A Diversity-Promoting Objective Function for Neural Conversation Models论文阅读
本文来自李纪为博士的论文 A Diversity-Promoting Objective Function for Neural Conversation Models
1,概述
对于seq2seq模型类的对话系统,无论输入是什么,都倾向于生成安全,通用的回复(例如 i don't know 这一类的回复),因为这种响应更符合语法规则,在训练集中出现频率也较高,最终生成的概率也最大,而有意义的响应生成概率往往比他们小。如下表所示:

上面的表中是seq2seq对话系统产生的结果,分数最高的回复通常是最常见的句子,当然更有意义的回复也会出现在N-best列表(beam search的结果)中,但一般分数相对更低一点。主要是一般seq2seq模型中的目标函数通常是最大似然函数,最大似然函数更倾向于训练集中频率更高的回复。
本论文提出使用MMI(最大互信息)来替换最大似然函数作为新的目标函数,目的是使用互信息减小“I don’t Know”这类无聊响应的生成概率。
2 MMI 模型
在原始的seq2seq模型中,使用的目标函数是最大似然函数,就是在给定输入S的情况下生成T的概率,其表达式如下:
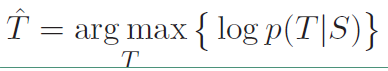
从这个表达式可以看到,实际上就是给定了源句子的情况下,选择概率最大的句子最为目标句子,这种情况下就会倾向于训练集中出现频率大的句子。
因此引入互信息作为新的目标函数,互信息的定义:度量两个时间集合之间的相关性。其表达式如下:
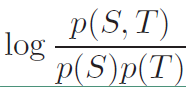
将上面的表达式可以改写成:
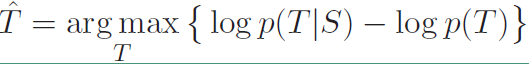
我们在上面的式子的基础上对第二项加上一个$\lambda$参数,表达式改写成:
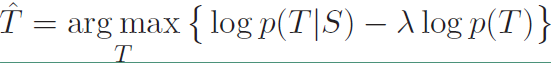
这就是本论文中提出的第一个目标函数MMI-antiLM,在其基础上添加了目标序列本身的概率$logp(T)$,$p(T)$就是一句话存在的概率,也就是一个模型,前面的$\lambda$是惩罚因子,越大说明对语言模型惩罚力度越大。由于这里用的是减号,所以相当于在原本的目标上减去语言模型的概率,也就降低了“I don’t know”这类高频句子的出现概率。
然后还提出了第二个目标函数MMI-bidi,在原始目标函数基础上添加$logp(S|T)$,也就是$T$的基础上产生$S$的概率,其具体表达式如下:
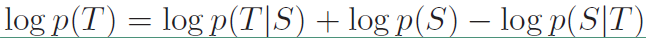
而且可以通过改变$\lambda$的大小衡量二者的重要性,其表达式变为:
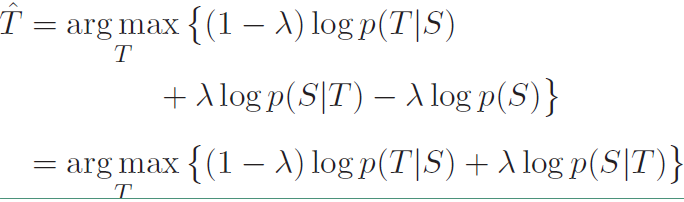
$logp(S|T)$可以表示在响应输入模型时产生输入的概率,自然像“I don’t know”这种答案的概率会比较低,而这里使用的是相加,所以会降低这种相应的概率。
接下来我们来详细的看看这两个目标函数
1)MMI-antiLM
如上所说,MMI-antiLM模型使用第一个目标函数,引入了$logp(T)$,但该方法同时也存在一个问题:模型倾向于生成生成不符合语言模型的相应。按理说$\lambda$取值小于1的时候,不应该出现这样的问题,所以在实际使用过程中需要对其进行修正。由于解码过程中往往第一个单词或者前面几个单词是根据encode向量选择的,后面的单词更倾向于根据前面decode的单词和语言模型选择,而encode的信息影响较小。也就是说我们只需要对前面几个单词进行惩罚,后面的单词直接根据语言模型选择即可,这样就不会使整个句子不符合语言模型了。使用下式中的$U(T)$代替$p(T)$,式中$g(k)$表示要惩罚的句子长度,其中$p(T)$如下
