Kafka(一) —— 基本概念及使用
一、安装&启动
安装Kafka(使用内置Zookeeper)
在Kafka官网下载安装包kafka_2.11-1.0.0.tgz
### 解压
tar zxvf kafka_2.11-1.0.0.tgz
#### 启动内置的zookeeper
.bin/zookeeper-server-start.sh ../config/zookeeper.properties
#### 启动kafka
./bin/kafka-server-start.sh ../config/server.properties
#### 启动kafka,在后台运行
./bin/kafka-server-start.sh -daemon ../config/server.properties
不使用内置的Zookeeper
Zk官方文档
https://zookeeper.apache.org/doc/current/index.html
二、终端命令
创建主题
./kafka-topics.sh --create --zookeeper localhost:2181 --topic test --partitions 1 --replication-factor 1
查看主题
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
生产消息
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
消费消息
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
三、生产
引入依赖
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.0.0</version>
</dependency>
生产消息
public class KafkaProducerDemo {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
// ack = 0 producer不理睬broker的处理结果
// ack = all or -1 broker将消息写入本地日志,且ISR中副本也全部同步完,返回响应结果
// ack = 1 默认参数值,broker写入本地日志,无需等待ISR
props.put("acks", "-1");
props.put("retries", 3);
//单位byte,当batch满了,producer会发送batch中的消息,还要参考linger.ms参数
props.put("batch.size", 16384);
//控制消息发送的延时行为,让batch即使没满,也可以发送batch中的消息
props.put("linger.ms", 10);
//producer端缓存消息缓冲区的大小
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("max.blocks.ms", "3000");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 100; i++) {
try {
producer.send(new ProducerRecord<String, String>("testfzj", Integer.toString(i), Integer.toString(i))).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
producer.close();
System.out.println("发送完成");
}
}
使用自定义拦截器
(1)发送的value前统一加一个时间戳
/**
* 增加时间戳 拦截器
* @author Michael Fang
* @since 2019-11-12
*/
public class TimeStampPrependerInterceptor implements ProducerInterceptor<String, String> {
/**
* 会创建一个新的Record
*
* @param producerRecord
* @return
*/
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> producerRecord) {
return new ProducerRecord<String, String>(
producerRecord.topic(),
producerRecord.partition(),
producerRecord.timestamp(), producerRecord.key(),
System.currentTimeMillis() + "," + producerRecord.value().toString());
}
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
(2)发送完成后进行成功统计
/**
* 发送后成功统计 拦截器
* @author Michael Fang
* @since 2019-11-12
*/
