Meta推出Agent Learning via Early Experience,推动语言代理自主学习新范式

原文: https://mp.weixin.qq.com/s/fhNRtk0FhK6K9_LBLwbDSg
全文摘要
在人工智能领域,语言代理(Language Agents)的自主学习能力一直是研究热点。传统依赖专家数据的模仿学习(Imitation Learning)存在泛化能力弱、依赖人工标注等问题,而强化学习(Reinforcement Learning)又受限于奖励信号难以获取的困境。近日,来自Meta Superintelligence Labs、FAIR at Meta和The Ohio State University的研究团队提出了一种名为早期经验(Early Experience)的新范式,为语言代理的自主学习开辟了新路径。这项研究不仅解决了现有方法的局限性,还为未来构建更智能的AI系统奠定了基础。
论文地址:https://arxiv.org/abs/2510.08558
论文标题:Agent Learning via Early Experience
论文方法
核心亮点速览
- 新范式提出:提出"早期经验",将代理自身行为及其导致的环境状态变化转化为监督信号,无需外部奖励。
- 双策略驱动:隐式世界建模(Implicit World Modeling)和自我反思(Self-Reflection)两大策略,让代理从经验中学习。
- 全面验证:在8个不同领域(如科学实验、网页导航、工具使用等)和多个模型家族上验证有效性。
- 性能提升:相比模仿学习,成功率平均提升9.6%,泛化能力提升9.4%,且为后续强化学习提供良好基础。
从模仿学习到自主学习:早期经验的桥梁作用
传统方法的局限性
当前语言代理主要依赖两种学习方式:
- 模仿学习:通过专家演示数据训练,但存在数据依赖性强、泛化能力弱的问题。
- 强化学习:依赖环境提供的奖励信号,但许多真实环境(如网页交互)缺乏可验证的奖励机制。
早期经验的创新之处
研究团队提出的早期经验(Early Experience)范式,巧妙地将代理自身行为及其导致的环境状态变化转化为监督信号。这种方法既不需要专家数据,也不依赖外部奖励,而是让代理通过"试错"积累经验,逐步提升决策能力。
核心思想:代理在每个状态生成多个候选动作,执行后观察环境反馈(如网页变化、工具输出等),将这些状态转换作为监督信号进行学习。
论文实验
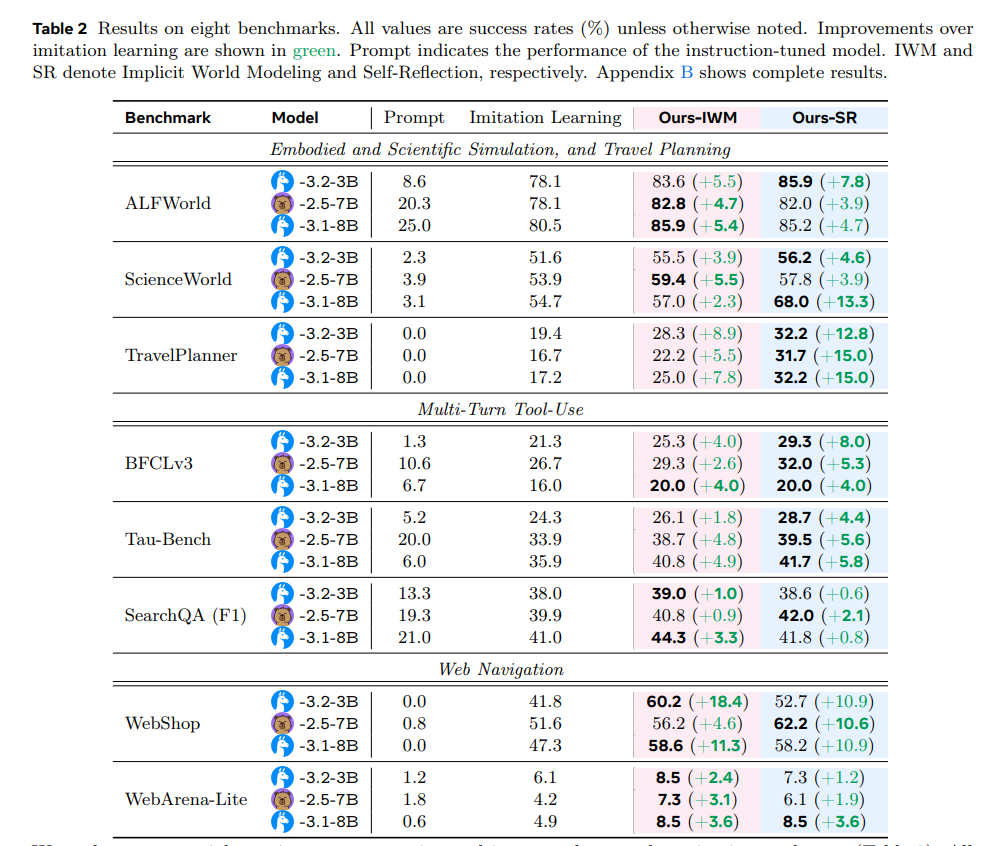
两大核心策略:隐式世界建模与自我反思
隐式世界建模(Implicit World Modeling)
原理:将代理自身动作导致的环境状态变化视为自然语言预测任务,训练代理预测未来状态。
- 训练过程:代理在专家状态生成多个候选动作,执行后获得环境反馈(自然语言描述的下一状态),通过预测这些状态学习环境动力学。
- 优势:帮助代理理解环境动态,提升对非专家行为的鲁棒性。
