【Spark调优】数据倾斜及排查
【数据倾斜及调优概述】
大数据分布式计算中一个常见的棘手问题——数据倾斜:
在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数据,但是个别key却对应了百万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了;但是个别task可能分配到了百万数据,要运行一两个小时。木桶原理,整个作业的运行进度是由运行时间最长的那个task决定的。
出现数据倾斜的时候,绝大多数task执行得都非常快,但个别task执行极慢。例如,总共有1000个task,997个task都在1分钟之内执行完了,但是剩余两三个task却要一两个小时。这种情况很常见。原本能够正常执行的Spark作业,某天突然报出OOM(内存溢出)异常,观察异常栈,是我们写的业务代码造成的。这种情况比较少见。
此时Spark作业的性能会比期望差很多。数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作业的性能。
【定位发生数据倾斜的代码】
1) 数据倾斜只会发生在shuffle过程中。所以关注一些常用的并且可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出现数据倾斜时,可能就是代码中使用了这些算子中的某一个所导致的。
2)通过观察spark UI的界面,定位数据倾斜发生在第几个stage中。
如果是用yarn-client模式提交,那么本地是直接可以看到log的,可以在log中找到当前运行到了第几个stage;如果是用yarn-cluster模式提交,则可以通过Spark Web UI来查看当前运行到了第几个stage。此外,无论是使用yarn-client模式还是yarn-cluster模式,我们都可以在Spark Web UI上深入看一下当前这个stage各个task分配的数据量,从而进一步确定是不是task分配的数据不均匀导致了数据倾斜。
- 1段提交代码是1个Application
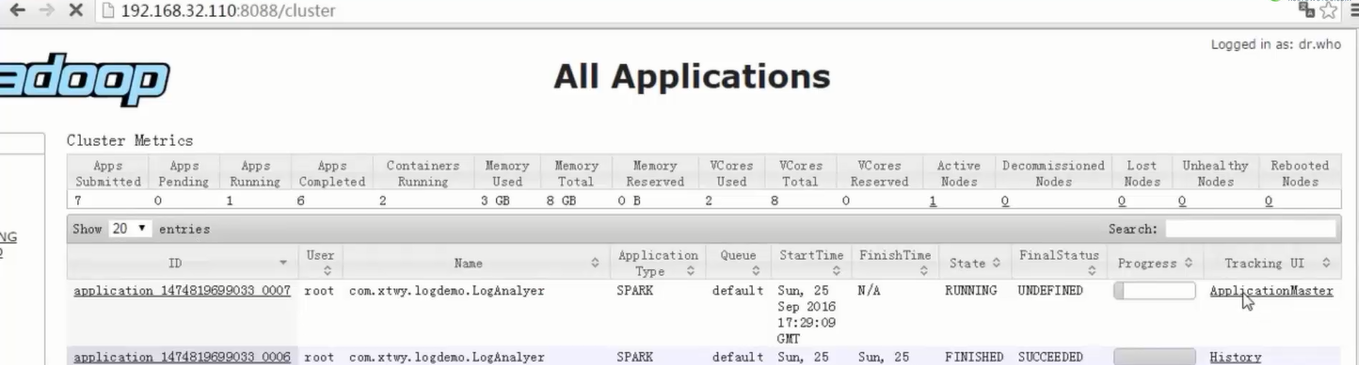