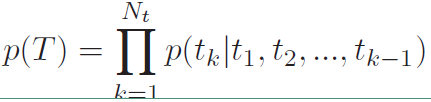
$U(T)$的表达式如下:
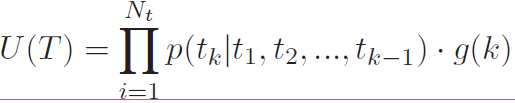
引入一个$\gamma$参数来对序列进行截断,是的$g(k)$的表达式如下:
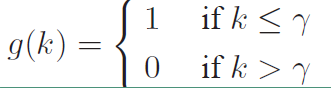
而最终的目标函数如下:

此外,此外实际使用中还加入了响应句子的长度这个因素,也作为模型相应的依据,所以将上面的目标函数修正为下式:

2)MMI-bidi
MMI-bidi模型也面临一个问题就是$(1-{\lambda})logp(T|S) + {\lambda}logp(S|T)$是一个很难求解的问题。要求得$p(S|T)$项,这就需要先计算出完整的$T$序列再将其传入一个提前训练好的反向seq2seq模型中计算该项的值。但是考虑到$S$序列会产生无数个可能的$T$序列,我们不可能将每一个$T$都进行计算,所以这里引入beam-search只计算前200个序列$T$来代替。然后使用式子的第二项对N-best列表重新排序,因为由标准seq2seq模型生成的N-best列表中的候选语句通常是语法正确的,所以从这N个解中最终选择的回复通常也是语法正确的。
然而,重排序有一个明显的缺陷就是,由于优先强调标准seq2seq的目标函数会导致非全局最优回复的产生,而且,很大程度上依赖系统成功生成足够多样的N个最优回复,也就是要求N足够大。然而标准seq2seq模型测试(解码)过程中的beam search存在一个问题导致重排序并不可用:搜索结果中缺乏多样性。因为在搜索结果里的备选回复之间通常只是标点符号或句子形态上较小的改变,大多数词语是重叠的。所以由于N-best列表中缺乏多样性的原因,会使得重排序也没什么效果。所以为了解决这类问题,需要为重排序提供一个更加多样化的N-best列表。
因此作者提出了一种新的beam search的方法,我们通过一张图来看这两种beam search:
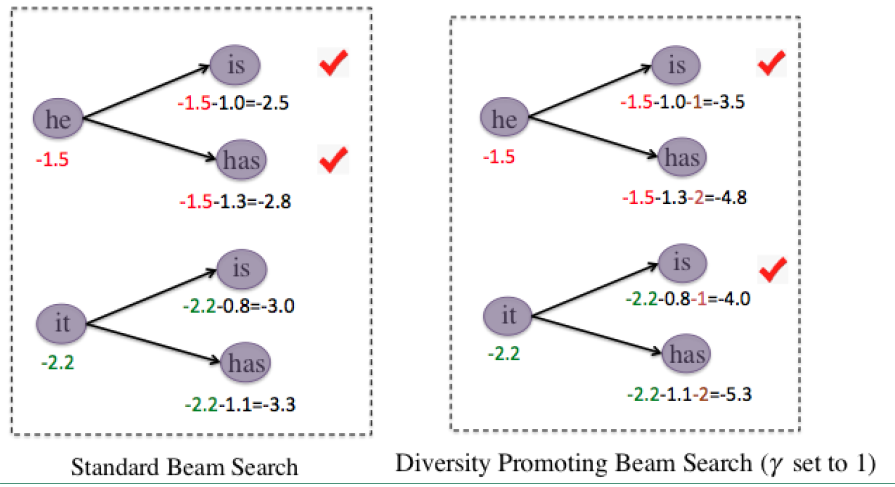
具体的做法就如上图所示,在beam search中是不管父节点的,而是将所有的子节点混在一起进行排序选择,而在改版的beam search中,先对同一父节点下的子节点排序,然后对排序后的子节点进行进行不同的惩罚,如图中对排前面的减1,排后面的减2,做完惩罚处理后,再将所有的子节点混合在一起进行排序选择。这样的beam search会增加N-best列表的多样性。
另外在MMI-bidi也做了和MMI-antiLM中同样的处理,增加了回复长度的影响。
A Diversity-Promoting Objective Function for Neural Conversation Models论文阅读的更多相关文章
- 机器学习 损失函数(Loss/Error Function)、代价函数(Cost Function)和目标函数(Objective function)
损失函数(Loss/Error Function): 计算单个训练集的误差,例如:欧氏距离,交叉熵,对比损失,合页损失 代价函数(Cost Function): 计算整个训练集所有损失之和的平均值 至 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- 【论文阅读】Learning Dual Convolutional Neural Networks for Low-Level Vision
论文阅读([CVPR2018]Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision) 本文针对低 ...
