Elastic Stack-Elasticsearch使用介绍(五)
一、前言
前4篇将Elasticsearch用法的API和原理方面东西介绍了一下,相信大家对Elasticsearch有了一定的认知,接下我们主要从索引的建立到后期的一些优化做一些介绍;
二、Mapping构建
之前介绍过Index就如同我们的数据库database,type相当于我们的表,而Mapping就是构建这些字段和索引关系的桥梁。数据库构建的时候我们要遵守三范式,那Mapping构建的时候我们要考虑那些因素?我认为要有以下几方面的考虑:
1.字段是什么类型;
对字段的类型做过介绍,考虑这个时候和数据库字段设置考虑问题基本一样;
2.是否需要被检索,也就是是否需要分词;
不需要检索的字段:index设置为false;不需要检索的字符类型直接设置成keyword类型;
需要检索的字段,可以通过index_options设定需要的存储分词的粒度,主要有以下四种参数docs 、 freqs 、 position 、 offsets,根据需要自行设定;
3.是否需要排序和聚合;
不需要排序或者聚合分析功能:doc_values设置为 false,fielddata设置为 false;
如果一个字段不需要检索、排序、聚合分析,则enabled设置为false;
4.是否需要另外的存储;
通过store 设定 true,即可存储该字段的原始内容,这里这个举个例子

以上就是我们建立Mapping时候需要考虑一些东西,接下来我们还有另外一个问题,数据库中表与表之间是有关联关系的,这个在Elasticsearch中是如何体现的?
在Elasticsearch中有两种方式可以去实现关联关系,
1.Nested Object(嵌套对象)
举个例子:

这个时候user字段会被映射成为object类型,这个时候JSON文档会被处理成为:

当我们查询的时候,就会意外出现的结果;

结果:

Elasticsearch针对这种情况提供Nested Object(嵌套对象)这个解决方案,
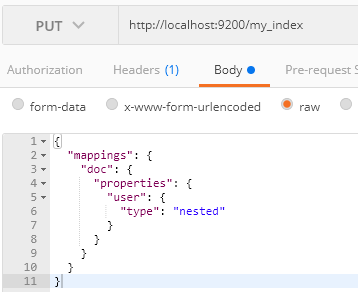
增加这一个步骤然后再按照上面步骤操作,就得到我们想要的结果;

当使用Nested Object内部是使用嵌套文档,当搜索first name为Alice和last name为White的时候就查询不到;
2.join
join数据类型是在同一个索引通过Parent和Child去指定父文档和子文档,然后形成1对多或者1对1的关系,举个例子:
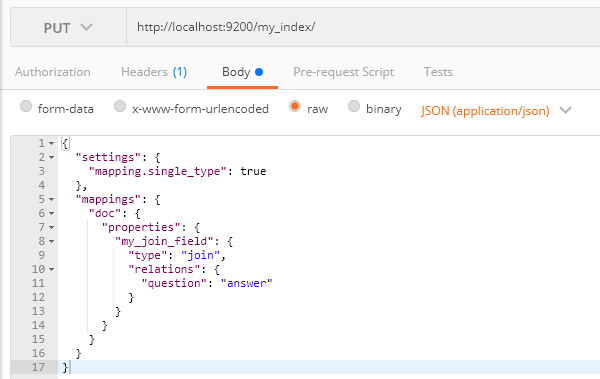
我这个是5.0以上的版本,不是6.0的版本,这个我还是忘记说,大家注意下版本问题,我大概说下这个意思就是只指定my_join_field字段question的父级为answer;
接下来我们再加入2条父级文档:
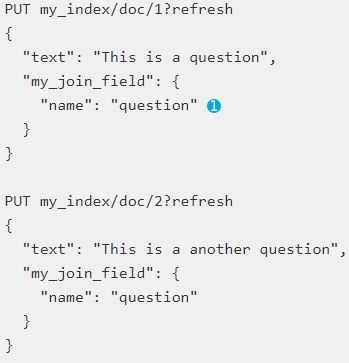
接下来在加入2条子文档:

