Python爬虫教程-实现百度翻译
使用python爬虫实现百度翻译功能
python爬虫实现百度翻译: python解释器【模拟浏览器】,发送【post请求】,传入待【翻译的内容】作为参数,获取【百度翻译的结果】
通过开发者工具,获取发送请求的地址
提示: 翻译内容发送的请求地址,绝对不是打开百度翻译的那个地址,想要抓取地址,就要借助【浏览器的开发者工具】,或者其他抓包工具
下面介绍获取请求地址的具体方法
以Chrome为例
打开百度翻译:http://fanyi.baidu.com/
【点击右键】>【检查】>【network】(如果是火狐浏览器,点击【网络】)
点击【XHR】项,(有些需要刷新,有些异步的请求不需要刷新)
在页面【输入翻译的词汇】
在XHR项下,查找包含【输入需要翻译的词汇】的请求
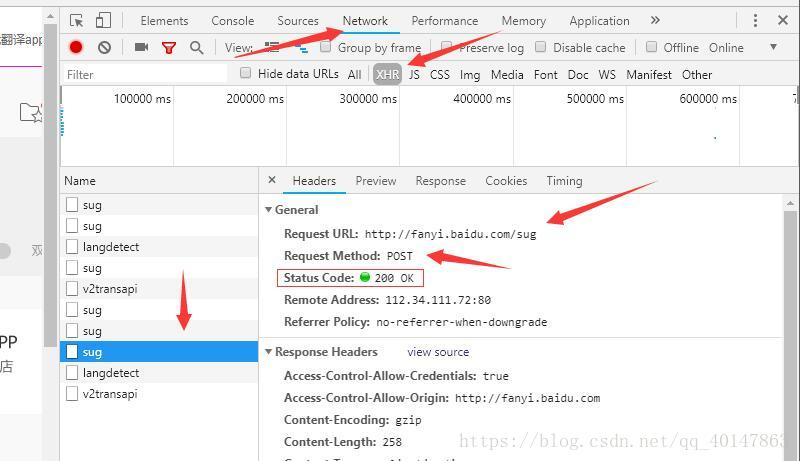
查看请求的参数,需要【点击请求】>【Headers】>最下面的【Form Data】
(这里有一个坑:我们会发现有多个sug项,其实是因为百度翻译只要每输入一个字母就会发送一次请求,所以虽然多个请求的地址都是一样的,但是只有最后一个sug项的参数才是最后的词汇)
操作截图 :
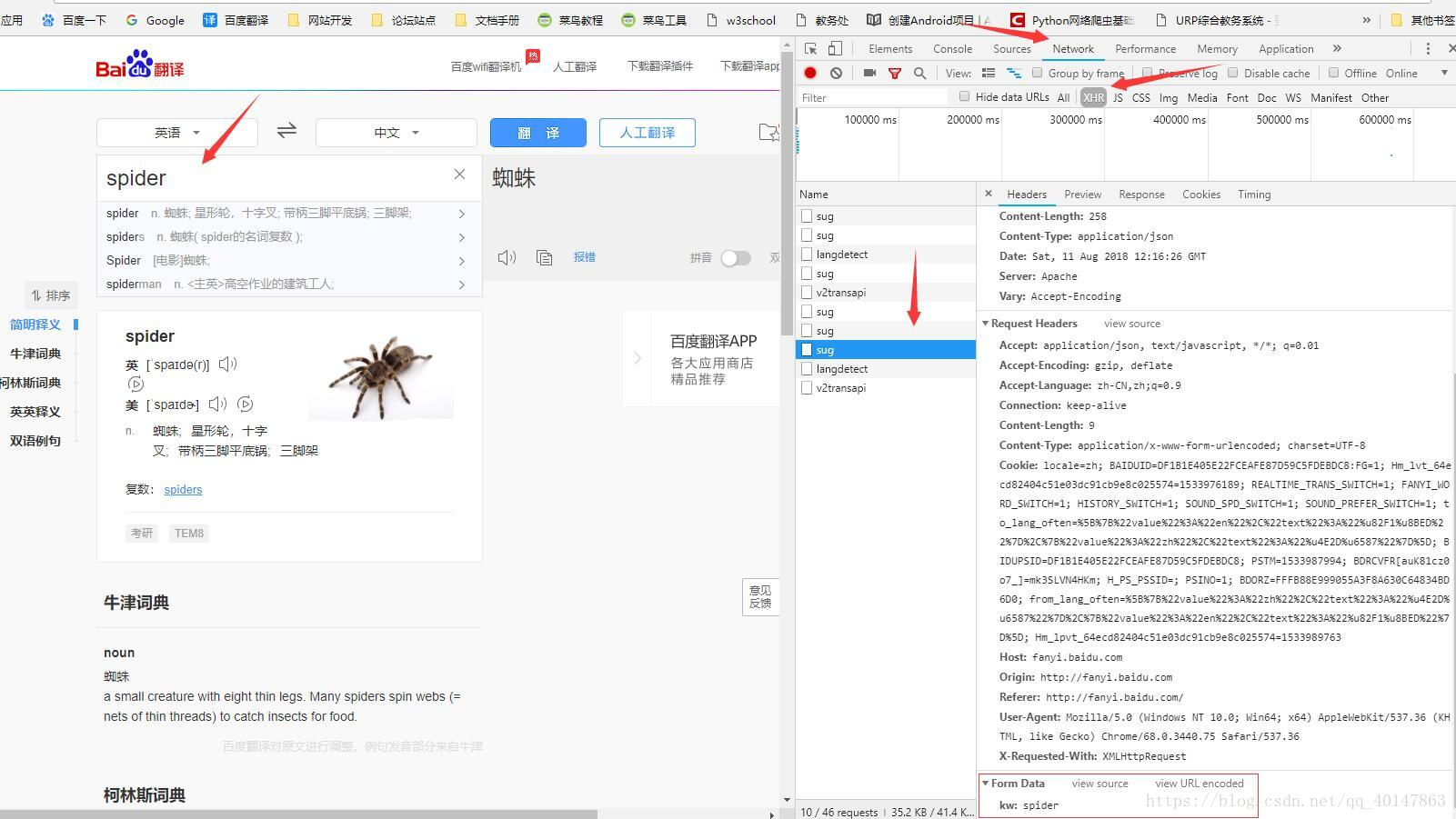
请求地址在这里
献上实现的代码
直接上代码,具体步骤下载注释上了
不会配置环境,安装python的包,请参考下一篇:
https://i-beta.cnblogs.com/posts/edit-done;postId=11945465
py05bdfanyi.py文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py05bdfanyi.py
# python爬虫实现百度翻译
# urllib和request POST参数提交
# 缺少包请自行查看之前的笔记 from urllib import request,parse
import json def fanyi(keyword):
base_url = 'http://fanyi.baidu.com/sug' # 构建请求对象
data = {
'kw': keyword
}
data = parse.urlencode(data) # 模拟浏览器
header = {"User-Agent": "mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"} req = request.Request(url=base_url,data=bytes(data,encoding='utf-8'),headers=header)
res = request.urlopen(req) # 获取响应的json字符串
str_json = res.read().decode('utf-8')
# 把json转换成字典
myjson = json.loads(str_json)
info = myjson['data'][0]['v']
print(info) if __name__=='__main__':
while True:
keyword = input('请输入翻译的单词:')
if keyword == 'q':
break
fanyi(keyword)
代码运行

如果还有问题未能得到解决,搜索887934385交流群,进入后下载资料工具安装包等。最后,感谢观看!
Python爬虫教程-实现百度翻译的更多相关文章
- Python爬虫爬取百度翻译之数据提取方法json
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统 说明:本例为实现输入中文翻译为英文的小程序,适合Python爬虫的初学者一起学习,感兴趣的可以做英文翻译为中文的 ...
- python --爬虫--爬取百度翻译
import requestsimport json class baidufanyi: def __init__(self, trans_str): self.lang_detect_url = ' ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
