Intro to Machine Learning
本节主要用于机器学习入门,介绍两个简单的分类模型:
决策树和随机森林
不涉及内部原理,仅仅介绍基础的调用方法
1. How Models Work
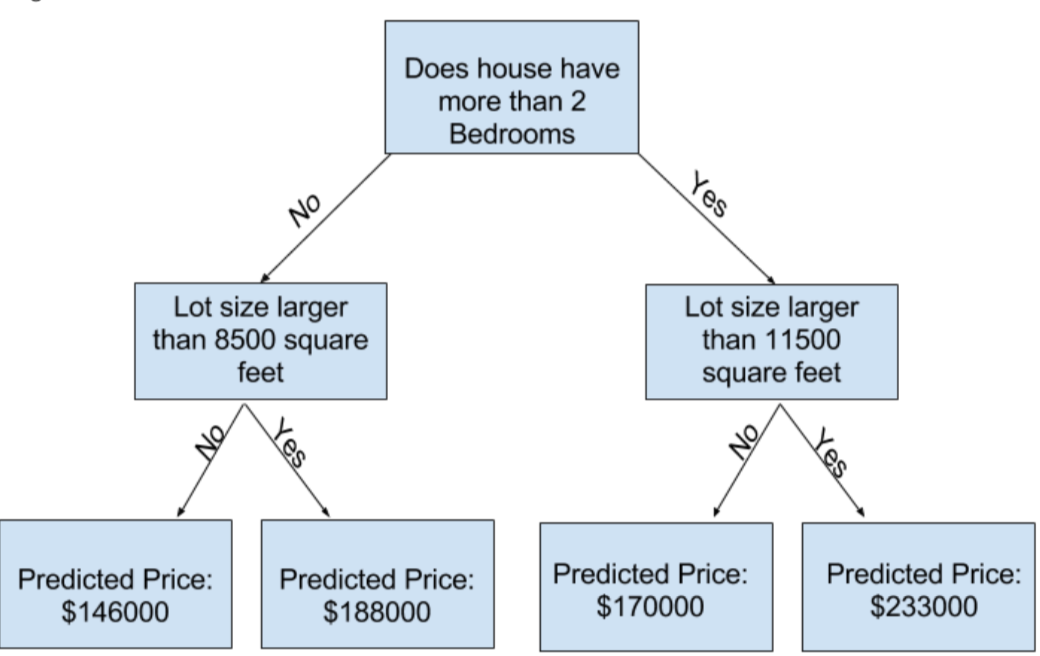
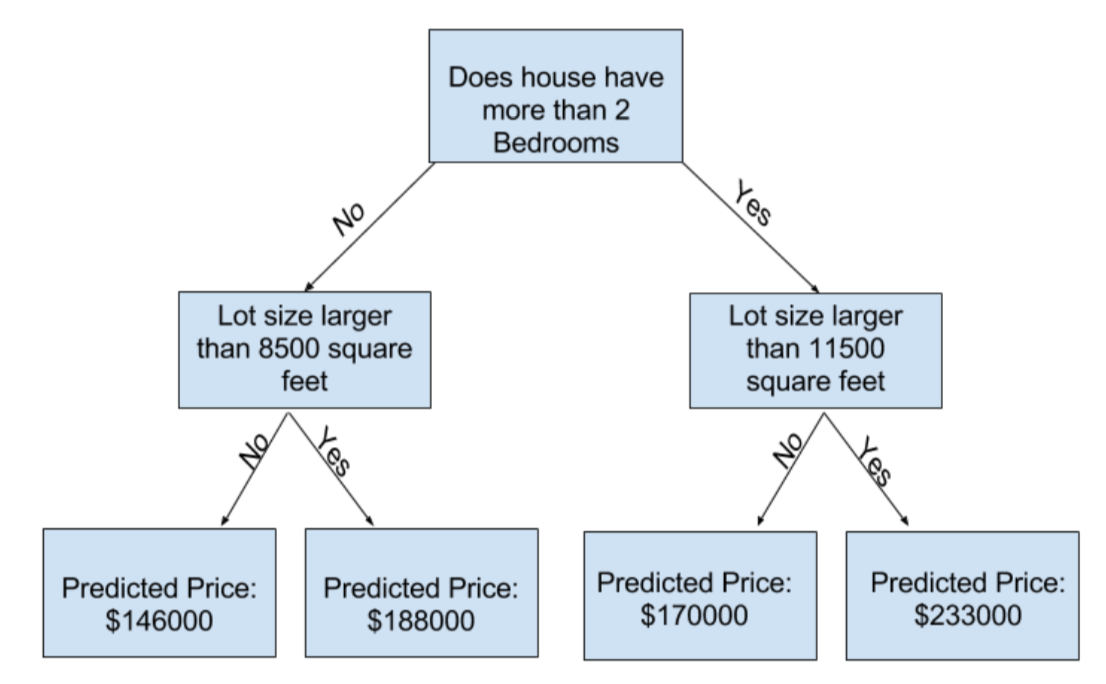
以简单的决策树为例
This step of capturing patterns from data is called fitting or training the model
The data used to train the data is called the trainning data
After the model has been fit, you can apply it to new data to predict prices of additional homes
2.Basic Data Exploration
使用pandas中的describle()来探究数据:
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
melbourne.describe()
output:
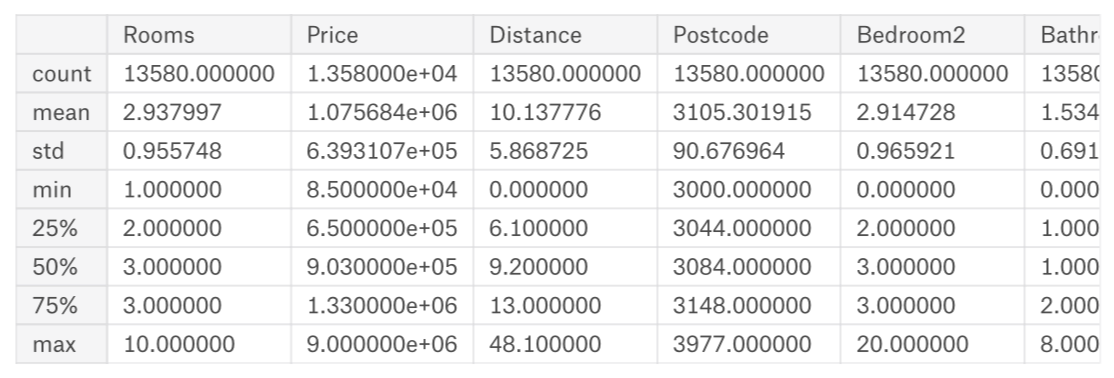
注:数值含义
count: 非缺失值的数量
mean: 平均值
std: 标准偏差,它度量值在数值上的分布情况
min、25%、50%、75%、max: 将每一列按照从lowest到highest排序,最小值是min, 1/4位置上,大于25%而小于50%是25%
3.Your First Machine Learning Model
- Selecting Data for Modeling
import pandas as pd
melbourne_file_path = ' ../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
- Selecting The Prediction Target
方法:使用dot-notation来挑选prediction target
- Choosing "Features"
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]
查看数据是否加载正确:
X.head()
探究数据基本特性:
- Building Your Model
我们使用scikit-learn来创造模型,scikit-learn教程如下:
具体的原理可以根据需要自己探究
