Coursera, Machine Learning, notes
Basic theory
|
Linear regression
|
cost function:
 % correspoding code to compute gradient decent
h = X * theta;
theta = theta - alpha/m * (X' * (h - y));
 Gradient Descent vs Normal Equation
time complexity for Gradient Decent is O(kn2)
|
|
Locally weighted regression: 只考虑待预测点附件的training data
 |
|
Logistic regression
|
|
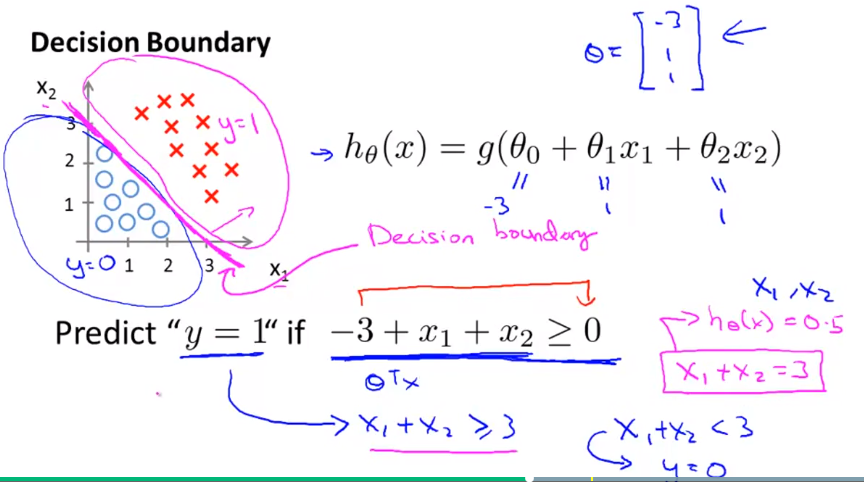
a classfication algorithm
  Cost function:
  
其中偏导数的推导如下:
  |
|
Newton's method: much faster than Gradient Decent.
 上图是求f(θ)=0时候的θ, 如果对f(θ)积分的最大值或者最小值
Newton’s method gives a way of getting to f(θ) = 0. What if we want to use it to maximize some function ℓ? The maxima of ℓ correspond to points where its first derivative ℓ ′ (θ) is zero. So, by letting f(θ) = ℓ ′ (θ), we can use the same algorithm to maximize ℓ, and we obtain update rule:
θ := θ − ℓ ′(θ) / ℓ ′′(θ)
|
|
在python里,
 |

|
Neural Network
|
|
cost function:
 |
|
back propagation algorithm:
   |
|
|
Diagnostic
|
|
Diagnostic 用来分析学习算法是不是正常工作,如果不正常工作,进一步找出原因
|
|
怎么来评估learning algorithm 是否工作呢?
可以评估hypothesis 函数, 具体可以把所以input数据分成一部分training set, 另一部分作为test set 来验证,Andrew 建议 70%/30% 这个比例来划分,然后看用training set 得到的hypothesis 在 test set 上是否工作
 |
high bias:
high variance: (high gap)
|