- Empirical Analysis of Beam Search Performance Degradation in Neural Sequence Models
Empirical Analysis of Beam Search Performance Degradation in Neural Sequence Models 2019-06-13 10:2 ...
- 《Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks》论文笔记
论文题目<Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Ne ...
- 《A Knowledge-Grounded Neural Conversation Model》
abstract 现在的大多数模型都可以被应用在闲聊场景下,但是还没有证据表明他们可以应用在更有用的对话场景下.这篇论文提出了一个知识驱动的,带有背景知识的神经网络对话系统,目的是为了在对话中产生更有 ...
- 吴恩达机器学习笔记29-神经网络的代价函数(Cost Function of Neural Networks)
假设神经网络的训练样本有
- [Scikit-learn] 1.1 Generalized Linear Models - Neural network models
本章涉及到的若干知识点(红字):本章节是作为通往Tensorflow的前奏! 链接:https://www.zhihu.com/question/27823925/answer/38460833 首先 ...
- 2018-ECCV-PNAS-Progressive Neural Architecture Search-论文阅读
PNAS 2018-ECCV-Progressive Neural Architecture Search Johns Hopkins University(霍普金斯大学) && Go ...
随机推荐
- postgres的使用命令
1.更新源 yum install https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7-x86_64/pgdg-centos1 ...
- 二维前缀和模板题:P2004 领地选择
思路:就是使用二维前缀和的模板: 先放模板: #include<iostream> using namespace std; #define ll long long ; ll a[max ...
- Git分布式版本控制器安装注意点及其常用命令
将git按照默认选项下载安装后,打开git bach版面进行git命令行操作(记住在安装的过程中文件夹中不能存在中文):注:Windows下,路径名不要包含中文,因为Git对中文支持不给力,可能会存在 ...
- PHP全栈学习笔记2
php概述 什么是php,PHP语言的优势,PHP5的新特性,PHP的发展趋势,PHP的应用领域. PHP是超文本预处理器,是一种服务器端,跨平台,HTML嵌入式的脚本语言,具有c语言,Java语言, ...
- .NET Core微服务之基于Ocelot+Butterfly实现分布式追踪
Tip: 此篇已加入.NET Core微服务基础系列文章索引 一.什么是Tracing? 微服务的特点决定了功能模块的部署是分布式的,以往在单应用环境下,所有的业务都在同一个服务器上,如果服务器出现错 ...
- .NET Core微服务之ASP.NET Core on Docker
Tip: 此篇已加入.NET Core微服务基础系列文章索引 一.Docker极简介绍 1.1 总体介绍 Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从Apache2.0协议开源.D ...
- 高效并发unsafe-星耀
定义 Unsafe类是在sun.misc包下,不属于Java标准.但是很多Java的基础类库,包括一些被广泛使用的高性能开发库都是基于Unsafe类开发的,比如Netty.Cassandra.Hado ...
- 全文检索-Elasticsearch (三) DSL
DSL:elasticsearch查询语言elasticsearch对json 的语法有严格的要求,每个json串不能换行,同时一个json串和一个json串之间,必须有一个换行 DSL(介绍查询语言 ...
- WebApiClient百度地图服务接口实践
1. 文章目的 随着WebApiClient的不断完善,越来越多开发者选择WebApiClient替换原生的HttpClient,然而在应用到实际项目中多多少少会遇到一些项目结合上的疑问和困难,本文将 ...
- kubernetes系列12—二个特色的存储卷configmap和secret
本文收录在容器技术学习系列文章总目录 1.configmap 1.1 认识configmap ConfigMap用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件.ConfigMa ...