deepseek+coze实战:一键抓取百条抖音爆款视频,自动存入飞书表格
大家好,我是汤师爷~
批量获取抖音视频文案这件事,一直有技术门槛。
很多朋友因为不懂技术,只能花钱买工具来完成这项任务。
今天我要分享一个Coze智能体的解决方案
只需输入关键词就能自动批量获取视频文案,轻松实现100条文案的采集工作。效果如下:
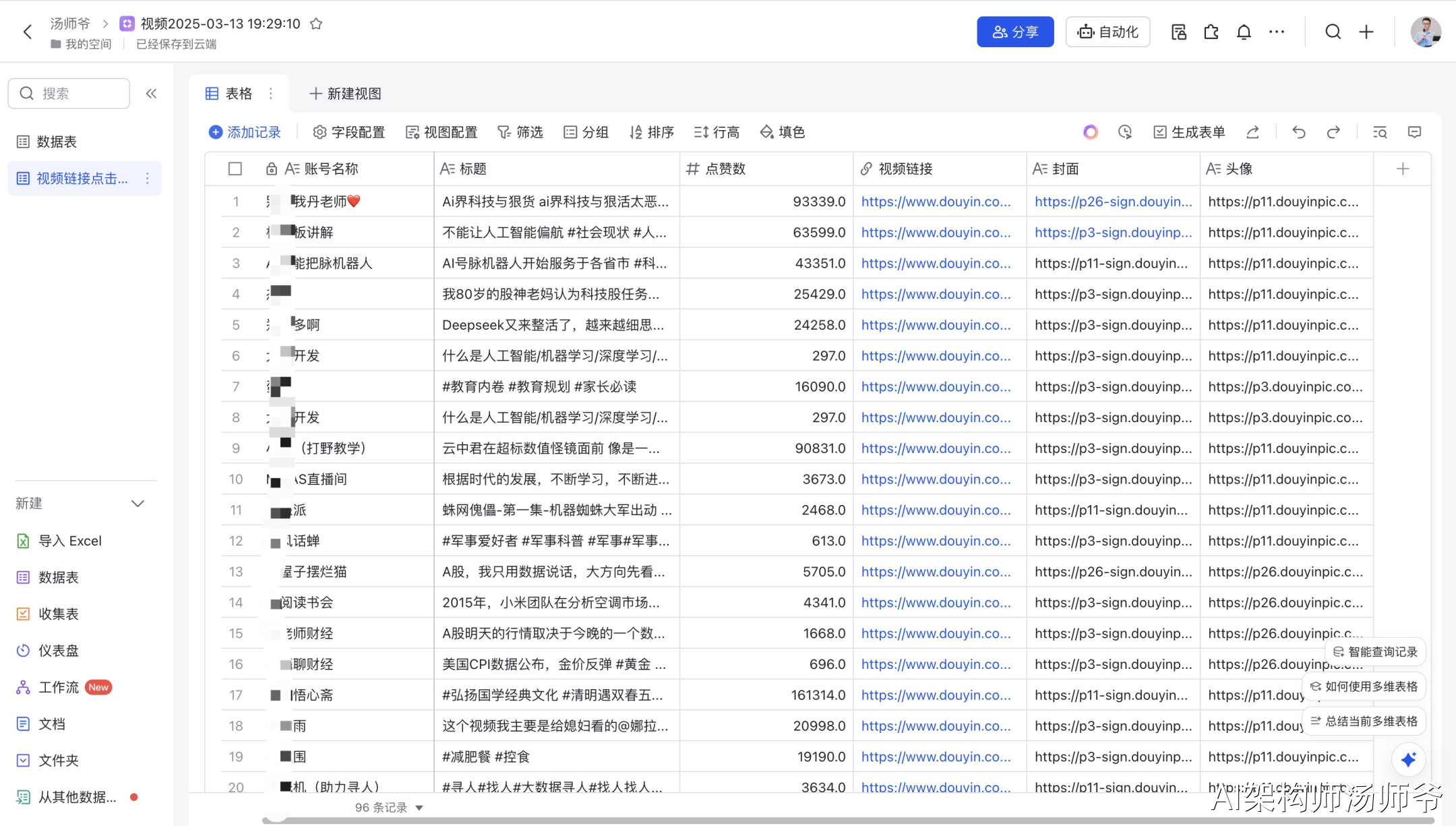
1.整体工作流
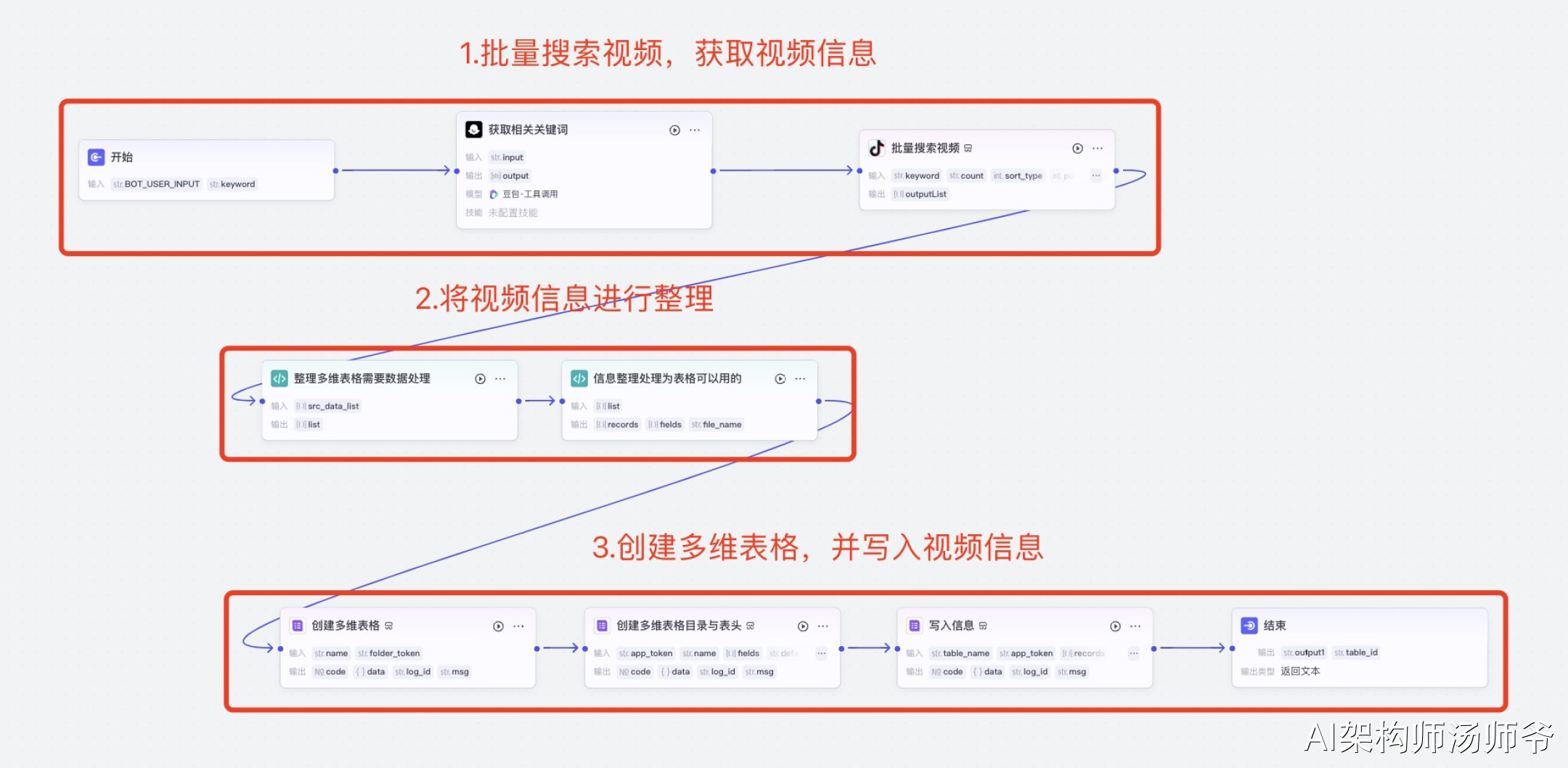
1.批量搜索视频,获取视频信息
2.将视频信息进行整理
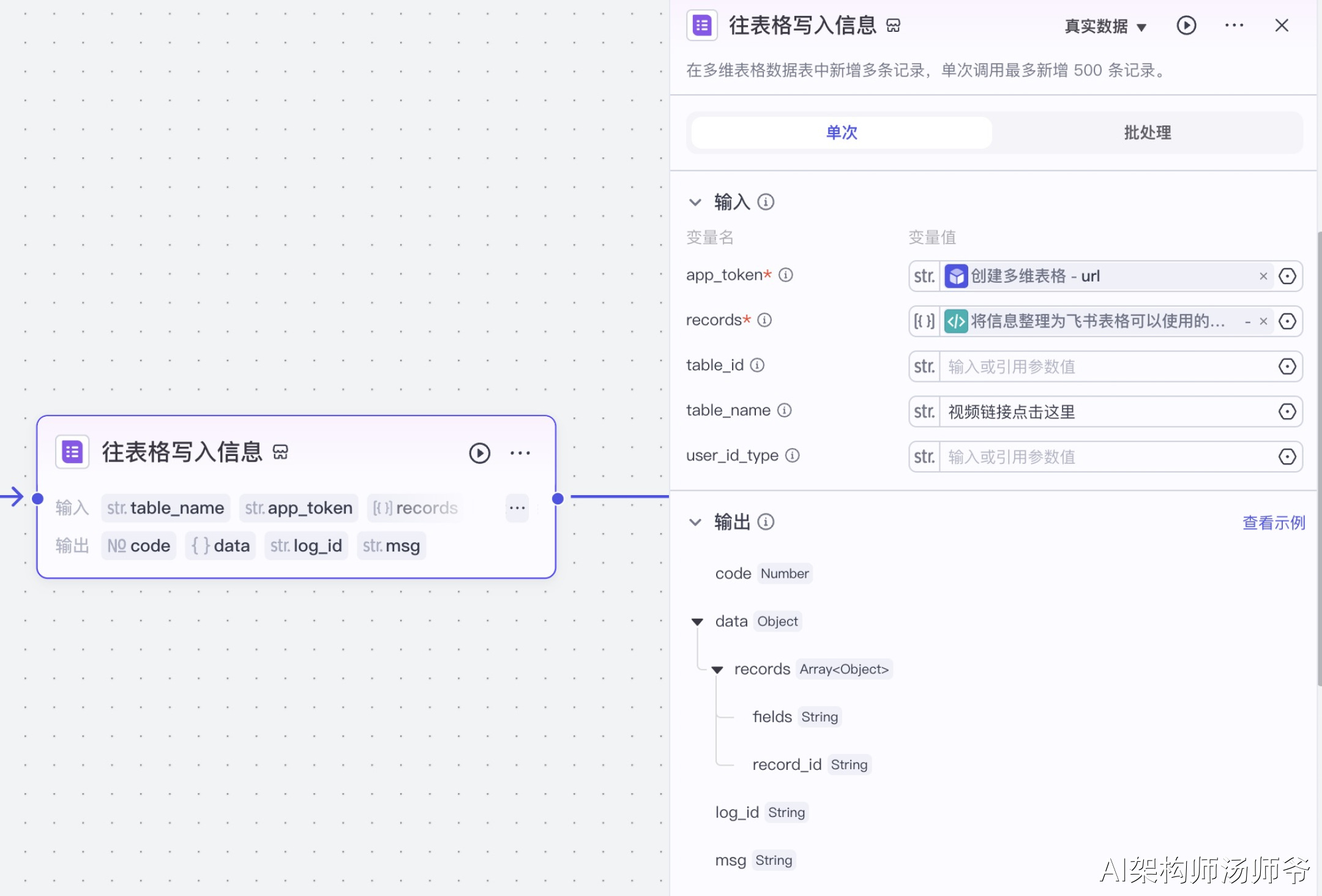
3.创建多维表格,并写入视频信息
2.详细工作流节点
2.1获取相关关键词