- 1个action算子是1个job
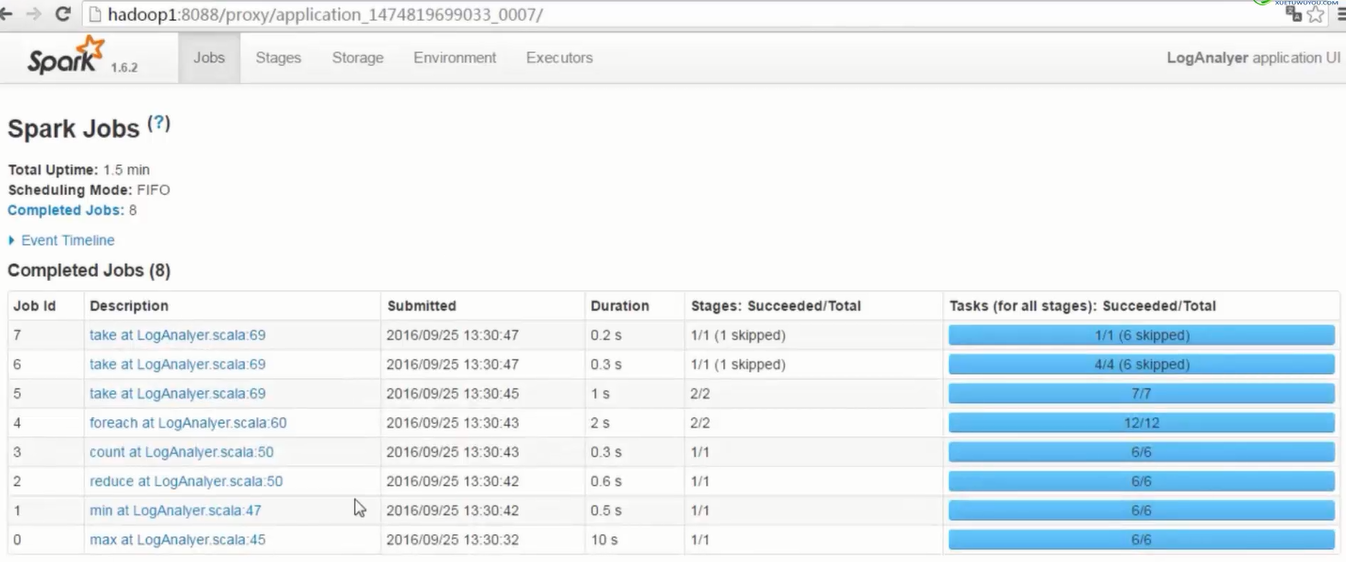
- 1个job中,以宽依赖为分割线,划分成不同stage,stage编号从0开始
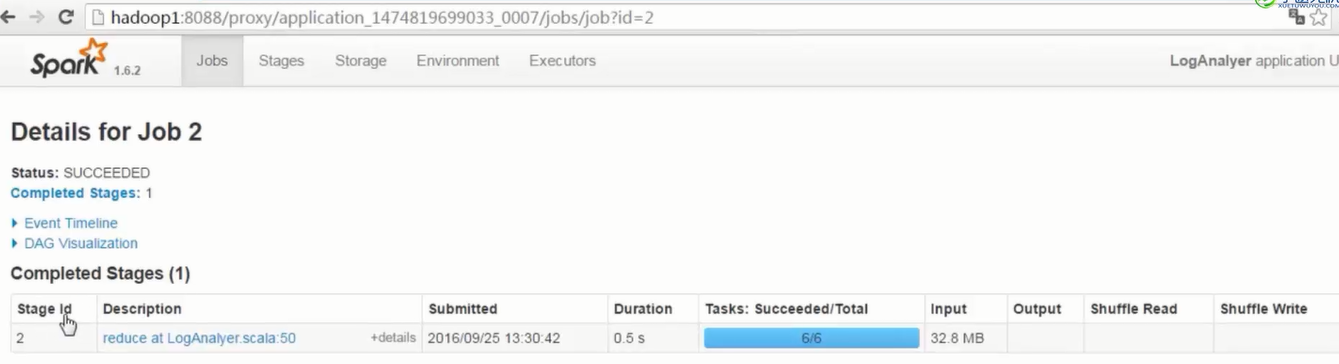
- 1个stage中,划分出参数指定数量的task,注意观察Locality Level和Duration列

- Executor数量是配置参数指定的
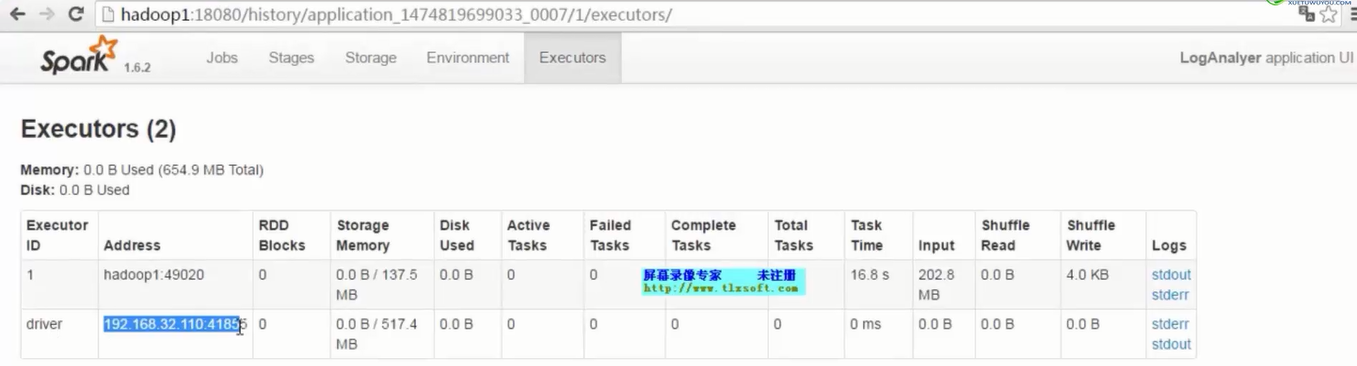
- 看结果文件---自己统计代码中println的打印
3)根据 【Spark工作原理】stage划分原理理解 中的stage的划分算法定位到极有可能发生数据倾斜的代码

【查看导致数据倾斜的key的分布情况】
1. 如果是Spark SQL中的group by、join语句导致的数据倾斜,那么就查询一下SQL中使用的表的key分布情况。
2. 如果是对Spark RDD执行shuffle算子导致的数据倾斜,那么可以在Spark作业中加入查看key分布的代码,比如RDD.countByKey()。然后对统计出来的各个key出现的次数,collect/take到客户端打印一下,就可以看到key的分布情况。
不放回sample+countByKey查看key分布,是否数据倾斜
val sampledPairs = pairs.sample(false, 0.1)
val sampledWordCounts = sampledPairs.countByKey()
sampledWordCounts.foreach(println(_))
【Spark调优】数据倾斜及排查的更多相关文章
- Spark调优 数据倾斜
1. Spark数据倾斜问题 Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题. 例如,reduce ...
- spark调优——数据倾斜
Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题. 例如,reduce点一共要处理100万条数据,第 ...
