深度学习面试题07:sigmod交叉熵、softmax交叉熵
目录
sigmod交叉熵
Softmax转换
Softmax交叉熵
参考资料
|
sigmod交叉熵 |
Sigmod交叉熵实际就是我们所说的对数损失,它是针对二分类任务的损失函数,在神经网络中,一般输出层只有一个结点。
假设y为样本标签,_y为全连接网络的输出层的值,那么,这个对数损失定义为
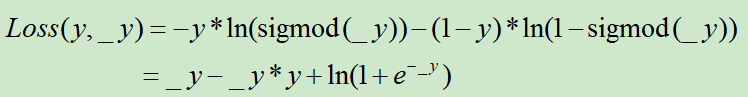
PS:这个是可以用极大似然估计推导出来的
举例:
y=0,_y=0.8,那此时的sigmod交叉熵为1.171

import numpy as np
def sigmod(x):
return 1/(1+np.exp(-x))
y=0
_y=0.8
-y*np.log(sigmod(_y))-(1-y)*np.log(1-sigmod(_y))
#_y-_y*y+np.log(1+np.exp(-_y))
|
Softmax转换 |
假设向量x=(x1,x2,...,xm),对x进行softmax转换的处理方式为:
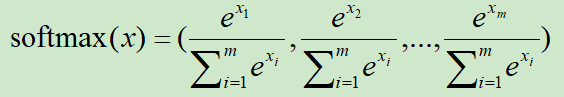
显然,x进行softmax处理后,会归一化为[0,1],且和为1
举例:假设x=[0,2,-3], softmax(x)=[0.11849965, 0.8756006 , 0.00589975]
|
Softmax交叉熵 |
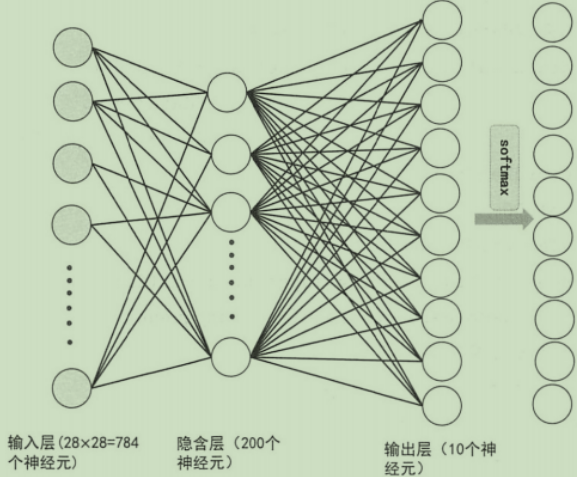
在神经网络的多分类中,假设是3分类,那么输出层就有3个神经元。
假设神经网络对某个样本的输出为out = [4,-5,6],样本的真实标签为[0,0,1],此时的softmax交叉熵为0.1269,计算公式为:
①首先对[4,-5,6]做softmax转换,softmax(out)=[1.19201168e-01 1.47105928e-05 8.80784121e-01]
②sum(-y*log(softmax(_y)))
import numpy as np
out = np.array([4,-5,6])
y = np.array([0,0,1])
softmax = np.exp(out)/sum(np.exp(out))
sum(-y*np.log(softmax))
Demo2:
import numpy as np
import tensorflow as tf # 方式1
out = np.array([[4.0, -5.0, 10.0], [1.0, 5.0, 4.0], [1.0, 15.0, 4.0]],dtype=np.float64)
y = np.array([[0, 0, 1], [0, 1, 0], [0, 1, 0]],dtype=np.float64)
softmax = np.exp(out) /np.sum(np.exp(out),axis=1).reshape(-1,1)
res = np.sum(-y * np.log(softmax))/len(y)
print(res) # 方式2
res2 = tf.losses.softmax_cross_entropy(onehot_labels=y, logits=out, label_smoothing=0)
print(tf.Session().run(res2)) # 方式3
res3 = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y,logits=out))
print(tf.Session().run(res3))
0.10968538820896588
0.10968538373708725
0.10968538820896594
|
参考资料 |
《图解深度学习与神经网络:从张量到TensorFlow实现》_张平
深度学习面试题07:sigmod交叉熵、softmax交叉熵的更多相关文章
- 深度学习面试题13:AlexNet(1000类图像分类)
目录 网络结构 两大创新点 参考资料 第一个典型的CNN是LeNet5网络结构,但是第一个引起大家注意的网络却是AlexNet,Alex Krizhevsky其实是Hinton的学生,这个团队领导者是 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- 深度学习面试题29:GoogLeNet(Inception V3)
目录 使用非对称卷积分解大filters 重新设计pooling层 辅助构造器 使用标签平滑 参考资料 在<深度学习面试题20:GoogLeNet(Inception V1)>和<深 ...