根据用户提供的关键词,生成50个相关的关键词。
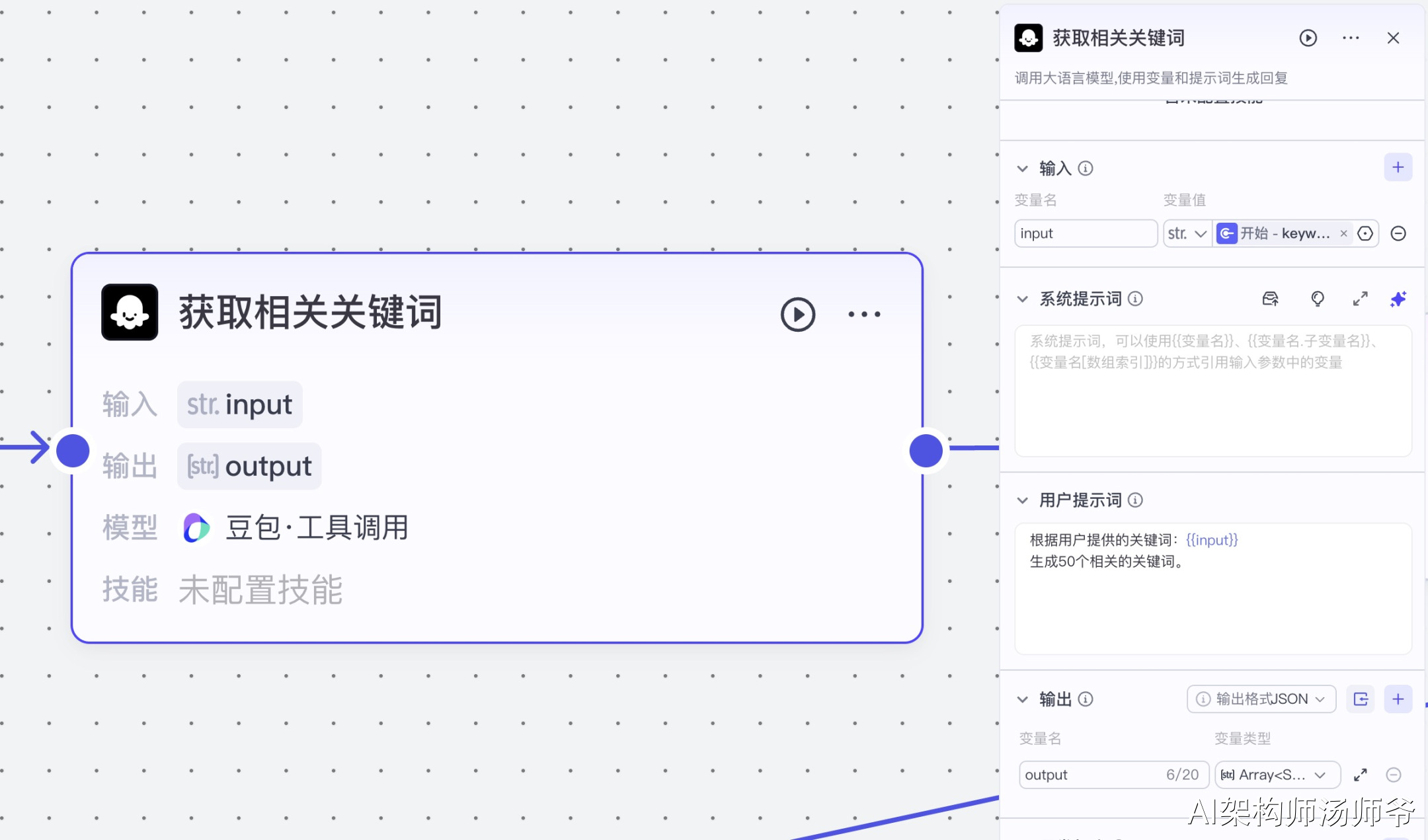
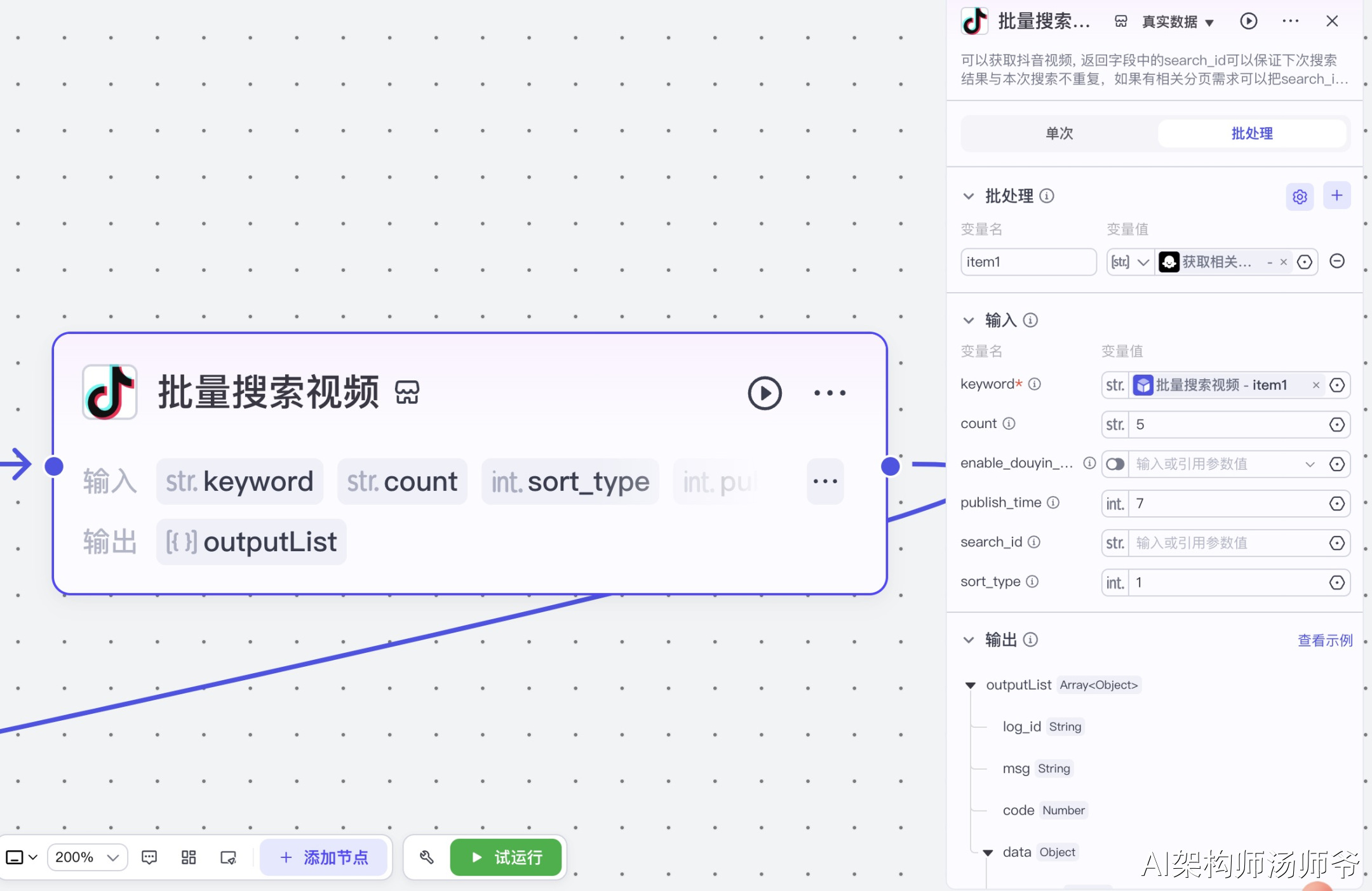
2.2批量搜索视频
利用抖音视频搜索插件功能,我们能够快速而高效地进行批量视频搜索。
通过设定特定的搜索参数,我们可以精准定位所需的视频内容。
2.3对信息进行格式化
将信息整理为飞书表格可以使用的数据。
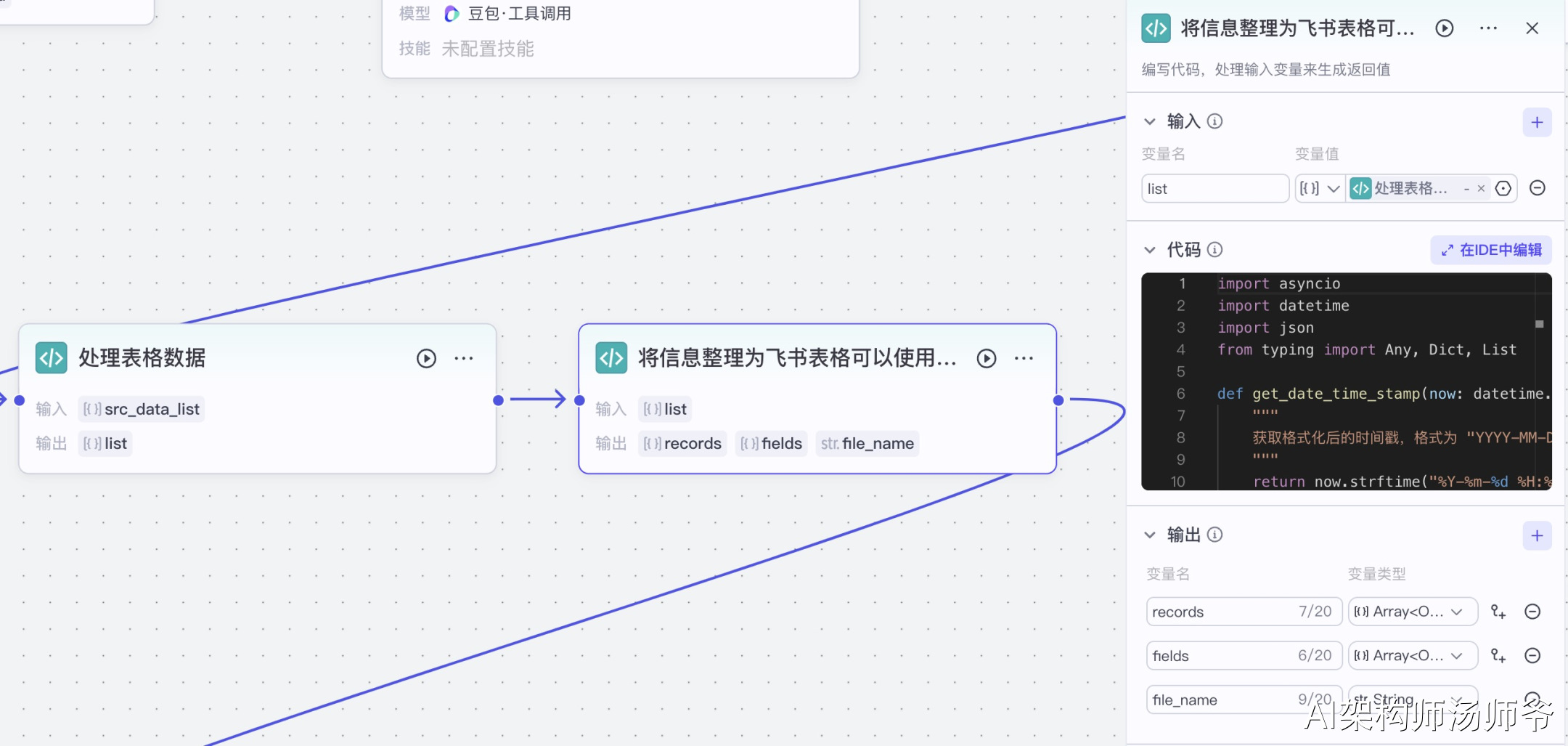
处理信息的Python代码如下:
import asyncio
import datetime
import json
from typing import Any, Dict, List
