Python爬虫之正则表达式(3)


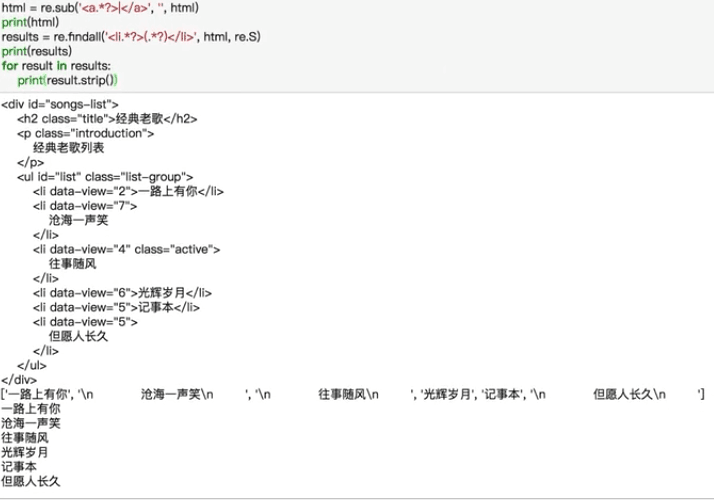
# re.sub
# 替换字符串中每一个匹配的子串后返回替换后的字符串
import re
content = 'Extra strings Hello 1234567 World_This is a Regex Demo Extra strings'
content = re.sub('\d+', '', content)
print(content) import re
content = 'Extra strings Hello 1234567 World_This is a Regex Demo Extra strings'
content = re.sub('\d+', 'Replacement', content)
print(content) # \1 是转义字符
import re
content = 'Extra strings Hello 1234567 World_This is a Regex Demo Extra strings'
content = re.sub('(\d+)', r'\1 8910', content)
print(content) # re.compile
# 将正则字符串编译成正则表达式对象
# 将一个正则表达式串编译成正则对象,以便于复用该匹配模式
import re
content = '''Hello 1234567 World_This
is a Regex Demo'''
pattern = re.compile('Hello.*Demo', re.S)
result = re.match(pattern, content)
print(result)
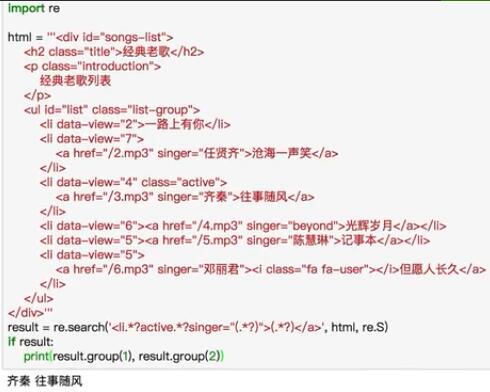
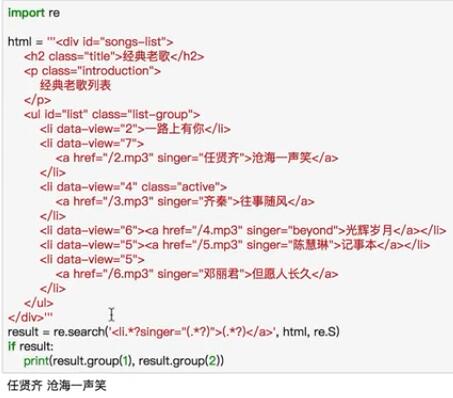
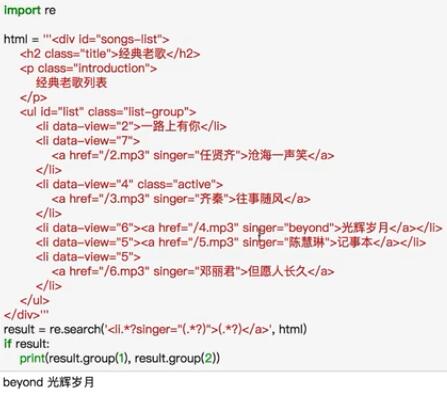
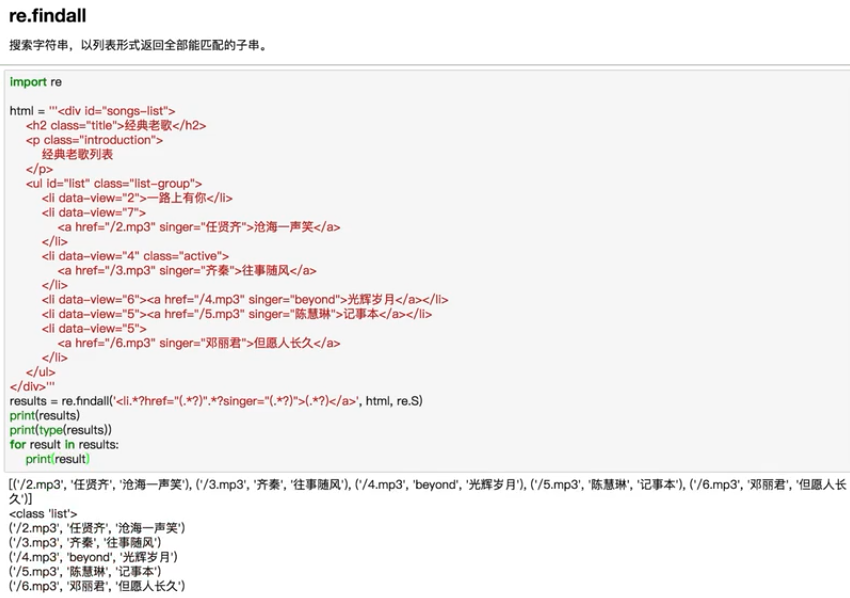
下面是爬取豆瓣图书的实战代码
import requests
import re
content = requests.get('https://book.douban.com/').text