Q&A
- How to reduce overfitting problem?
- reduce the number of features
- regularization. Keep all the features, but reduce the magnitude of parameters θ j
- besises Gradient Decent, what other algorithms we can use ?
- besides Gradient Decent, there are some optimization algorithms like Conjugate gradient, BFGS, L-BFGS.
- These 3 optimization algorithms don't need maually pick
 , and they are often faster than Gradient Decent, but more
, and they are often faster than Gradient Decent, but more
- which has fixed set of parameters Theta, like linear regression
- in which no. of parameters grow with m.
- one specific algo is Locally weighted regression (Loess, or LWR), 这个算法不需要我们自己选feature,原理是只拟合待预测点附近的点的曲线
Coursera, Machine Learning, notes的更多相关文章
- Coursera machine learning 第二周 quiz 答案 Linear Regression with Multiple Variables
https://www.coursera.org/learn/machine-learning/exam/7pytE/linear-regression-with-multiple-variables ...
- 神经网络作业: NN LEARNING Coursera Machine Learning(Andrew Ng) WEEK 5
在WEEK 5中,作业要求完成通过神经网络(NN)实现多分类的逻辑回归(MULTI-CLASS LOGISTIC REGRESSION)的监督学习(SUOERVISED LEARNING)来识别阿拉伯 ...
- 【Coursera - machine learning】 Linear regression with one variable-quiz
Question 1 Consider the problem of predicting how well a student does in her second year of college/ ...
- Coursera, Machine Learning, Anomoly Detection & Recommender system
Algorithm: When to select Anonaly detection or Supervised learning? 总的来说guideline是如果positive e ...
- Coursera, Machine Learning, SVM
Support Vector Machine (large margin classifiers ) 1. cost function and hypothesis 下面那个紫色线就是SVM 的cos ...
- Coursera, Machine Learning, Neural Networks: Representation - week4/5
Neural Network Motivations 想要拟合一条曲线,在feature 很多的情况下,feature的组合也很多,在现实中不适用,比如在computer vision问题中featu ...
- Coursera machine learning 第二周 编程作业 Linear Regression
必做: [*] warmUpExercise.m - Simple example function in Octave/MATLAB[*] plotData.m - Function to disp ...
- Coursera machine learning 第二周 quiz 答案 Octave/Matlab Tutorial
https://www.coursera.org/learn/machine-learning/exam/dbM1J/octave-matlab-tutorial Octave Tutorial 5 ...
- Coursera Machine Learning 作业答案脚本 分享在github上
Github地址:https://github.com/edward0130/Coursera-ML
随机推荐
- Arcgis for qml - 鼠标拖拽移动
以实现鼠标拖拽文本图层为例 GitHub:ArcGIS拖拽文本 作者:狐狸家的鱼 目的是利用鼠标进行拖拽. 实现两种模式,一种是屏幕上的拖拽,第二种是地图上图层的挪动. 屏幕上的拖拽其实跟ArcGIS ...
- vue2.0获取自定义属性的值
最近在项目中使用了vue.js.在爬坑的路上遇到了很多问题.这里都会给记录下来,今天要说的是怎么获取自定义属性的值. HTML <!DOCTYPE html> <html> & ...
- Django 配置数据库
Django提到配置那大多数都是在settings.py配置文件 在配置文件里的 DATABASES 内进行设置 # 数据库配置 DATABASES = { #连接mysql 'default': { ...
- PMP认证考试的最新趋势及10大特征(针对改版后)
我们都知道,今年PMP认证考试的教材已经改版了,最新版的内容是有不少的改动的,我们在了解PMP考试的时候,也要了解PMP考试的最新趋势,以便拿出应对的方法. 一.情景题更接地气 虽然PMP考试中继续保 ...
- postman 抓包工具charles的使用
1.直接打开charles,然后,如果有https的话,需要安装证书,然后,设置代理 2.如果不是https的,不需要设置代理,直接抓取就可以 先安装证书: 然后设置代理: ...
- Luogu P3305 [SDOI2013]费用流 二分 网络流
题目链接 \(Click\) \(Here\) 非常有趣的一个题目. 关键结论:所有的单位费用应该被分配在流量最大的边上. 即:在保证最大流的前提下,使最大流量最小.这里我们采用二分的方法,每次判断让 ...
- nginx + php + mysql安装、配置、自启动+redis扩展
用过了apache就想着用用nginx,网上教程其实很多,但是受服务器版本等限制,每个人遇到的问题也不一样,先记录下我的 一.安装依赖 yum -y install gcc zlib zlib-dev ...
- sys用户的操作
oracle中查找某个表属于哪个用户? select owner from dba_tables where table_name=upper('t_l_tradelist' ) 1 ...
- 信用评分卡Credit Scorecards (1-7)
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 python风控评分卡建模和风控常识 https://study.163.com/course/introductio ...
- How-to: Do Statistical Analysis with Impala and R
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&a ...