实验结果:在ALFWorld和WebShop等环境中,成功率提升5.5%-18.4%。
自我反思(Self-Reflection)
原理:代理比较自身动作与专家动作的差异,生成自然语言解释为何专家动作更优。
- 训练过程:代理生成多个候选动作及其结果,通过大语言模型生成对比解释,形成(状态-解释-动作)三元组作为训练数据。
- 优势:提升代理对决策原则的理解,增强泛化能力。
实验结果:在TravelPlanner和BFCLv3等任务中,成功率提升12.8%-15.0%。
多维度实验验证:性能与泛化能力双突破
实验环境
研究团队在8个不同领域进行了全面验证,包括:
- 具身导航:ALFWorld(家庭任务)
- 科学实验:ScienceWorld(实验室操作)
- 长时序规划:TravelPlanner(旅行规划)
- 工具使用:BFCLv3(多轮API调用)
- 网页导航:WebShop(电商购物)
关键结果
| 环境 | 模型 | 模仿学习 | 隐式世界建模 | 自我反思 |
|---|---|---|---|---|
| ALFWorld | Llama-3.2-3B | 78.1% | 83.6% (+5.5) | 85.9% (+7.8) |
| WebShop | Llama-3.1-8B | 58.6% | 72.7% (+14.1) | 58.2% (+0.4) |
| ScienceWorld | Qwen-2.5-7B | 53.9% | 59.4% (+5.5) | 68.0% (+14.1) |
关键发现:
- 早期经验在所有环境中均优于模仿学习
- 自我反思在需要多步推理的任务中表现更优
- 隐式世界建模在结构化环境中效果显著
未来展望:从早期经验到完全自主学习
局限性
- 长时序信用分配:当前方法主要处理短时序经验,长时序任务仍需探索。
- 环境复杂性:在高度动态的环境中,状态预测难度增加。
潜在方向
- 跨环境迁移:将一个环境中学到的经验迁移到其他领域。
- 持续学习:结合奖励信号,在真实环境中实现持续改进。
- 大规模应用:在真实世界部署,收集有机交互数据驱动策略优化。
结语
"早期经验"范式为语言代理的自主学习提供了新的思路。通过将代理自身行为转化为监督信号,不仅解决了传统方法的局限性,还为未来构建更智能的AI系统奠定了基础。这项研究展示了自主学习的潜力,预示着AI代理将逐步摆脱对人工标注数据的依赖,迈向真正的自主进化。
Meta推出Agent Learning via Early Experience,推动语言代理自主学习新范式的更多相关文章
- First Wainberg-2018-Deep learning in biomedicine Experience
ppt+paper 链接:https://pan.baidu.com/s/14toqjcSJti5ZXT3ff4rwIA 提取码:xgkt
- AndroidP推出多项AI功能,会不会引发新的隐私担忧?