public class CounterInterceptor implements ProducerInterceptor {
private int errorCounter = 0;
private int successCounter = 0;
@Override
public ProducerRecord onSend(ProducerRecord producerRecord) {
return producerRecord;
}
/**
* 这两个参数不可能同时为空
* e = null 说明发送成功
* recordMetadata = null 说明发送失败
*
* @param recordMetadata
* @param e
*/
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
successCounter++;
} else {
errorCounter++;
}
}
@Override
public void close() {
//打印结果
System.out.println("Success sent: " + successCounter);
System.out.println("Failed sent: " + errorCounter);
}
@Override
public void configure(Map<String, ?> map) {
}
}
(3)Producer代码中增加属性配置,使其拦截器生效
Properties props = new Properties();
List<String> interceptors = new ArrayList<>();
interceptors.add("com.fonxian.kafka.TimeStampPrependerInterceptor");
interceptors.add("com.fonxian.kafka.CounterInterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
效果
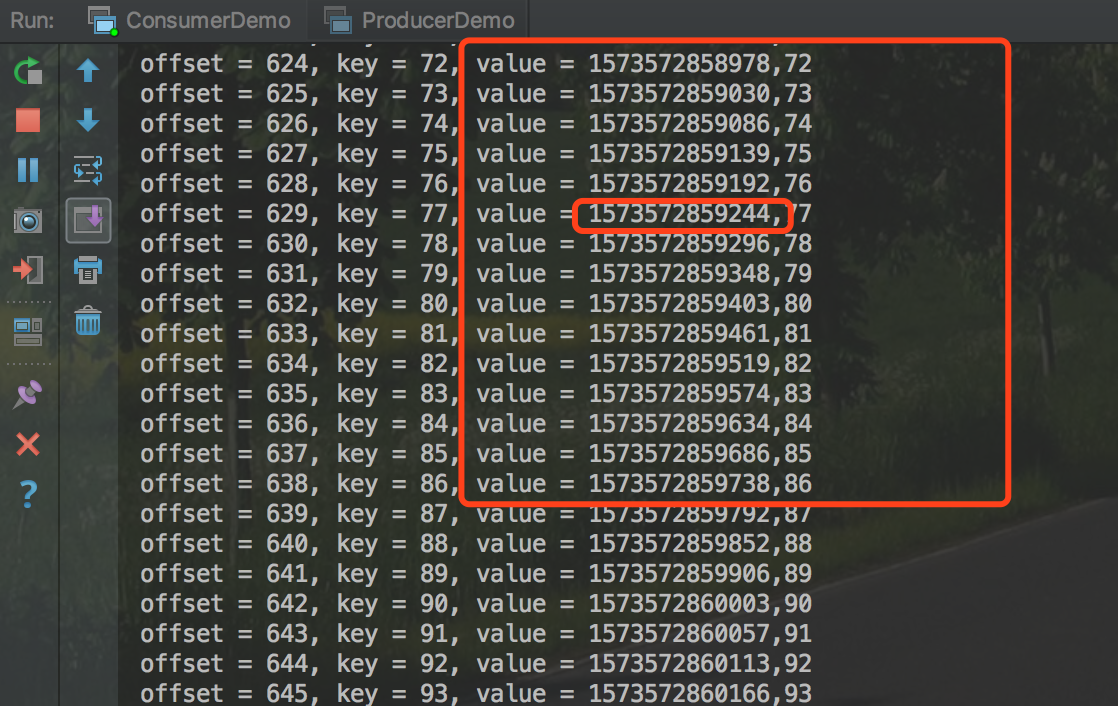
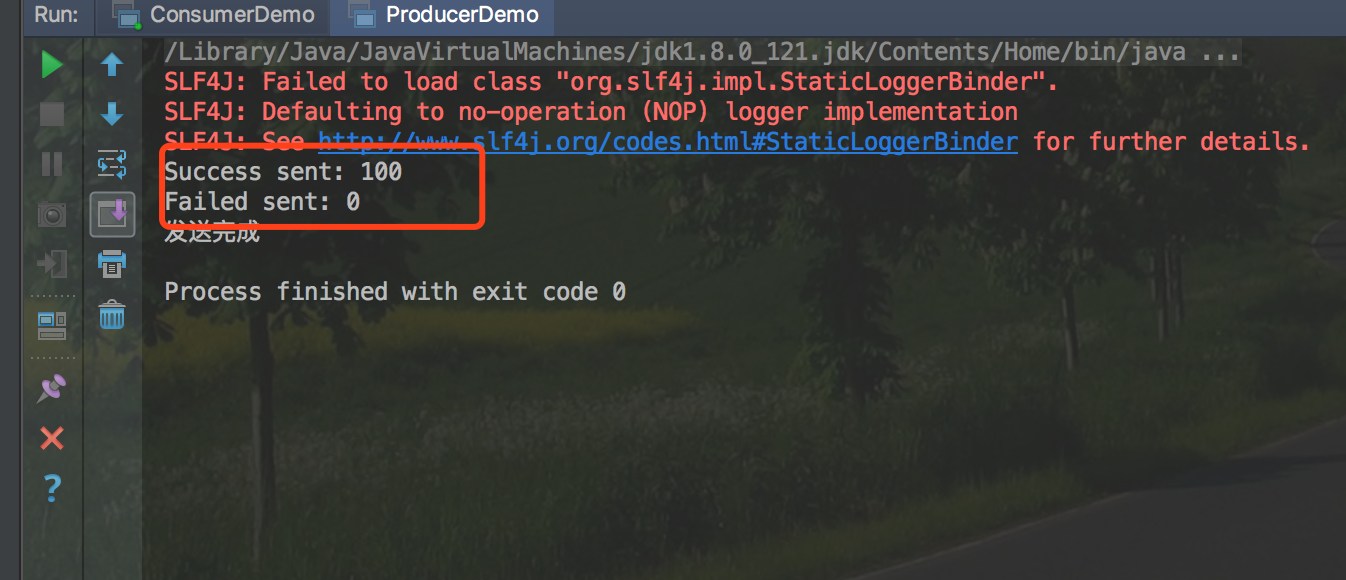
使用自定义分区器
创建一个4个分区的主题
./kafka-topics.sh --create --zookeeper localhost:2181 --topic test-partition-1 --partitions 4 --replication-factor 1
产生的消息的key为(0-99),消息的key能被10整除的全部放到最后一个分区
/**
* 自定义分区器
*
* @author Michael Fang
* @since 2019-11-13
*/
public class GetServenPartitioner implements Partitioner {
private Random random;
@Override
public int partition(String topic, Object keyObj, byte[] keyBytes, Object valueObj, byte[] valueBytes1, Cluster cluster) {
String key = (String) keyObj;
//获取分区数
List<PartitionInfo> partitionInfoList = cluster.availablePartitionsForTopic(topic);
int partitionCount = partitionInfoList.size();
//最后一个分区的分区号
int lastPartition = partitionCount - 1;
//将能被10整除的key-value,发送到最后一个分区
if(Integer.valueOf(key) % 10 == 0){
return lastPartition;
}else{
return random.nextInt(lastPartition);
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
random = new Random();
}
}
结果
在broker上执行命令
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic test-partition-1
得到结果

四、消费
消费消息
public class KafkaConsumerDemo {
public static void main(String[] args) {
String topicName = "testfzj";
String gorupId = "test-group";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", gorupId);
//是否自动提交
props.put("enable.auto.commit", "true");
// 自动提交的间隔