- spark性能调优 数据倾斜 内存不足 oom解决办法
[重要] Spark性能调优——扩展篇 : http://blog.csdn.net/zdy0_2004/article/details/51705043
- Greenplum 调优--数据倾斜排查(二)
上次有个朋友咨询我一个GP数据倾斜的问题,他说查看gp_toolkit.gp_skew_coefficients表时花费了20-30分钟左右才出来结果,后来指导他分析原因并给出其他方案来查看数据倾斜. ...
- Greenplum 调优--数据倾斜排查(一)
对于分布式数据库来说,QUERY的运行效率取决于最慢的那个节点. 当数据出现倾斜时,某些节点的运算量可能比其他节点大.除了带来运行慢的问题,还有其他的问题,例如导致OOM,或者DISK FULL等问题 ...
- 1-Spark-1-性能调优-数据倾斜1-特征/常见原因/后果/常见调优方案
数据倾斜特征:个别Task处理大部分数据 后果:1.OOM;2.速度变慢,甚至变得慢的不可接受 常见原因: 数据倾斜的定位: 1.WebUI(查看Task运行的数据量的大小). 2.Log,查看log ...
- 2-Spark-1-性能调优-数据倾斜2-Join/Broadcast的使用场景
技术点:RDD的join操作可能产生数据倾斜,当两个RDD不是非常大的情况下,可以通过Broadcast的方式在reduce端进行类似(Join)的操作: broadcast是进程级别的,只读的. b ...
- spark 调优概述
分为几个部分: 开发调优.资源调优.数据倾斜调优.shuffle调优 开发调优: 主要包括这几个方面 RDD lineage设计.算子的合理使用.特殊操作的优化等 避免创建重复的RDD,尽可能复用同一 ...
- 【Spark调优】大表join大表,少数key导致数据倾斜解决方案
[使用场景] 两个RDD进行join的时候,如果数据量都比较大,那么此时可以sample看下两个RDD中的key分布情况.如果出现数据倾斜,是因为其中某一个RDD中的少数几个key的数据量过大,而另一 ...
随机推荐
- 关于python27和windows系统的中文编码问题
最近想写一个python脚本实现对文件夹中的文件进行批量命名.每个文件对应从txt文档中提取出来的一行,因为文件名是中文,所以涉及到了一些中文编码的问题. 脚本运行环境是win10+python27 ...
- 探索未知种族之osg类生物---渲染遍历之裁剪三
前言 在osgUtil::CullVisitor,我们发现apply函数的重载中,有CullVisitor::apply(Group& node),CullVisitor::apply(Swi ...
- python基础 (装饰器,内置函数)
https://docs.python.org/zh-cn/3.7/library/functions.html 1.闭包回顾 在学习装饰器之前,可以先复习一下什么是闭包? 在嵌套函数内部的函数可以使 ...
- Similarity measure
1. https://blog.csdn.net/m0_37676632/article/details/68936157 2. https://www.cnblogs.com/pinard/p/62 ...
- windows下SVN服务器搭建--VisualSVN与TortoiseSVN的配置安装
在讲解之前,我们来思考两个问题: 1.什么是版本控制 2.为什么要用版本控制工具 ----------------------------------------------------- 版本控制工 ...
- douyin-bot-代码
# -*- coding: utf-8 -*- import sys import random import time from PIL import Image if sys.version_in ...
- pyadb关于python操作adb的资料
3.最后adb命令由于是android的原生操作命令,支持实现的功能非常多.这里举几个pyapp里实现的功能例子:获取,修改手机当前使用的输入法(adb shell ime list),获取当前手机界 ...
- Vue 获取登录用户名
本来是打算登录的时候把用户名传过去,试了几次都没成功,然后改成用cookie保存用户名,然后在读取就行了, 登录时候设置cookie setCookie(c_name,c_pwd,exdays) { ...
- 读《赋能》有感zz
听樊登18年春节后第一本新书<赋能>,学到了几个新的管理词语,深井病.还原论.乌卡时代: 下面谈谈自己的学习收获. 深井病就是随着组织发展的壮大,当然是传统的企业,其部门或个人都会变得越来 ...
- linux 解压 压缩 常见命令
压缩命令: .tar tar -cvf 文件名称.tar 文件或者文件夹 .tar.gz tar -zcvf 文件名称.tar.gz 文件或者文件夹 .tar.xz tar -Jcf 文件名称.tar ...