深度学习中Xavier初始化
“Xavier”初始化方法是一种很有效的神经网络初始化方法,方法来源于2010年的一篇论文《Understanding the difficulty of training deep feedforward neural networks》。
文章主要的目标就是使得每一层输出的方差应该尽量相等。下面进行推导:每一层的权重应该满足哪种条件才能实现这个目标。
我们将用到以下和方差相关的定理:
假设有随机变量x和w,它们都服从均值为0,方差为σ的分布,且独立同分布,那么:
• w*x就会服从均值为0,方差为σ*σ的分布
• w*x+w*x就会服从均值为0,方差为2*σ*σ的分布
文章实验用的激活函数是tanh激活函数,函数形状如下左图,右图是其导数的函数形状。

从上图可以看出,当x处于0附近时,其导数/斜率接近与1,可以近似将其看成一个线性函数,即f(x)=x。
我们假设所有的输入数据x满足均值为0,方差为 的分布,我们再将参数w以均值为0,方差为的方式进行初始化。我们假设第一层是卷积层,卷积层共有n个参数(n=channel*kernel_h*kernel_w),于是为了计算出一个线性部分的结果,我们有:
的分布,我们再将参数w以均值为0,方差为的方式进行初始化。我们假设第一层是卷积层,卷积层共有n个参数(n=channel*kernel_h*kernel_w),于是为了计算出一个线性部分的结果,我们有:
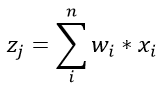
其中,忽略偏置b。
假设输入x和权重w独立同分布,我们可以得出z服从均值为0,方差为 的分布,即
的分布,即
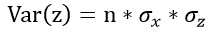
为了更好地表达,我们将层号写在变量的上标处,
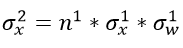
我们将卷积层和全连接层统一考虑成n个参数的一层,于是接着就有:
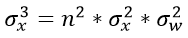
如果我们是一个k层的网络(这里主要值卷积层+全连接层的总和数),我们就有

继续展开,最终可以得到
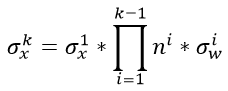
从上式可以看出,后面的连乘是非常危险的,假如说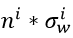 总是大于1,那么随着层数越深,数值的方差会越来越大;如果乘积小于1,那么随着层数越深,数值的方差会越来越小。
总是大于1,那么随着层数越深,数值的方差会越来越大;如果乘积小于1,那么随着层数越深,数值的方差会越来越小。
我们再回头看看这个公式,
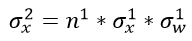
如果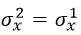 ,那么我们就能保证每层输入与输出的方差保持一致,那么应该满足:
,那么我们就能保证每层输入与输出的方差保持一致,那么应该满足:
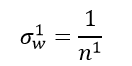
即对应任意第i层,要想保证输入与输出的方差保持一致,需要满足:
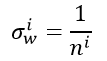
------------------------------------------------------------------------------------------------
上面介绍的是前向传播的情况,那么对于反向传播,道理是一样的。
假设我们还是一个k层的网络,现在我们得到了第k层的梯度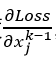 ,那么对于第k-1层输入的梯度,有
,那么对于第k-1层输入的梯度,有
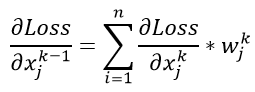
从上式可以看出K-1层一个数值的梯度,相当于上一层的n个参数的乘加。这个n个参数的计算方式和之前方式一样,只是表示了输出端的数据维度,在此先不去赘述了。
于是我们假设每一层的参数服从均值为0,方差为某值的分布,那么有如下公式:
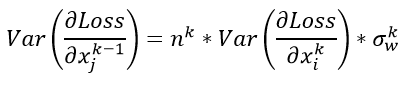
对于这个k层网络,我们又可以推导出一个的公式:
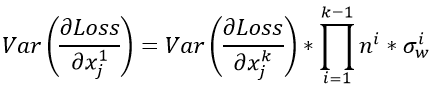
上式中连乘是非常危险的,前面说过,在此不在赘述(这就会造成梯度爆炸与梯度消失的问题,梯度爆炸与梯度消失可以参考这两篇文章)。我们想要做到数值稳定,使得反向传播前后的数值服从一个稳定的分布,即