def get_date_time_stamp(now: datetime.datetime) -> str:
"""
获取格式化后的时间戳,格式为 "YYYY-MM-DD HH:MM:SS"
"""
return now.strftime("%Y-%m-%d %H:%M:%S")
async def main(args: Args) -> Output:
params = args.params
video_list = params.get("list", [])
records: List[Dict[str, Any]] = []
for video in video_list:
# 构造 fields 字段对应的字典
fields_dict = {
"标题": video.get("title"),
"视频链接": {"link": video.get("link")},
"封面": video.get("cover"),
"点赞数": video.get("digg_count"),
"账号名称": video.get("nickname"),
"头像": video.get("avatar")
}
# 将字典转换为 JSON 字符串
record = {"fields": json.dumps(fields_dict, ensure_ascii=False)}
records.append(record)
# 构造 fields 列表,每个字段包含 field_name 和 type
fields: List[Dict[str, Any]] = []
fields.append({"field_name": "账号名称", "type": 1})
fields.append({"field_name": "标题", "type": 1})
fields.append({"field_name": "点赞数", "type": 2})
fields.append({"field_name": "视频链接", "type": 15})
fields.append({"field_name": "封面", "type": 1})
fields.append({"field_name": "头像", "type": 1})
# 构造文件名称,前缀为 "视频" 加上当前时间戳
file_name = "视频" + get_date_time_stamp(datetime.datetime.now())
ret = {
"records": records,