- 深度学习面试题27:非对称卷积(Asymmetric Convolutions)
目录 产生背景 举例 参考资料 产生背景 之前在深度学习面试题16:小卷积核级联卷积VS大卷积核卷积中介绍过小卷积核的三个优势: ①整合了三个非线性激活层,代替单一非线性激活层,增加了判别能力. ②减 ...
- 深度学习面试题05:激活函数sigmod、tanh、ReLU、LeakyRelu、Relu6
目录 为什么要用激活函数 sigmod tanh ReLU LeakyReLU ReLU6 参考资料 为什么要用激活函数 在神经网络中,如果不对上一层结点的输出做非线性转换的话,再深的网络也是线性模型 ...
- 深度学习面试题21:批量归一化(Batch Normalization,BN)
目录 BN的由来 BN的作用 BN的操作阶段 BN的操作流程 BN可以防止梯度消失吗 为什么归一化后还要放缩和平移 BN在GoogLeNet中的应用 参考资料 BN的由来 BN是由Google于201 ...
- 深度学习面试题20:GoogLeNet(Inception V1)
目录 简介 网络结构 对应代码 网络说明 参考资料 简介 2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名.VGG获得了第二 ...
- 深度学习面试题28:标签平滑(Label smoothing)
目录 产生背景 工作原理 参考资料 产生背景 假设选用softmax交叉熵训练一个三分类模型,某样本经过网络最后一层的输出为向量x=(1.0, 5.0, 4.0),对x进行softmax转换输出为: ...
- 深度学习面试题26:GoogLeNet(Inception V2)
目录 第一层卷积换为分离卷积 一些层的卷积核的个数发生了变化 多个小卷积核代替大卷积核 一些最大值池化换为了平均值池化 完整代码 参考资料 第一层卷积换为分离卷积 net = slim.separab ...
随机推荐
- UCOSIII等待多个内核对象
内核对象 内核对象包括信号量.互斥信号量.消息队列和事件标志组 UCOSIII中允许任务同时等待多个信号量和多个消息队列 主结构体 typedef struct os_pend_data OS_PEN ...
- 二十二、mysql索引原理详解
背景 使用mysql最多的就是查询,我们迫切的希望mysql能查询的更快一些,我们经常用到的查询有: 按照id查询唯一一条记录 按照某些个字段查询对应的记录 查找某个范围的所有记录(between a ...
- html()方法与append()方法
注意加#!!!!!! $("#valuess").html("<input type='text' name='name' value= " + valu ...
- Redhat下Oracle 12c单节点安装
操作系统:Redhat6.7 64位[root@Oracle12CDB ~]# more /etc/redhat-release Red Hat Enterprise Linux Server rel ...
- kubeadm添加新master或node
一.首先在master上生成新的token kubeadm token create --print-join-command [root@cn-hongkong nfs]# kubeadm toke ...
- [https][tls] 如何使用wireshark查看tls/https加密消息--使用私钥
之前总结了使用keylog进行https流量分析的方法: [https][tls] 如何使用wireshark查看tls/https加密消息--使用keylog 今天总结一下使用服务器端证书私钥进行h ...
- onvirt安装linux系统
情况说明: (1)本文接前文kvm虚拟化学习笔记(十九)之convirt集中管理平台搭建,采用convirt虚拟化平台安装linux操作系统的过程,这个过程中需要对convirt进行一系列的配置才能真 ...
- openstack各服务端口使用情况
端口占用情况 端口情况可以使用ss -tanp命令进行查看 监听的所有端口ss -tanp | grep LISTEN 基础服务 22 --SSH 3306 --MariaDB(MySQL) 2701 ...
- vuex传值的使用
1.导入vuex import Vuex from 'vuex' Vue.use(Vuex); 2.创建store实例 let store = new Vuex.Store({ state:{ cou ...
- python获取当前文件夹下所有文件名【转】
os 模块下有两个函数: os.walk() os.listdir() 1 # -*- coding: utf-8 -*- 2 3 import os 4 5 def file_name(file_d ...