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topicName));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}
指定分区消费消息
// 见上面分区器的部分,定义4个分区的topic
// 使用分区器将能被10整除的key,放到最后一个分区
String topicName = "test-partition-1";
Properties props = new Properties();
//配置成从头开始消费
//earliest 从最早的位移开始消费
//latest 从最新处位移开始消费
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
//是否自动提交位移
//默认是true,自动提交
//设置成false,适合有“精确处理一次”语义的需求,用户自行处理位移。
props.put("enable.auto.commit", "true");
//获取最后一个分区
List<PartitionInfo> partitionInfoList = consumer.partitionsFor(topicName);
//指定最后一个分区
consumer.assign(Arrays.asList(new TopicPartition(topicName, partitionInfoList.size() - 1)));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("topic = %s, partition = %d, offset = %d, key = %s, value = %s%n",record.topic(),record.partition(), record.offset(), record.key(), record.value());
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
运行结果
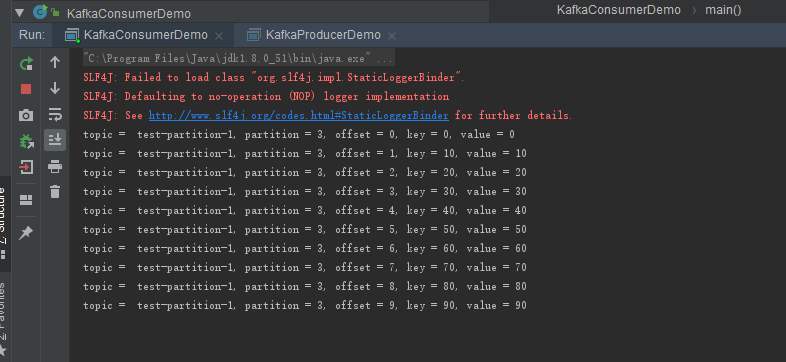
__consumer_offsets


Rebalance
rebalance规定一个consumer group如何分配订阅topic所有分区,分配的这个过程就叫rebalance。
(1)谁来执行rebalance
组协调者coordinator执行rebalance操作,负责促成组内所有成员达成新的分区分配方案。
(2)何时触发
- 当组成员发生变化,新的consumer加入或consumer退出
- 订阅的topic数发生变更,例如使用正则匹配topic,突然加入新的topic
- 订阅的topic分区数发生变更
(3)分配策略
以8个partition(p1-p8),4个consumer(c1 - c4)举例。
- range策略
- 将分区划分成固定大小的分区段,依次分配给每个分区。例如将p1、p2分配给c1。
- round-robin策略
- 将分区按顺序排开,依次分配给各个consumer。例如将p1、p5分配给c1。
- sticky策略
(4)rebalance generation
为了隔离每次rebalance的数据,防止无效的offset提交。引入rebalance generation(届)的概念。
每次rebalance完成后,consumer都会升一届。当新的届的consumer产生,则consumer group不会接受旧的届提交的offset。
例如上一届的consumer因为网络延时等原因延时提交了offset,新的一届consumer已经产生,这时,上一届consume提交的offset,将会被consumer group拒绝,会出现ILLEGAL_GENERATION异常。
(5)调优案例:频繁rebalance
线上频繁进行rebalance,会降低consumer端的吞吐量。
原因是,consumer的处理逻辑过重,导致处理时间波动大,coordinator会经常认为某个consumer挂掉,进行rebalance操作。同时consumer又会重新申请加入group,又会引发rebalance操作。
调整request.timeout.ms、max.poll.records、max.poll.interval.ms来避免不必要的rebalance。
五、SpringBoot整合kafka
文档:https://docs.spring.io/spring-kafka/docs/2.3.3.RELEASE/reference/html/
引入依赖、配置
依赖
<!-- Inherit defaults from Spring Boot -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
</parent>
<dependencies>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.59</version>
</dependency>
<!-- Add typical dependencies for a web application -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.3.3.RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
