node.js爬取ajax接口数据
爬取页面数据与爬取接口数据,我还是觉得爬取接口数据更加简单一点,主要爬取一些分页的数据。
爬取步骤:
1.明确目标接口地址,举个例子 : https://www.vcg.com/api/common/searchImage?phrase=%E6%98%A5%E5%A4%A9&graphicalStyle%5B0%5D=1&page=1 网上随便找到 视觉中国的一个网址
这个网址上的图片非常好看
2.接口返回的数据都是json数据。很统一,处理起来也很便捷。撇开奇葩接口不说。
3.只需要伪造好请求头就可访问,这是重点。
接口参数是 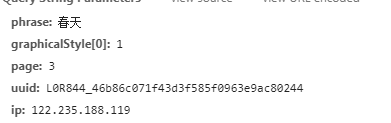
原始数据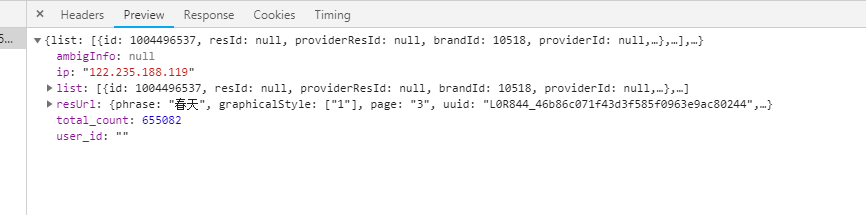
下面是我爬取代码
//引入自己封装的链接数据模块
let mysql = require('./connectdatabase.js');
//SuperAgent是一个轻量级、灵活的、易读的、低学习曲线的客户端请求代理模块,使用在NodeJS环境中。
let superagent = require('superagent');
var fs = require('fs'); // .set( "Accept", "application/json")
// .set( "Cookie", "acw_tc=276aedea15548801849954091e3094245e35937d42d912140fa37630751eeb; clientIp=122.235.188.119; source=baidusem; sajssdk_2015_cross_new_user=1; _ga=GA1.2.109353021.1554880168; _gid=GA1.2.1994909913.1554880168; Hm_lvt_0af14db9b5993b4879812c54f6cf147d=1554880168; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216a06147ef76c7-04ba8d1655b9ab-191f7059-2073600-16a06147ef8279%22%2C%22%24device_id%22%3A%2216a06147ef76c7-04ba8d1655b9ab-191f7059-2073600-16a06147ef8279%22%2C%22props%22%3A%7B%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_utm_source%22%3A%22baidusem%22%2C%22%24latest_utm_medium%22%3A%22cpc%22%2C%22%24latest_utm_campaign%22%3A%22%E7%AB%99%E5%86%85%E6%90%9C%E7%B4%A2%E8%AF%8D-%E6%A0%B8%E5%BF%83%22%2C%22%24latest_utm_content%22%3A%22%E7%AB%99%E5%86%85%E6%90%9C%E7%B4%A2%E8%AF%8D-%E5%9B%BE%E7%89%87%22%2C%22%24latest_utm_term%22%3A%22%E5%9B%BE%E7%89%87%22%7D%7D; Hm_lpvt_0af14db9b5993b4879812c54f6cf147d=1554880467")
// .set( "X-Forwarded-For","122.235.188.119")
// .set( "Host", "www.vcg.com")
// .set( "Accept-Encoding","gzip, deflate, br")
// .set( "Referer", url)
function get(url) {
superagent.get(url)
.set(
{
"Accept": "application/json",
"Accept-Encoding": "gzip, deflate, br",
"Host": "www.vcg.com",
"Referer": 'https://www.vcg.com/api/common/search?phrase=%E6%98%A5%E5%A4%A9&graphicalStyle%5B0%5D=1&page=1',
"X-Forwarded-For": "122.235.188.119",
"Cookie": "acw_tc=276aedea15548801849954091e3094245e35937d42d912140fa37630751eeb; clientIp=122.235.188.119; source=baidusem; sajssdk_2015_cross_new_user=1; _ga=GA1.2.109353021.1554880168; _gid=GA1.2.1994909913.1554880168; Hm_lvt_0af14db9b5993b4879812c54f6cf147d=1554880168; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216a06147ef76c7-04ba8d1655b9ab-191f7059-2073600-16a06147ef8279%22%2C%22%24device_id%22%3A%2216a06147ef76c7-04ba8d1655b9ab-191f7059-2073600-16a06147ef8279%22%2C%22props%22%3A%7B%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_utm_source%22%3A%22baidusem%22%2C%22%24latest_utm_medium%22%3A%22cpc%22%2C%22%24latest_utm_campaign%22%3A%22%E7%AB%99%E5%86%85%E6%90%9C%E7%B4%A2%E8%AF%8D-%E6%A0%B8%E5%BF%83%22%2C%22%24latest_utm_content%22%3A%22%E7%AB%99%E5%86%85%E6%90%9C%E7%B4%A2%E8%AF%8D-%E5%9B%BE%E7%89%87%22%2C%22%24latest_utm_term%22%3A%22%E5%9B%BE%E7%89%87%22%7D%7D; Hm_lpvt_0af14db9b5993b4879812c54f6cf147d=1554880467",
}
)
.end(function (err, res) {
// 抛错拦截
if (err) {
throw Error(err);
return
}
// console.log(res);
fs.appendFile("./接口数据.txt", JSON.stringify(res.text), 'utf-8', function (err) {
if (err) {
console.log(err);
}
});
});
} get('https://www.vcg.com/api/common/searchImage?phrase=%E6%98%A5%E5%A4%A9&graphicalStyle%5B0%5D=1&page=1');
这样就爬取到了第一页的数据 并且在本地创建了一个接口数据的txt文件 。
这样一个简单的接口数据就已经爬下来了,对于数据的处理就不多废话,各取所需。
本人qq : 981900309 加备注博客园
node.js爬取ajax接口数据的更多相关文章
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
- Node.js爬取豆瓣数据
一直自以为自己vue还可以,一直自以为webpack还可以,今天在慕课逛node的时候,才发现,自己还差的很远.众所周知,vue-cli基于webpack,而webpack基于node,对node不了 ...
