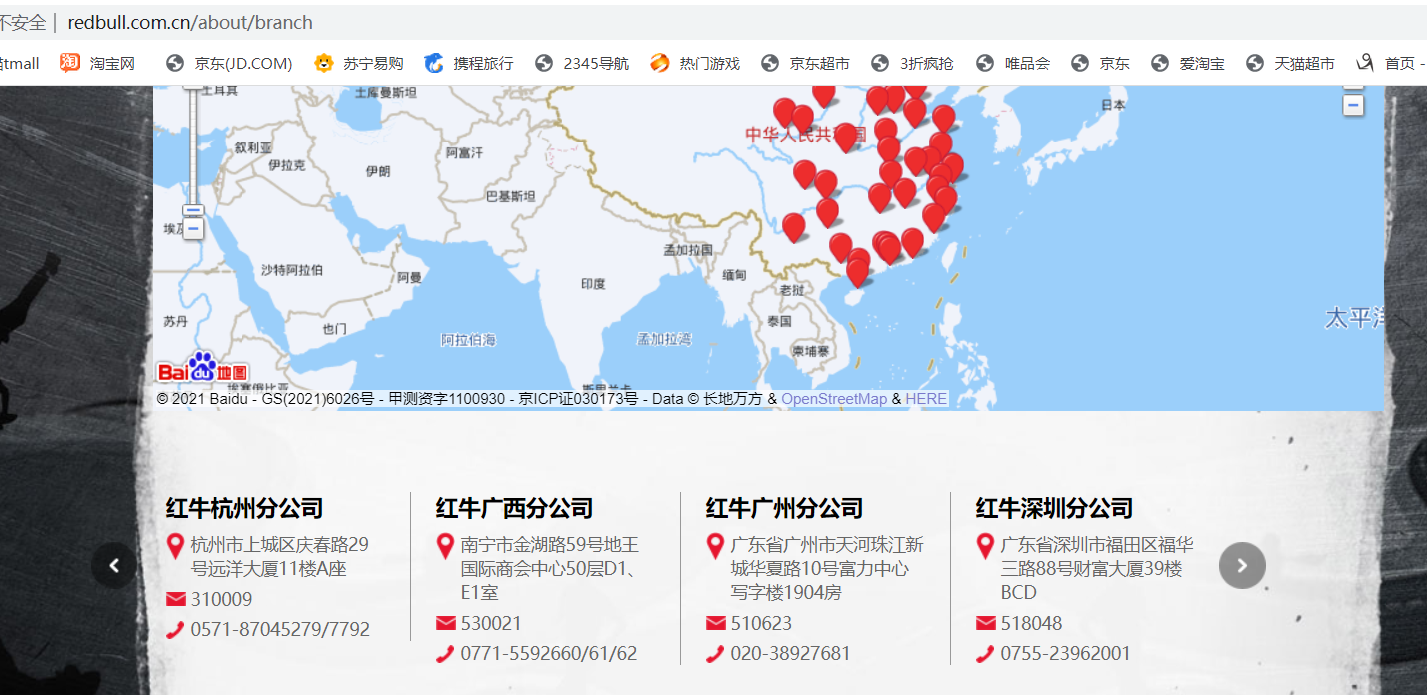
3、右键点击查看网页源代码,全选网页代码复制到pychram的文件中

4、新建py文件,打开并读取网页源码文件,用正则表达式筛选分公司信息
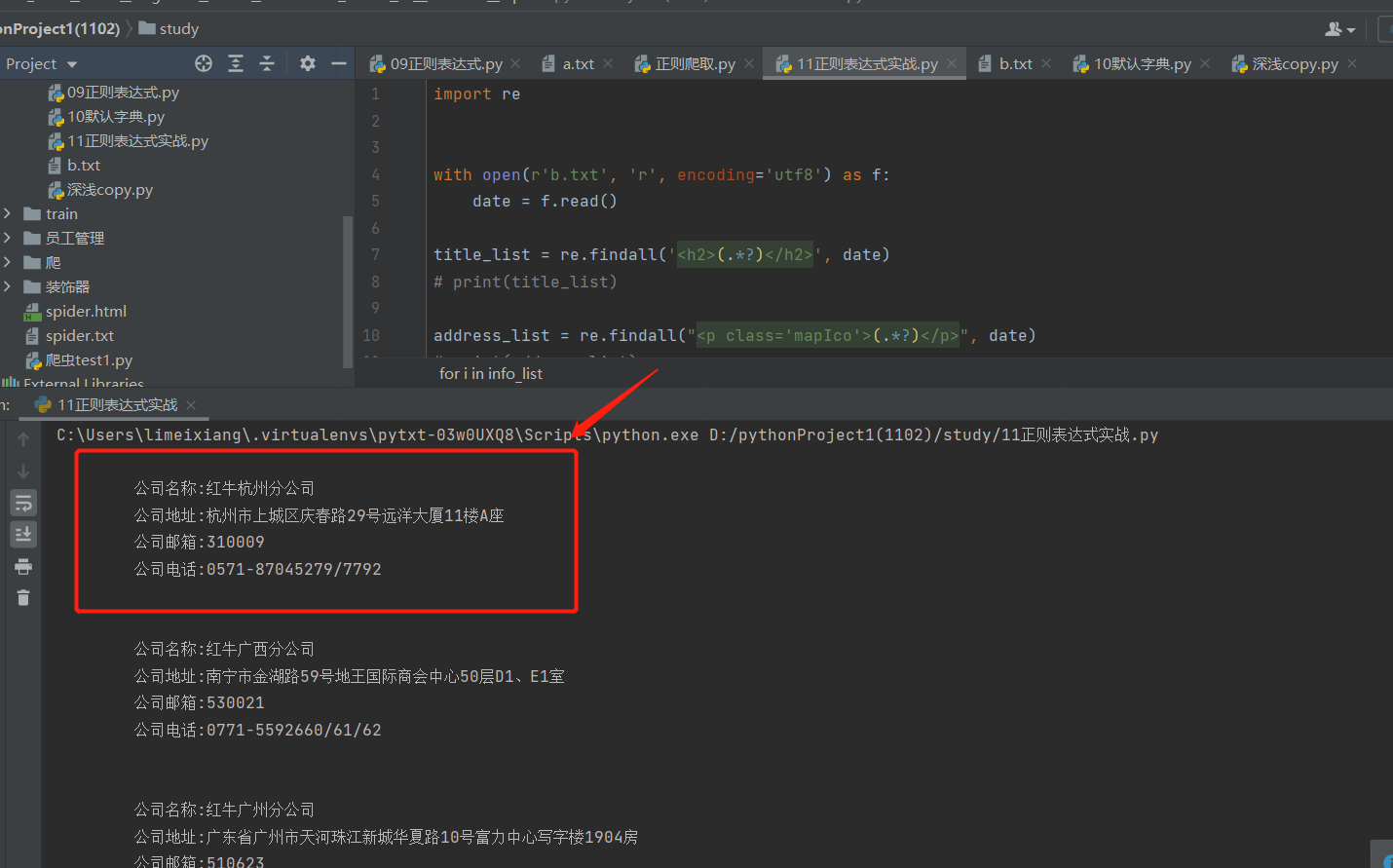
import re
# 读取带匹配的数据
with open(r'a.txt', 'r', encoding='utf8') as f:
data = f.read()
# 利用正则匹配数据
# 分公司名称
title_list = re.findall('<h2>(.*?)</h2>', data)
# print(title_list)
# 分公司地址
address_list = re.findall("<p class='mapIco'>(.*?)</p>", data)
# print(address_list)
# 分公司邮箱
email_list = re.findall("<p class='mailIco'>(.*?)</p>", data)
# print(email_list)
# 分公司电话
phone_list = re.findall("<p class='telIco'>(.*?)</p>", data)
res = zip(title_list, address_list, email_list, phone_list)
for data_tuple in res:
print("""
公司名称:%s
公司地址:%s
公司邮箱:%s
公司电话:%s
""" % (data_tuple[0], data_tuple[1], data_tuple[2], data_tuple[3]))
python内置模块之re模块的更多相关文章
- Python内置模块和第三方模块
1.Python内置模块和第三方模块 内置模块: Python中,安装好了Python后,本身就带有的库,就叫做Python的内置的库. 内置模块,也被称为Python的标准库. Python 2.x ...
- python内置模块(time模块)
常用的python内置模块 一.time模块 在python的三种时间表现形式: 1.时间戳,给电脑看的. - 自1970-01-01 00:00:00到当前时间,按秒计算,计算了多少秒. impor ...