- Python爬虫教程-07-post介绍(百度翻译)(上)
Python爬虫教程-07-post介绍(百度翻译)(上) 访问网络两种方法 get: 利用参数给服务器传递信息 参数为dict,使用parse编码 post :(今天给大家介绍的post) 一般向服 ...
- Python爬虫教程-06-爬虫实现百度翻译(requests)
使用python爬虫实现百度翻译(requests) python爬虫 上一篇介绍了怎么使用浏览器的[开发者工具]获取请求的[地址.状态.参数]以及使用python爬虫实现百度翻译功能[urllib] ...
- Python爬虫教程-16-破解js加密实例(有道在线翻译)
python爬虫教程-16-破解js加密实例(有道在线翻译) 在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如: 加cookie,身份验证UserAgent 图形验证,还有很难破解的滑动验证 js签 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- 简单的python爬虫教程:批量爬取图片
python编程语言,可以说是新型语言,也是这两年来发展比较快的一种语言,而且不管是少儿还是成年人都可以学习这个新型编程语言,今天南京小码王python培训机构变为大家分享了一个python爬虫教程. ...
随机推荐
- MySQL日志简介
一.MySQL日志简介 二.错误日志 作用: 记录mysql数据库的一般状态信息及报错信息,是我们对于数据库常规报错处理的常用日志. 默认位置: $MYSQL_HOME/data/ 开启方式:(MyS ...
- find 常用命令
系统中总会不断产生一些文件,比如日志文件,不一定会用到也不会自动删除,这时候就需要手动删除,当然也可以转存到其他目录下.不好找的时候可以用find模糊查找,加个job定时任务自动执行定期删除文件1.添 ...
- celery执行异步任务和定时任务
一.什么是Clelery Celery是一个简单.灵活且可靠的,处理大量消息的分布式系统 专注于实时处理的异步任务队列 同时也支持任务调度 Celery架构 Celery的架构由三部分组成,消息中间件 ...
- Linux防火墙常用命令
Centos7 查看防火墙状态 sudo firewall-cmd --state 输出running则表示防火墙开启,反之则是关闭,也可以使用下面命令进行查询 sudo systemctl stat ...
- Dashboard安装与配置
本节介绍如何在控制器节点上安装和配置仪表板. 仪表板所需的唯一核心服务是身份服务. 您可以将仪表板与其他服务结合使用,例如图像服务,计算和联网. 您也可以在具有独立服务(例如对象存储)的环境中使用仪表 ...
- DynamicList
DynamicList设计要点——类模板 申请连续空间作为顺序存储空间 动态设置顺序存储空间的大小 保证重置顺序存储空间时的异常安全性 DynamicList设计要点——函数异常安全的概念 不泄露任何 ...
- Python Django 支付宝 扫码支付
安装python-alipay-sdk pip install python-alipay-sdk --upgradepip install crypto 如果是python 2.7安装0.6.4这个 ...
- java之四种权限修饰符
java权限修饰符piublic.protected.private.置于类的成员定义前,用来限定对象对该类成员的访问权限. 修饰符 类内部 同一个包 子类 任何地方 private yes ...
- MySql索引背后的数据结构及算法
本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree ...
- Java描述设计模式(09):装饰模式
本文源码:GitHub·点这里 || GitEE·点这里 一.生活场景 1.场景描述 孙悟空有七十二般变化,他的每一种变化都给他带来一种附加的本领.他变成鱼儿时,就可以到水里游泳:他变成鸟儿时,就可以 ...