配置
application.properties
server.port=9001
spring.application.name=kafka-demo
#============== kafka ===================
# 指定kafka 代理地址,可以多个
spring.kafka.bootstrap-servers=127.0.0.1:9092
#=============== provider =======================
spring.kafka.producer.retries=0
# 每次批量发送消息的数量
spring.kafka.producer.batch-size=16384
spring.kafka.producer.buffer-memory=33554432
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#=============== consumer =======================
# 指定默认消费者group id
spring.kafka.consumer.group-id=user-log-group
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-commit-interval=100
# 指定消息key和消息体的编解码方式
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
生产者
@SpringBootApplication
public class Application {
@Autowired
private KafkaTemplate kafkaTemplate;
private static final String TOPIC = "test-partition-1";
@PostConstruct
public void init() {
for (int i = 0; i < 10; i++) {
kafkaTemplate.send(TOPIC, "key:" + i, "value:" + i);
}
}
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
消费者
@Component
public class Consume {
@KafkaListener(topics = "test-partition-1")
public void consumer(ConsumerRecord consumerRecord){
Optional<Object> kafkaMassage = Optional.ofNullable(consumerRecord);
if(kafkaMassage.isPresent()){
ConsumerRecord record = (ConsumerRecord)kafkaMassage.get();
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
结果

六、常见问题
org.apache.kafka.common.errors.TimeoutException
使用Java客户端生产消息,出现此异常提示。
原因:外网访问,需要修改server.properties参数,将IP地址改为公网的IP地址,然后重启服务
advertised.listeners=PLAINTEXT://59.11.11.11:9092
可参考 https://www.cnblogs.com/snifferhu/p/5102629.html
参考文档
《Apache Kafka实战》
《深入理解Kafka:核心设计与实践原理》
springboot集成Kafka
Spring for Apache Kafka
Kafka(一) —— 基本概念及使用的更多相关文章
- 顶级Apache Kafka术语和概念
1.卡夫卡术语 基本上,Kafka架构 包含很少的关键术语,如主题,制作人,消费者, 经纪人等等.要详细了解Apache Kafka,我们必须首先理解这些关键术语.因此,在本文“Kafka术语”中, ...
- 【kafka学习笔记】kafka的基本概念
在了解了背景知识后,我们来整体看一下kafka的基本概念,这里不做深入讲解,只是初步了解一下. kafka的消息架构 注意这里不是设计的架构,只是为了方便理解,脑补的三层架构.从代码的实现来看,kaf ...
- Kafka 温故(二):Kafka的基本概念和结构
一.Kafka中的核心概念 Producer: 特指消息的生产者Consumer :特指消息的消费者Consumer Group :消费者组,可以并行消费Topic中partition的消息Broke ...
- kafka系列 -- 基础概念
kafka是一个分布式的.分区化.可复制提交的发布订阅消息系统 传统的消息传递方法包括两种: 排队:在队列中,一组用户可以从服务器中读取消息,每条消息都发送给其中一个人. 发布-订阅:在这个模型中,消 ...