- node.js之用ajax获取数据和ejs获取数据
摘要:学了node之后有时候分不清前台和后台,今天用ajax和ejs来从后台获取数据,没有数据库,用json数据来进行模拟数据库:来区分前台和后台需要干什么? 一.用ejs获取数据 1.文件目录 2. ...
- 爬虫(十):AJAX、爬取AJAX数据
1. AJAX 1.1 什么是AJAX AJAX即“Asynchronous JavaScript And XML”(异步JavaScript和XML)可以使网页实现异步更新,就是不重新加载整个网页的 ...
- node 爬虫 --- 将爬取到的数据,保存到 mysql 数据库中
步骤一:安装必要模块 (1)cheerio模块 ,一个类似jQuery的选择器模块,分析HTML利器. (2)request模块,让http请求变的更加简单 (3)mysql模块,node连接mysq ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 十三 web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多网站,当你浏览器访问时看到的信息,在html源文件里却找不到,由得信息还是滚动条滚动到对应的位置后才显示信息, ...
- Node.js 抓取电影天堂新上电影节目单及ftp链接
代码地址如下:http://www.demodashi.com/demo/12368.html 1 概述 本实例主要使用Node.js去抓取电影的节目单,方便大家使用下载. 2 node packag ...
- C#使用phantomjs,爬取AJAX加载完成之后的页面
1.开发思路:入参根据apiSetting配置文件,分配静态文件存储地址,可实现不同站点的静态页生成功能.静态页生成功能使用无头浏览器生成,生成之后的字符串进行正则替换为固定地址,实现本地正常访问. ...
随机推荐
- 【原创】Java基础之Session机制
Session机制 JSESSIONID是Session的标识,当客户端请求服务器端的时候,服务器端会检查是否已经给这个客户端创建过Session,也就是看客户端的请求中的header是否有Cooki ...
- activiti 涉及的内容
1 JAVA 委派模式(Delegate) https://blog.csdn.net/mayaofr/article/details/52082665 2 Activiti中的activiti:ex ...
- 通过mysqlbinlog 恢复数据
前提数据库开启了bin_log记录日志. 查看日志 刷新日志 flush logs; 再次查看 show binary logs; 向表中插入一条数据 现在执行delete误操作,删除所有的数据. d ...
- python下的异常处理
一.什么是异常 程序运行过程中错误发生的信号.(如果运行时产生的异常,程序不处理就会被抛出,随之会造成程序终止) 二.异常的种类 首先,异常主要分为语法错误.逻辑错误两种类型 语法错误会在程序还没有执 ...
- Java的家庭记账本程序(H) :微信小程序 image 标签,在模拟器中无法显示图片?(已解决)
日期:2019.2.25 博客期:036 星期一 吼!今天我还是继续研究了自己的微信小程序,还没有连接数据库,只是在xml的设计上添加了不少东西,大家可以看我的截图,嗯~说到今天的收获,就是 marg ...
- VMware安装CentOS7系统
- LVS原理详解(3种工作方式8种调度算法)--老男孩
一.LVS原理详解(4种工作方式8种调度算法) 集群简介 集群就是一组独立的计算机,协同工作,对外提供服务.对客户端来说像是一台服务器提供服务. LVS在企业架构中的位置: 以上的架构只是众多企业里面 ...
- 寻找符合条件的最短子字符串——SLIDING WINDOW
简介 用一个可伸缩的窗口遍历字符串,时间复杂度大致为O(n).适用于“寻找符合某条件的最小子字符串”题型. 题目 链接 求某字符串T中含有某字符串S的所有字符的最小子字符串.如果不存在则返回" ...
- [原创]基于Zynq Linux环境搭建(四)
此篇编译根文件系统 下载busybox和dropbear, [#73#13:04:52 FPGADeveloper@ubuntu ~/Zybo_Demo/XilinxFS]$wget --no-che ...
- CF121E Lucky Array
题解: 这个题好像暴力+线段树就能过 就是对修改操作暴力,线段树维护查询 为啥呢 因为保证了数$<=1e4$,于是这样复杂度$n*1e4=1e9$ 那么特殊数只有30个 又因为操作是只加不减的, ...