- 8.python内置模块之random模块简介
Python中的random模块用于生成随机数. 常用的7个函数: 1.random.random():返回一个[0,1)之间的随机浮点值(双精度) 2.random.uniform(a,b):返回[ ...
- Python内置模块之time模块
1:概述 时间表示的分类 时间戳 格式化的时间字符串 结构化时间 时间戳:时间戳表示的是从1970年1月1日整0点到目前秒的偏移量,数据类型是浮点型,主要用来让计算机看的 格式化的时间字符串:如 20 ...
- Python 内置模块:os模块
Python os模块包含普遍的操作系统功能.如果你希望你的程序能够与平台无关的话,这个模块是尤为重要的.(一语中的) 二.常用方法 1.os.name 输出字符串指示正在使用的平台.如果是windo ...
- 13.python内置模块之re模块
什么是正则? 正则表达式也称为正则,是一个特殊的字符序列,能帮助检查一个字符串是否与某种模式匹配.可以用来进行验证:邮箱.手机号.qq号.密码.url = 网站地址.ip等.正则不是python语言独 ...
- 12.python内置模块之sys模块介绍
python的sys模块是与python解释器交互的一个接口,提供对解释器使用或维护的一些变量的访问,即与解释器强烈交互的函数. sys模块的常用函数: 1.sys.argv:命令行参数列表.第一个元 ...
- 10.python内置模块之os模块
os模块的作用:os 模块提供了非常丰富的方法用来处理文件和目录(管理和维护目录以及文件). os.path模块的作用:主要用于获取文件的属性(管理路径的(物理地址)). 小生总结了一些平时常用到的属 ...
- Python内置模块之序列化模块
序列化模块 json dumps loads dump load pickle dumps loads dump load shelve json 1: dumps/loads import json ...
随机推荐
- mybatis学习笔记(四)
resultType 语句返回值类型的完整类名或别名 resultType 返回的是一个map集合,key是列名,value是对应的值 使用resultMap实现联表查询 resultMap 查询的结 ...
- mysql数据库读写分离教程
注意:实现MySQL读写分离的前提是我们已经将MySQL主从复制配置完毕 一.Mycat实现读写分离安装和配置 架构规划: 192.168.201.150 master 主节点 192.168. ...
- spring cloud 与spring boot的版本对应总结
1.前言 一开始不理解为什么使用 spring boot 高版本 ,却没有对应的spring cloud版本 ,还以为最高版本的 spring cloud 会向上兼容 . 这个坑 ,没有人告诉我, ...
- react中使用react-transition-group(CSSTransition)
https://blog.csdn.net/sophie_u/article/details/80093876
- xray 与 awvs 爬虫联动
awvs 的爬虫很好用,支持表单分析和单页应用的爬取,xray 的扫描能力比较强,速度也更快.awvs 和 xray 搭配使用则是如虎添翼.这里演示的是扫描 awvs 的在线靶站 http://tes ...
- Android官方文档翻译 五 1.3Building a Simple User Interface
Building a Simple User Interface 创建一个简单的用户界面 This lesson teaches you to 这节课将教给你: Create a Linear Lay ...
- 在 K8S 中快速部署 Redis Cluster & Redisinsight
Redis Cluster 部署 使用 Bitnami helm chart 在 K8S redis 命名空间中一键部署 Redis cluster . helm repo add bitnami h ...
- 【Azure 应用服务】Azure Mobile App (NodeJS) 的服务端部署在App Service for Windows中出现404 Not Found -- The resource you are looking for has been removed, had its name changed, or is temporarily unavailable.
问题描述 使用NodeJS的后端应用,开发一个Mobile App的服务端,手机端通过REST API来访问获取后端数据.在本地编译好后,通过npm start启动项目,访问效果如下: 但是,当把项目 ...
- 【Vulnhub靶场】JANGOW: 1.0.1
时隔这么久,终于开始做题了 环境准备 下载靶机,导入到virtualBox里面,这应该不用教了吧 开机可以看到,他已经给出了靶机的IP地址,就不用我们自己去探测了 攻击机IP地址为:192.168.2 ...
- MySQL基本使用(开机自启动-环境变量-忘记密码-统一编码)
目录 一:mysql简介 1.什么是MySQL? 2.MySQL的本质 3.MySQL的特点与优势 二:基本操作命令 1.登录服务端 2.2.结束符c 3.查看当前所有的库名称 4.取消之前的命令 5 ...