# print(content)
pattern = re.compile('<li.*?cover.*?title="(.*?)".*?author">(.*?)</div>.*?year">(.*?)</span>.*?</li>', re.S)
results = re.findall(pattern, content)
for result in results:
name, author, date = result
author = re.sub("\s", "", author)
date = re.sub("\s", "", date)
print("【书名】:", name, " 【作者】:", author, " 【出版年】:", date)
本篇内容为:崔庆才爬虫学习笔记
Python爬虫之正则表达式(3)的更多相关文章
- 玩转python爬虫之正则表达式
玩转python爬虫之正则表达式 这篇文章主要介绍了python爬虫的正则表达式,正则表达式在Python爬虫是必不可少的神兵利器,本文整理了Python中的正则表达式的相关内容,感兴趣的小伙伴们可以 ...
- 【Python爬虫】正则表达式与re模块
正则表达式与re模块 阅读目录 在线正则表达式测试 常见匹配模式 re.match re.search re.findall re.compile 实战练习 在线正则表达式测试 http://tool ...
- python 爬虫之-- 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 正则表达式非python独有,python 提供了正则表达式的接口,re模块 一.正则匹配字符简介 模式 描述 \d ...
- python爬虫训练——正则表达式+BeautifulSoup爬图片
这次练习爬 传送门 这贴吧里的美食图片. 如果通过img标签和class属性的话,用BeautifulSoup能很简单的解决,但是这次用一下正则表达式,我这也是参考了该博主的博文:传送门 所有图片的s ...
- 【python爬虫和正则表达式】爬取表格中的的二级链接
开始进公司实习的一个任务是整理一个网页页面上二级链接的内容整理到EXCEL中,这项工作把我头都搞大了,整理了好几天,实习生就是端茶送水的.前段时间学了爬虫,于是我想能不能用python写一个爬虫一个个 ...
- Python爬虫运用正则表达式
我看到最近几部电影很火,查了一下猫眼电影上的数据,发现还有个榜单,里面有各种经典和热映电影的排行榜,然后我觉得电影封面图还挺好看的,想着一张一张下载真是费时费力,于是突发奇想,好像可以用一下最近学的东 ...