- Kafka学习之(一)了解一下Kafka及关键概念和处理机制
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模小打的网站中所有动作流数据.优势 高吞吐量:非常普通的硬件Kafka也可以支持每秒100W的消息,即使在非常廉价的商用机器上也能做 ...
- Kafka的基本概念
Kafka的前身是由LinkedIn开源的一款产品,2011年初开始开源,加入了 Apache 基金会,2012年从 Apache Incubator 毕业变成了 Apache 顶级开源项目. Top ...
- Kafka的基本概念与安装指南(单机+集群同步)
最近在搞spark streaming,很自然的前端对接的就是kafka.不过在kafka的使用中还是遇到一些问题,比如mirrormaker莫名其妙的丢失数据[原因稍后再说],消费数据offset错 ...
- kafka学习笔记——基本概念与安装
Kafka是一个开源的,轻量级的.分布式的.具有复制备份.基于zooKeeper协调管理的分布式消息系统. 它具备以下三个特性: 能够发布订阅流数据: 存储流数据时,提供相应的容错机制 当流数据到达时 ...
- Kafka 文档引言
原文地址:https://kafka.apache.org/documentation.html#semantics 1.开始 1.1 引言 Kafka是一个分布式,分区队列,冗余备份的消息存储服务. ...
- 大数据组件原理总结-Hadoop、Hbase、Kafka、Zookeeper、Spark
Hadoop原理 分为HDFS与Yarn两个部分.HDFS有Namenode和Datanode两个部分.每个节点占用一个电脑.Datanode定时向Namenode发送心跳包,心跳包中包含Datano ...
随机推荐
- GitHub上传文件夹
1.输入自己的用户名和邮箱 为注册GitHub账号时所用的用户名和邮箱;我的用户名为“1997ST2016”,邮箱为“1324971964@qq.com ”. $ git config --globa ...
- Kconfig和Makefile
内核源码树的目录下都有Kconfig和Makefile.在内核配置make menuconfig时,从Kconfig中读出菜单,用户勾选后保存到.config中.在内核编译时,Makefile调用这个 ...
- Core Animation笔记(- Layer 基本属性)
一.Layer的基本属性 1. contents 图层内容默认为nil 可以指定一张图片作为内容展示 self.layerView.layer.contents = (__bridge id)imag ...
- java设计模式--观察者模式和事件监听器模式
观察者模式 观察者模式又称为订阅—发布模式,在此模式中,一个目标对象管理所有相依于它的观察者对象,并且在它本身的状态改变时主动发出通知.这通常透过呼叫各观察者所提供的方法来实现.此种模式通常被用来事件 ...
- Navicat Premium12激活教程
如果本文对你有用,请爱心点个赞,提高排名,帮助更多的人.谢谢大家!❤ 如果解决不了,可以在文末进群交流. 先到官网下载Navicat,然后安装(怎么安装就不阐述了). 然后,到Github上下载作者发 ...
- Kali下进行局域网断网攻击
今天我就来演示一下在kali下的局域网断网攻击,即ARP地址欺骗,下图所要用到的arp地址欺骗状态图: 则: 第一步:假设主机A访问某网站,那么要告知某网站我的IP和MAC地址,但这是以广播的方式告知 ...
- abp学习(二)
翻译下首页截图的标签: DDD Base Classes 介绍: 应用程序代码库的分层是一种被广泛接受的技术,可帮助降低复杂性并提高代码重用性.为了实现分层架构,ASP.NET样板遵循域驱动设计的原则 ...
- vue 中数据共享的方式
1.父子组件的数据传递2.store模式 - 局部的数据共享3.vuex 中共享 state - 全局的数据共享
- test20190805 夏令营NOIP训练20
100+0+0=100,由于第二题写挂rank 1就没了 山 xyz现在站在一个斜坡面前 这个斜坡上依次排布这n座山峰,xyz打算爬上其中的一座 因为xyz体力不好,所以他只能爬上最矮的一座山 又因为 ...
- (java)Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息
Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息 此例将页面图片和url全部输出,重点不太明确,可根据自己的需要输出和截取: import org.jsoup.Jsou ...