"fields": fields,
"file_name": file_name,
}
return ret
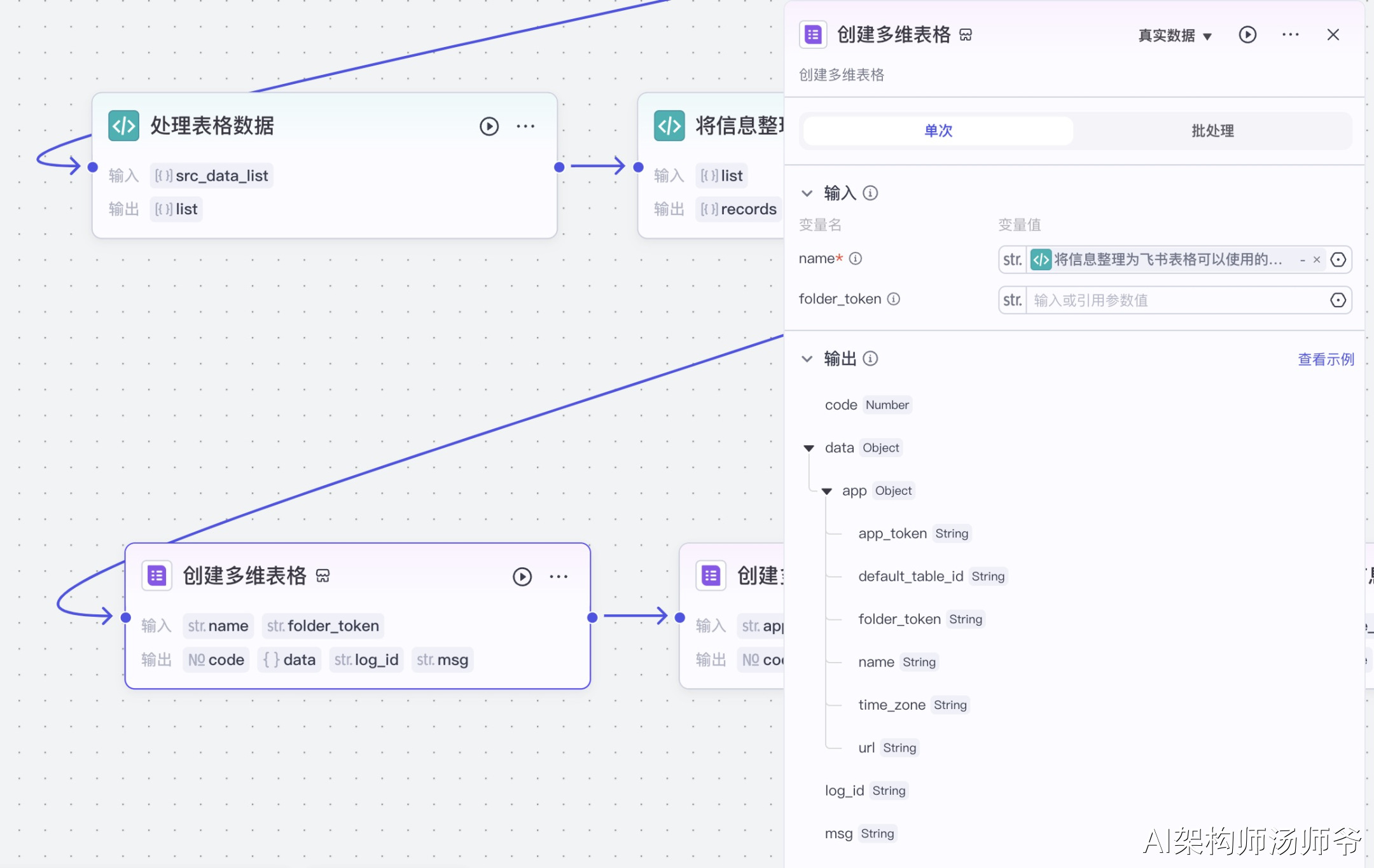
2.4创建多维表格
创建多维表格。
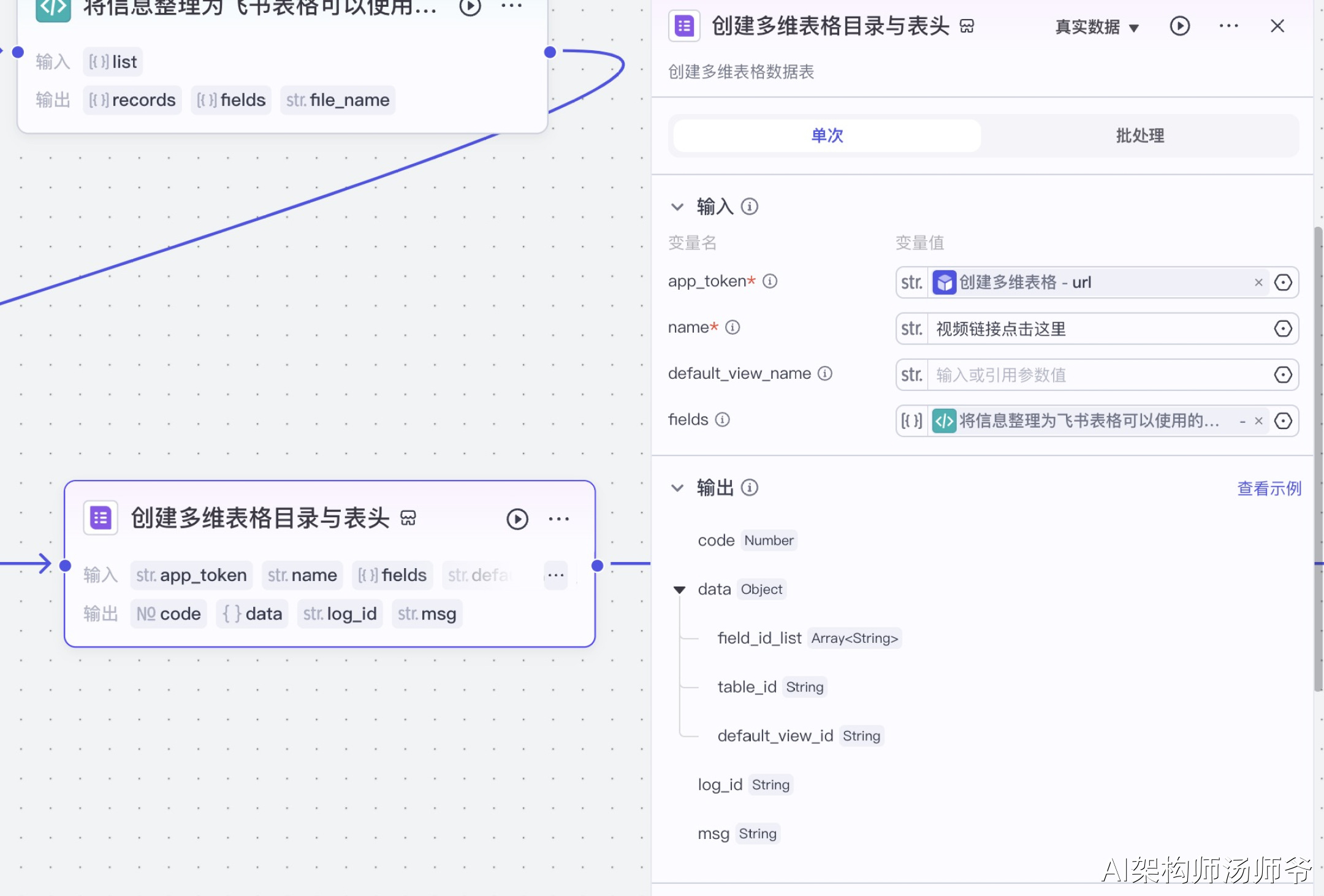
接下来我们需要创建多维表格的基础结构,包括设置表格的目录层级以及定义表头字段。
这些表头字段将包含我们需要存储的视频信息,如标题、视频链接、封面、点赞数、账号名称、头像。
将收集到的视频信息按照预设的格式导入到飞书表格中。
在这一步骤中,系统会自动将每条视频的详细信息,写入到对应的表格单元格中。
3.总结
我们今天分享了如何用Coze智能体来批量获取抖音视频文案,整个过程其实很简单。
先用关键词搜视频,然后把找到的信息整理一下,最后存到飞书表格里。
这套流程只要会用Coze就行,再也不用花钱买采集工具,希望这个小技巧能帮大家提高工作效率。
如果你觉得有用的话,欢迎分享给需要的朋友哦~
本文已收录于,我的技术博客:tangshiye.cn 里面有,DeepSeek 资料,AI 智能体教程,算法 Leetcode 详解,BAT 面试真题,架构设计,等干货分享。
deepseek+coze实战:一键抓取百条抖音爆款视频,自动存入飞书表格的更多相关文章
- Python3.x:抓取百事糗科段子
Python3.x:抓取百事糗科段子 实现代码: #Python3.6 获取糗事百科的段子 import urllib.request #导入各类要用到的包 import urllib import ...