那么需要满足如下条件:
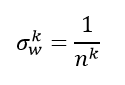
-----------------------------------------------------------------
如果仔细看一下前向传播与反向传播的两个公式,我们就会发现两个n实际上不是同一个n。对于全连接来说,前向操作时,n表示了输入的维度,而后向操作时,n表示了输出的维度。而输出的维度也可以等于下一层的输入维度。所以两个公式实际上可以写作:
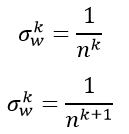
于是为了均衡考量,最终我们的权重方差应满足:
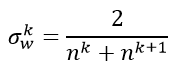
下面就是对这个方差的具体使用了。论文提出使用均匀分布进行初始化,我们设定权重要初始化的范围是[-a,a]。而均匀分布的方差为:
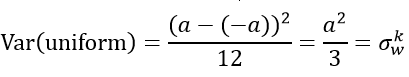
由此可以求得
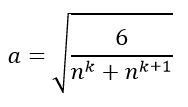
上面就是xavier初始化方法,即把参数初始化成下面范围内的均匀分布。
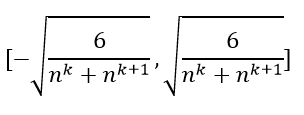
转载自:
CNN数值——xavier(上):https://zhuanlan.zhihu.com/p/22028079
CNN数值——xavier(下): https://zhuanlan.zhihu.com/p/22044472
深度学习——Xavier初始化方法:https://blog.csdn.net/shuzfan/article/details/51338178
深度学习中Xavier初始化的更多相关文章
- 深度学习的Xavier初始化方法
在tensorflow中,有一个初始化函数:tf.contrib.layers.variance_scaling_initializer.Tensorflow 官网的介绍为: variance_sca ...
- 深度学习中常见的 Normlization 及权重初始化相关知识(原理及公式推导)
Batch Normlization(BN) 为什么要进行 BN 防止深度神经网络,每一层得参数更新会导致上层的输入数据发生变化,通过层层叠加,高层的输入分布变化会十分剧烈,这就使得高层需要不断去重新 ...
- 深度学习中优化【Normalization】
深度学习中优化操作: dropout l1, l2正则化 momentum normalization 1.为什么Normalization? 深度神经网络模型的训练为什么会很困难?其中一个重 ...
- 深度学习中dropout策略的理解
现在有空整理一下关于深度学习中怎么加入dropout方法来防止测试过程的过拟合现象. 首先了解一下dropout的实现原理: 这些理论的解释在百度上有很多.... 这里重点记录一下怎么实现这一技术 参 ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
- zz详解深度学习中的Normalization,BN/LN/WN
详解深度学习中的Normalization,BN/LN/WN 讲得是相当之透彻清晰了 深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Ba ...
- 模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用
模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理.分类及应用 lqfarmer 深度学习研究员.欢迎扫描头像二维码,获取更多精彩内容. 946 人赞同了该文章 Atte ...
- 深度学习中的Data Augmentation方法(转)基于keras
在深度学习中,当数据量不够大时候,常常采用下面4中方法: 1. 人工增加训练集的大小. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.也就是Data Augm ...
随机推荐
- Maven-07: 插件的自定义绑定
除了内置绑定以外,用户还能够自己选择将某个插件目标绑定到生命周期的某个阶段上,这种自定义绑定方式能让Maven项目在构建过程中执行更多更富特色的任务. 一个常见的例子是创建项目的源码jar包.内置的插 ...
- Mycat 配置说明(server.xml)
server.xml 几乎保存了所有mycat需要的系统配置信息,包括 mycat 用户管理.DML权限管理等,其在代码内直接的映射类为SystemConfig 类. user 标签 该标签主要用于定 ...
- 依赖layui form模块 复选框tree插件(拓展可根据属性单选还是多选,数据反选)
近些天接的项目用的是layui.以前没用过,踩了很多坑,坑就不多说了,直接说layui的tree.因为自带的tree不满足需求,所以在论坛.博客上找了很久终于找到了可以复选的的插件,原文地址:http ...
- [SDOI2011]染色
[SDOI2011]染色 题目描述 输入输出格式 输出格式: 对于每个询问操作,输出一行答案. 解法 ps:这题本来是树剖的,但我用lct写的,以下是lct的写法,树剖会有所不同 我们考虑把不同色点的 ...
- 解决C盘中的文件不能修改问题
在不能修改的文件右击属性>点击安全>编辑>点击用户>完全控制. 步骤如图: 最后点击确定.
- 『练手』手写一个独立Json算法 JsonHelper
背景: > 一直使用 Newtonsoft.Json.dll 也算挺稳定的. > 但这个框架也挺闹心的: > 1.影响编译失败:https://www.cnblogs.com/zih ...
- bug终结者 团队作业第八周
bug终结者 团队作业第八周 本次任务 素材提供及编辑:20162328 蔡文琛 博客修改完善:20162322 朱娅霖 "bug终结者" 宏伟蓝图 UML 手绘底稿 用例图 选项 ...
- 201621123068 作业07-Java GUI编程
1. 本周学习总结 1.1 思维导图:Java图形界面总结 2.书面作业 1. GUI中的事件处理 1.1 写出事件处理模型中最重要的几个关键词. 注册.事件.事件源.监听 1.2 任意编写事件处理相 ...
- vim配置强悍来袭
vim 这个关键字,我不想再过多的解释,相信看到这里的同仁,对vim都有十七八分的理解,如果你还不知道vim是什么,自己找个黑屋子... 废话不多说,今天在这里主要说vim的,不带插件的配置,也就 ...
- xcode修改代码目录结构出现clang:error:nosuchfileordirectory解决方法
需要迁移一个开源工程的一部分内容到自己工程,迁移对方的工程到自己工程之后,因目录结构配置整理需要,对嵌入的工程目录进行了结构改变,编译后出现: clang: error: no such file o ...