这里需要注意的问题是路由必须要指定,父级文档必须和自己文档在同一个分片上,另外就是指定join的文档和父id;
这个时候我们查看下我们形成的文档:
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"skipped": ,
"failed":
},
"hits": {
"total": ,
"max_score": null,
"hits": [
{
"_index": "my_index",
"_type": "doc",
"_id": "",
"_score": null,
"_source": {
"text": "This is a question",
"my_join_field": {
"name": "question"
}
},
"sort": [
""
]
},
{
"_index": "my_index",
"_type": "doc",
"_id": "",
"_score": null,
"_source": {
"text": "This is a another question",
"my_join_field": {
"name": "question"
}
},
"sort": [
""
]
},
{
"_index": "my_index",
"_type": "doc",
"_id": "",
"_score": null,
"_routing": "",
"_source": {
"text": "This is an answer",
"my_join_field": {
"name": "answer",
"parent": ""
}
},
"sort": [
""
]
},
{
"_index": "my_index",
"_type": "doc",
"_id": "",
"_score": null,
"_routing": "",
"_source": {
"text": "This is another answer",
"my_join_field": {
"name": "answer",
"parent": ""
}
},
"sort": [
""
]
}
]
}
}
看到结果我们就可以知道我们的1对多关系已经建立起来了,接下来我们按照父id来查询父id为1的文档:

这个地方还要提醒下,也是可以使用get的,只是使用神器的时候这样比较方便;
结果如下:

还可以使用has_child 返回包含某子文档的父文档,has_parent 返回包含某父文档的子文档这些就不写例子自己探索一下吧;
接下来做个对比:
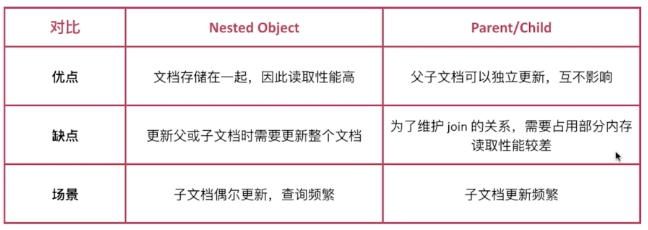
注意:Mapping字段不要设置太多;
三、部分优化的意见
elasticsearch.yml中建议设定的参数:
之前集群搭建的时候大家肯定设置一些参数,另外上面你的介绍也设置了一些参数,我们也具体来说下在上生产环境之前到底要设置那些参数:
1.cluster.name集群名称;
2.node.name节点名称;
3.node.master是否是主节点;
4.node.data是否存放数据,主节点不建议存放数据;
5.discovery.zen.ping.unicast.hosts设置集群的其他节点;
6.network.host IP;
7.path.data and path.logs 存放记录和日志的目录,默认是在Elasticsearch目录下;
8.discovery.zen.minimum_master_nodes 集群挂掉以后选举主的个数;
JVM设置:
1.将最小堆大小(Xms)和最大堆大小(Xmx)设置为彼此相等,防止垃圾回收过于频繁;
2.将Xmx设置为不超过物理RAM的50%,以确保有足够的物理RAM用于内核文件系统缓存;
3.不要超过32GB,这是JVM优化的建议;
分片的设置:
建议阅读这篇文章;
读写优化:
写入的优化,这个参考下Elastic Stack-Elasticsearch使用介绍(三)这篇文章,这篇文章我介绍写入时候的一些步骤,我们优化的方向就是从这3个方向:
当然要贯彻多线程、批量写入这个不能变得方针,针对refresh、translog、flush这3个方面做优化:
1.refresh
每refresh一次都会生成一个segment,如果refresh频率过高,可能会照成segment包含的文档数是很少,生成很多的segment;
调整方向
增大refresh_interval,降低实时性,默认是1s,设置为-1直接禁止自动refresh;
增大缓存区的大小,参数为indices.memory.index_buffer_size(静态参数,在elasticsearch.yml中设定,该参数设置后必须重启节点),默认为10%;
2.translog
目标是降低translog写磁盘的频率,从而提高效率,但是这样就会有掉丢数据的风险;
调整方向
index.translog.durabiliy设置为asyn,index.translog.sync_interval设置写入时间的间隔,单位是秒,比如10s,那么translog会改为每10s写一次磁盘,这个时候如果宕机就会丢失数据;
index.translog.flush_threshold_size 默认为512MB,超过该大小时会触发一次flush;
3.合理设置节点和分片的个数,通过设置index.routing.allocation.total_shards_per_node 限定每个索引在每个节点上可分配的总主副分片的个数;
读取的优化:
1.合理设置分片数
通过测试一个分片性能,然后根据业务进行计算,设置合理的分片个数;怎么测试一个分片的性能?首先搭建与生产一样的环境,接下来设定一个单分片无副本的索引,然后进行写入数据测试 和查询数据,然后根据提供的监控指标进行监控压力测试的情况,这部分监控内容下一章进行讲解;压测工具可以使用esrally,参考下这篇文章;
2.优化查询语句
尽量使用Filter上下文,减少算分的场景,由于Filter有缓存机制,可以提升查询性能;
四、结束
接下来会开始说一说监控的问题,欢迎大家加群438836709,欢迎大家关注我公众号!