- Python爬虫之正则表达式(1)
廖雪峰正则表达式学习笔记 1:用\d可以匹配一个数字:用\w可以匹配一个字母或数字: '00\d' 可以匹配‘007’,但是无法匹配‘00A’; ‘\d\d\d’可以匹配‘010’: ‘\w\w\d’ ...
- python爬虫之正则表达式
一.简介 正则表达式,又称正规表示式.正规表示法.正规表达式.规则表达式.常规表示法(英语:Regular Expression,在代码中常简写为regex.regexp或RE),计算机科学的一个概念 ...
- Python爬虫基础——正则表达式
说到爬虫,不可避免的会牵涉到正则表达式. 因为你需要清晰地知道你需要爬取什么信息?它们有什么共同点?可以怎么去表示它们? 而这些,都需要我们熟悉正则表达,才能更好地去提取. 先简单复习一下各表达式所代 ...
随机推荐
- Oracle绝对秒数转换为时间戳
一般Oracle得到的时间格式为: 1970-01-05 01:23:56.297 为了计算两个时间的差值: 1970-01-05 01:23:56.297 与 1970-01-05 01:24:57 ...
- 论Java访问权限控制的重要性
人在什么面前最容易失去抵抗力? 美色,算是一个,比如说西施的贡献薄就是忍辱负重.以身报国.助越灭吴:金钱,算是另外一个,我们古人常说“钱乃身外之物,生不带来死不带去”,但我们又都知道“有钱能使鬼推磨” ...
- .Net WebApi 初探
实现服务层与api层共用,也就表明Service层就是api层. 关键类和接口 System.Web.Http.Dispatcher.DefaultHttpControllerSelector web ...
- H5本地存储sessionStorage和localStorage的区别
sessionStorage用于本地存储一个会话(session)中的数据,这些数据只有在同一个会话中的页面才能访问并且当会话结束后数据也随之销毁.因此sessionStorage不是一种持久化的本地 ...
- Python爬虫入门教程 28-100 虎嗅网文章数据抓取 pyspider
1. 虎嗅网文章数据----写在前面 今天继续使用pyspider爬取数据,很不幸,虎嗅资讯网被我选中了,网址为 https://www.huxiu.com/ 爬的就是它的资讯频道,本文章仅供学习交流 ...
- springboot+mybatis+dubbo+aop日志终结篇
之前的几篇文章把dubbo服务层都介绍完毕,本篇文章咱们主要写web层如何调用服务层的方法.文章底部附带源码. 启动服务 服务启动时,会向zk注册自己提供的服务,zk则会记录服务提供者的IP地址以及暴 ...
- 离线批量数据通道Tunnel的最佳实践及常见问题
基本介绍及应用场景 Tunnel是MaxCompute提供的离线批量数据通道服务,主要提供大批量离线数据上传和下载,仅提供每次批量大于等于64MB数据的场景,小批量流式数据场景请使用DataHub实时 ...
- Spring Boot 2.x(六):优雅的统一返回值
目录 为什么要统一返回值 ReturnVO ReturnCode 使用ReturnVO 使用AOP进行全局异常的处理 云撸猫 公众号 为什么要统一返回值 在我们做后端应用的时候,前后端分离的情况下,我 ...
- [JavaScript] JavaScript事件注册,事件委托,冒泡,捕获,事件流
面试题 event 事件 事件委托是什么? 如何阻止事件冒泡,阻止默认事件呢? Javascript 的事件流模型都有什么? 事件绑定和普通事件有什么区别? Event 对象 Event 对象,当事件 ...
- iOS 循环引用讲解(中)
谈到循环引用,可能是delegate为啥非得用weak修饰,可能是block为啥要被特殊对待,你也可能仅仅想到了一个weakSelf,因为它能解决99%的关于循环引用的事情.下面我以个人的理解谈谈循环 ...