https://scikit-learn.org/stable/supervised_learning.html#supervised-learning
构建模型步骤:
- Define:
What type of model will it be? A decision tree? Some other type of model? Some other parameters of the model type are specified too.
- Fit:
Capture patterns from provided data. This is the heart of modeling
- Predict:
Just what it sounds like
- Evaluate:
Determine how accurate the model's predictions are
实现:
from sklearn.tree import DecisionTreeRegressor
melbourne_mode = DecisionTreeRegressor(random_state=1)
melbourne_mode.fit(X , y)
打印出开始几行:
print (X.head())
预测后的价格如下:
print (melbourne_mode.predict(X.head())
4.Model Validation
由于预测的价格和真实的价格会有差距,而差距多少,我们需要衡量
使用Mean Absolute Error
error= actual-predicted
在实际过程中,我们要将数据分成两份,一份用于训练,叫做training data, 一份用于验证叫validataion data
from sklearn.model_selection import train_test_split
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=0)
melbourne_model = DecisionTreeRegressor()
melbourne_model.fit(train_X, train_y)
val_predictions = melbourne_model.predict(val_X)
print(mean_absolute_error(val_y, val_predictions))
5.Underfitting and Overfitting
- overfitting: A model matches the data almost perfectly, but does poorly in validation and other new data.