Elastic Stack-Elasticsearch使用介绍(五)的更多相关文章
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- Elastic Stack核心产品介绍-Elasticsearch、Logstash和Kibana
Elastic Stack 是一系列开源产品的合集,包括 Elasticsearch.Kibana.Logstash 以及 Beats 等等,能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地 ...
- ES 集中式日志分析平台 Elastic Stack(介绍)
一.ELK 介绍 ELK 构建在开源基础之上,让您能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地对数据进行搜索.分析和可视化. 最近查看 ELK 官方网站,发现新一代的日志采集器 File ...
- 集中式日志分析平台 Elastic Stack(介绍)
一.ELK 介绍 二.ELK的几种常见架构 >>ELK 介绍<< ELK 构建在开源基础之上,让您能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地对数据进行搜索.分析 ...
- Elastic Stack(ElasticSearch 、 Kibana 和 Logstash) 实现日志的自动采集、搜索和分析
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash(也称为 ELK Stack).能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据 ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- 浅尝 Elastic Stack (一) Elasticsearch、Kibana、Beats 安装
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash,也称为 ELK Stack.能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据进 ...
- ELK stack elasticsearch/logstash/kibana 关系和介绍
ELK stack elasticsearch 后续简称ES logstack 简称LS kibana 简称K 日志分析利器 elasticsearch 是索引集群系统 logstash 是日志归集集 ...
- Elastic Stack 笔记(四)Elasticsearch5.6 索引及文档管理
博客地址:http://www.moonxy.com 一.前言 在 Elasticsearch 中,对文档进行索引等操作时,既可以通过 RESTful 接口进行操作,也可以通过 Java 也可以通过 ...
随机推荐
- java常用工具(jps等)说明
Java为我们提供了大量的工具辅助我们进行开发,位于jdk目录下的bin目录里,本篇博客将会随时更新相关工具的使用说明. jps 获取当前运行的java应用 lgj@lgj-Lenovo-G470:~ ...
- vue项目向小程序迁移调研
概述 今天调研了一下vue项目怎么向小程序迁移,有些心得,记录下来,供以后开发时参考,相信对其他人也有用. 基本上vue项目向小程序迁移不外乎2种方法,一种是用小程序的web-view组件,另一种是用 ...
- python中的2、8、16、10进制之间的转换
python除法的坑 众所周知,python除法有两个运算符,一个是/,还有一个是//,那么这两个有什么不同之处呢? 从图片可以得知,使用//返回一个float类型,而使用/返回一个int类型.我们总 ...
- css两列布局之基于BFC规则实现
css要实现常见的自适应两列布局的方式方法挺多. 这里讲的是利用设置overflow不为visible时会形成新的BFC来实现.至于什么是BFC,可以搜搜看先,基本都讲的差不多了.等有更多空余时间,专 ...
- 从壹开始前后端分离 [ Vue2.0+.NET Core2.1] 二十一║Vue实战:开发环境搭建【详细版】
缘起 哈喽大家好,兜兜转转终于来到了Vue实战环节,前边的 6 篇关于Vue基础文章我刚刚简单看了看,感觉写的还是不行呀,不是很系统,所以大家可能看上去比较累,还是得抽时间去润润色,修改修改语句和样式 ...
- 基于“formData批量上传的多种实现” 的多图片预览、上传的多种实现
前言 图片上传是web项目常见的需求,我基于之前的博客的代码(请戳:formData批量上传的多种实现)里的第三种方法实现多图片的预览.上传,并且支持三种方式添加图片到上传列表:选择图片.复制粘贴图片 ...
- EF获取多个数据集以及MySQL分页数据查询优化
背景:MySQL分页查询语句为 ,10; 一般页面还会获取总条数,这时候还需要一条查询总条数语句 , 这样数据库需要执行两次查询操作.MySQL提供了SQL_CALC_FOUND_ROWS追踪总条数的 ...
- JavaScript是如何工作的:引擎,运行时和调用堆栈的概述!
摘要: 理解JS执行原理. 原文:JavaScript是如何工作的:引擎,运行时和调用堆栈的概述! 作者:前端小智 Fundebug经授权转载,版权归原作者所有. 本文是旨在深入研究JavaScrip ...
- 自动化测试 Appium之Python运行环境搭建 Part2
Appium之Python运行环境搭建 Part2 by:授客 QQ:1033553122 实践环境 参见 Appium之Python运行环境搭建 Part1 环境部署 1.安装Android SDK ...
- Android为TV端助力:UDP协议(接收组播和单播)
private static String MulticastHost="224.9.9.98";private static int POST=19999;private sta ...