让谷歌很"伤心"的是,相比苹果iOS系统的统一,Android系统的碎片化态势实在太严重了.就像已经发布一年多的Android O,其占有率仅有4.6%.主要是因为很多手机厂商都会 ...
- 抛弃模板,一种Prompt Learning用于命名实体识别任务的新范式
原创作者 | 王翔 论文名称: Template-free Prompt Tuning for Few-shot NER 文献链接: https://arxiv.org/abs/2109.13532 ...
- Personal Learning Path of Java——Java语言基础
Java语言是面向对象编程语言,Java程序的基本组成单元是类,类体中又包括属性和方法两部分.每一个程序都必须包含一个main()方法,含有main()方法的类称为主类. 如下面代码: package ...
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
- 深度学习Deep learning
In the last chapter we learned that deep neural networks are often much harder to train than shallow ...
- Common Pitfalls In Machine Learning Projects
Common Pitfalls In Machine Learning Projects In a recent presentation, Ben Hamner described the comm ...
- Decision Boundaries for Deep Learning and other Machine Learning classifiers
Decision Boundaries for Deep Learning and other Machine Learning classifiers H2O, one of the leading ...
- Keras 自适应Learning Rate (LearningRateScheduler)
When training deep neural networks, it is often useful to reduce learning rate as the training progr ...
随机推荐
- iPaaS中API自动化测试的作用
在iPaaS中,API自动化测试的作用主要是有助于验证集成流程的正确性.保证数据一致性.监控和故障排除.性能评估.支持持续集成和持续交付,并增加合作和安全性.通过自动化测试,可以提高iPaaS平台的稳 ...
- SciTech-EECS-Autosar-0: 软件系统总架构 + 智能驾驶的"控制板硬件电路(主控制器的电路板)成品
SciTech-EECS-Autosar-0: Autosar软件系统总架构 智能驾驶的"控制板(主控制器的电路板) 智能驾驶控制器的电路板(图片) TESLA MODEL 3
- Infinity: Set Theory is the true study of Infinity
AN INTRODUCTION TO SET THEORY - Professor William A. R. Weiss, October 2, 2008 Infinity -> Set Th ...
- 进阶篇:6.2)公差的正态分布与CPK与制程能力(重要)
本章目的:明确公差分布(Tolerance Distribution)也有自己的形状,了解CPK概念. 1.正态分布(常态分布)normal distribution的概念 统计分析常基于这样的假设: ...
- DockQuery | 基于E-R图的数据建模功能使用实践
DockQuery 天狼最新版本已经发布,伙伴们有没有下载体验呢? 与第一版相比,DockQuery 1.2.0 版本有许多更新,在页面和功能上都进行了完善.其中非常值得一提的是「数据建模」功能,以可 ...
- 完全使用TRAE和AI 开发一款完整的应用----第一周
虽然也在工作使用使用ai 补全代码或者完善代码,但还是没有完全使用ai 做一款应用,不依赖手工编程.不依赖人查找资料 所以决定自己写一个应用玩玩,感受一下全完使用ai开发一款应用的乐趣, 跟上时代发展 ...
- 转-Java 异常处理的 20 个最佳实践,你知道几个?
作 者:武培轩 出 处:https://www.cnblogs.com/wupeixuan 原文链接:https://www.cnblogs.com/wupeixuan/p/11746117.ht ...
- Java学习:工具类、构造器、实体类使用场景
封装的设计要求:合理隐藏.合理暴露 合理隐藏:创建成员变量时,使用private修饰 private int id; // 电影编号 合理暴露:创建成员方法时,使用public修饰的get方法和set ...
- Composer 安装 topthink/think-captcha 时报错 requires topthink/framework ^6.0.0 【已解决】
ThinkPHP 5.1 安装图形验证码的时候报错: composer require topthink/think-captcha 出错原因: 当我们使用命令 composer require to ...
- win10如何彻底关闭自带defender杀毒软件【教程详解】
windows defender是win10系统自带的杀毒软件,有的时候我们需要关闭它才能运行某些软件,而网上的一些针对关闭win10自带的杀毒软件的方法似乎并没有什么效果,下面就来教大家彻底关闭wi ...