- underfitting: When a model fails to capture important distinctions and patterns in the data, so it performs poorly even in training data.
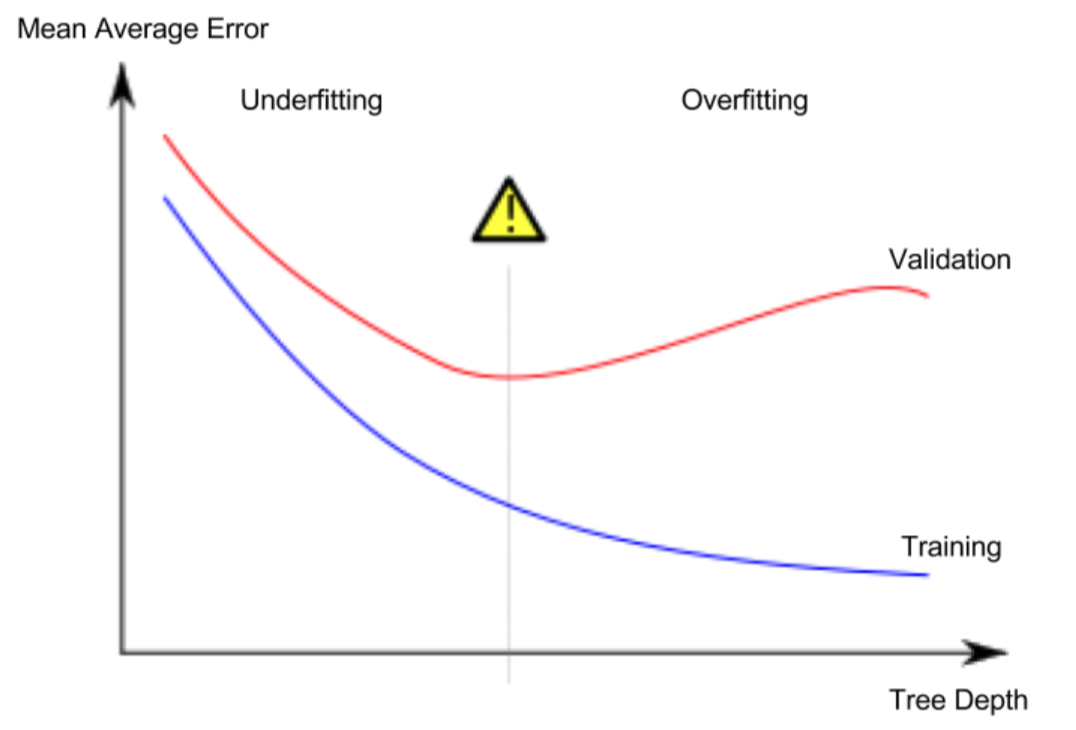
The more leaves we allow the model to make, the more we move from the underfitting area in the above graph to overfitting area.
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecsionTreeRegressor
def get_ame(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes = max_leaf_nodes, random_state = 0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)
我可以使用循环比较选择最合适的max_leaf_nodes
for max_leaf_nodes in [5,50,500,5000]:
my_ame = get_ame(max_leaf_nodes, train_X, val_X, train_y, val_y)
print(max_leaf_nodes, my_ame)

最后可以发现,当max leaf nodes 为 500时,MAE最小, 接下来我们换另外一种模型
6.Random Forests
The random forest uses many trees, and it makes a prediction by averaging the predictions of each component tree. It generally has much better predictive accuracy than a single decision tree and it works well with default parameters.
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
forest_model = RandomForestRegressor(random_state=1)
forest_model.fit(train_X,train_y)
melb_preds = forest_model.predict(val_X)
print(mean_absolute_error(val_y, melb_preds))
可以发现最后的误差,相对于决策树小。
one of the best features of Random Forest models is that they generally work reasonably even without this tuning.