- php中CURL技术模拟登陆抓取数据实战,抓取某校教务处学生成绩。
这两天有基友要php中curl抓取教务处成绩的源码,用于微信公众平台的开发.下面笔者只好忍痛割爱了.php中CURL技术模拟登陆抓取数据实战,抓取沈阳工学院教务处学生成绩. 首先,教务处登录需要验证码 ...
- 芝麻HTTP:Python爬虫实战之抓取淘宝MM照片
本篇目标 1.抓取淘宝MM的姓名,头像,年龄 2.抓取每一个MM的资料简介以及写真图片 3.把每一个MM的写真图片按照文件夹保存到本地 4.熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL ...
- 芝麻HTTP:Python爬虫实战之抓取爱问知识人问题并保存至数据库
本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表达式的简 ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
- 一键抓取Android的Locat Log
很多小伙伴在做App测试时,一遇到Cash,开发同学最常说的一句话,就是抓下Locat日志,很多小伙伴一听到这个抓取日志就会觉得有点烦. 主要有2点: 1.是这个bug可能不好 ...
- 用 Java 抓取优酷、土豆等视频
1. [代码][JavaScript]代码 import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes ...
- 大数据抓取采集框架(摘抄至http://blog.jobbole.com/46673/)
摘抄至http://blog.jobbole.com/46673/ 随着BIG DATA大数据概念逐渐升温,如何搭建一个能够采集海量数据的架构体系摆在大家眼前.如何能够做到所见即所得的无阻拦式采集.如 ...
- 用PHP抓取百度贴吧邮箱数据
注:本程序可能非常适合那些做百度贴吧营销的朋友. 去逛百度贴吧的时候,经常会看到楼主分享一些资源,要求留下邮箱,楼主才给发. 对于一个热门的帖子,留下的邮箱数量是非常多的,楼主需要一个一个的去复制那些 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
随机推荐
- .NET周刊【2月第2期 2025-02-09】
国内文章 开箱即用的.NET MAUI组件库 V-Control 发布了! https://www.cnblogs.com/jevonsflash/p/18701494 文章介绍了V-Control, ...
- oh-my-bash在git大仓库下的卡顿问题解决方案
使用oh-my-bash的同学都知道,在cd进入一些git大仓库的时候,oh-my-bash会贴心的帮你扫描一遍 然后你就卡那(nei)了... (风中凌乱.jpg) 本文告诉大家一种关闭git扫描的 ...
- AD 测试点覆盖率的统计
在用Altium Designer软件设计PCB时,有时会有统计这个工程的测试点覆盖率需求.在AD 中有2种类型的测试点:Fabrication testppoint(用于PCB的下线电气测试)和As ...
- Android应用借助LinearLayout实现垂直水平居中布局
首先说的是LinearLayout布局下的居中一般是这样的: (注意:android:layout_width="fill_parent" android:layout_heigh ...
- 盒马新零售基于DataWorks搭建数据中台的实践(转载自阿里云的计算平台负责人--许日花名欢伯)
简介:大家好,我叫许日花名欢伯,在2016年盒马早期的时候,我就转到了盒马的事业部作为在线数据平台的研发负责人,现在阿里云的计算平台负责DataWorks的建模引擎团队.今天的分享内容也来源于另一位嘉 ...
- .NET 10 首个预览版发布,跨平台开发与性能全面提升
前言 2024年2月25日,微软正式推出 .NET 10 预览版 1,标志着这一跨平台开发框架迈入新里程碑. 本次更新聚焦 JIT 编译器优化.运行时性能提升和跨平台开发体验增强,同时引入多项开发者期 ...
- 基于Qt的在QGraphicsView中绘制带有可动拐点的连线的一种方法
摘要:本文详细介绍了基于Qt框架在`QGraphicsView`中实现带有可动拐点连线的绘制方法.通过自定义`CustomItem`和`CustomPath`类,结合`QGraphicsIte ...
- 分布式锁—3.Redisson的公平锁
大纲 1.Redisson公平锁RedissonFairLock概述 2.公平锁源码之加锁和排队 3.公平锁源码之可重入加锁 4.公平锁源码之新旧版本对比 5.公平锁源码之队列重排 6.公平锁源码之释 ...
- glib-2.60在win64,msys2下编译
前阵子,工作原因,需要在win7 64下的msys2来编译glib,下面是一些踩过的坑: 事先声明一下,这些个解决方式及纯粹是为了编译通过,可能有些做法不太适合一些需要正常使用的场合,烦请各位注意下. ...
- Oracle10g RAC -- Linux 集群文件系统
通常,集群只是一组作为单一系统运行的服务器( PC 或者工作站).但是,这个定义的外延不断显著扩大:集群技术现在不但是一个动态领域,而且其各种应用程序正不断吸收新的特性.此外,集群文件系统技术(无论是 ...