7.Machine Learning Competitions
- Build a Random Forest model with all of your data
- Read in the "test" data, which doesn't include values for the target. Predict home values in the test data with your Random Forest model.
- Submit those predictions to the competition and see your score.
- Optionally, come back to see if you can improve your model by adding features or changing your model. Then you can resubmit to see how that stacks up on the competition leaderboard.
Intro to Machine Learning的更多相关文章
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
- 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- Easy machine learning pipelines with pipelearner: intro and call for contributors
@drsimonj here to introduce pipelearner – a package I'm developing to make it easy to create machine ...
- How do I learn mathematics for machine learning?
https://www.quora.com/How-do-I-learn-mathematics-for-machine-learning How do I learn mathematics f ...
- 机器学习案例学习【每周一例】之 Titanic: Machine Learning from Disaster
下面一文章就总结几点关键: 1.要学会观察,尤其是输入数据的特征提取时,看各输入数据和输出的关系,用绘图看! 2.训练后,看测试数据和训练数据误差,确定是否过拟合还是欠拟合: 3.欠拟合的话,说明模 ...
- 【Machine Learning】KNN算法虹膜图片识别
K-近邻算法虹膜图片识别实战 作者:白宁超 2017年1月3日18:26:33 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 【Machine Learning】Python开发工具:Anaconda+Sublime
Python开发工具:Anaconda+Sublime 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现 ...
随机推荐
- 万万没想到,JVM内存结构的面试题可以问的这么难?
在我的博客中,之前有很多文章介绍过JVM内存结构,相信很多看多我文章的朋友对这部分知识都有一定的了解了. 那么,请大家尝试着回答一下以下问题: 1.JVM管理的内存结构是怎样的? 2.不同的虚拟机在实 ...
- centos yum 安装 mariadb
1. 在 /etc/yum.repos.d/ 下建立 MariaDB.repo,输入内容 [mariadb] name=MariaDB baseurl=http://yum.mariadb.org/1 ...
- weblogic10.3.6漏洞修改方案
1.CVE-2018-2628漏洞 CVE-2018-2628漏洞利用的第一步是与weblogic服务器开放在服务端口上的T3服务建立socket连接,可通过控制T3协议的访问来临时阻断攻击行为. W ...
- Mybatis学习笔记之---环境搭建与入门
Mybatis环境搭建与入门 (一)环境搭建 (1)第一步:创建maven工程并导入jar包 <dependencies> <dependency> <groupId&g ...
- [原创实践]RedHat Enterprise Linux 5 安装GCC和redis
Redis的安装需要使用GCC,Red Hat Enterprise 5默认是不安装gcc的,需要自己手动安装. 1:查看系统中是否有gcc gcc -v 查看本机linux版本 lsb_releas ...
- 【POJ - 3280】Cheapest Palindrome(区间dp)
Cheapest Palindrome 直接翻译了 Descriptions 给定一个字符串S,字符串S的长度为M(M≤2000),字符串S所含有的字符的种类的数量为N(N≤26),然后给定这N种字符 ...
- 体验使用MUI上手练习app页面开发
因为公司安排需要先学习一点app开发,而安排学习的框架就是MUI,上手两天体验还算可以(来自后端人员的懵逼),靠着MUI的快捷键可以快速的完成自己想要的样式模板,更多的交互性的内容则需要使用js来完成 ...
- JMeter定制Sampler
1.背景 相信大家在使用JMeter工具测试的时候,经常会遇到自带采样器无法满足测试要求的情况.面对这种情况,通常的办法是使用万能的自定义Java Request的达到测试目的.这个方法有个弊端,只要 ...
- WIN10家庭版桌面右键单击显示设置出现ms-settings:display或ms-settings:personalization-background解决办法[原创]
最近,笔者的笔记本卸载oracle数据库,注册表里面删除了不少相关信息,没想到担心的事情还是来了!桌面右键单击显示设置出现ms-settings:display或ms-settings:persona ...
- poj3415_Common Substrings
题意 给定两个字符串,求长度大于等于k的公共子串数. 分析 将两个字符串中间加个特殊字符拼接,跑后缀数组. 将题目转化为对每一个后缀求\(\sum_{j=1}^{i-1}lcp(i,j)\),且后缀\ ...