python3 爬取qq音乐作者所有单曲 并且下载歌曲
1 import requests
import re
import json
import os # 便于存放作者的姓名
zuozhe = [] headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'} def get_singermid():
name = input('请输入你要下载歌曲的作者:')
zuozhe.append(name)
if not os.path.exists(name):
os.mkdir(name)
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'}
data = {
'w': name,
'jsonpCallback': 'MusicJsonCallback885332333726736',}
response = requests.get(url,headers=headers,params=data).text
patt = re.compile('MusicJsonCallback\d+\((.*?)\}\)')
singermid = re.findall(patt,response)[0]
singermid = singermid+'}'
dic = json.loads(singermid)
return dic['data']['song']['list'][0]['singer'][0]['mid'] def get_page_html(singermid):
url = 'https://c.y.qq.com/v8/fcg-bin/fcg_v8_singer_track_cp.fcg'
params = {
'g_tk': 5381,
'jsonpCallback': 'MusicJsonCallbacksinger_track',
'loginUin': 0,
'hostUin': 0,
'format': 'jsonp',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': 0,
'platform': 'yqq',
'needNewCode': 0,
'singermid': singermid,
'order': 'listen',
'begin': 0,# 页数 0 30 60
'num': 30,
'songstatus': 1,
}
response = requests.get(url,headers=headers,params=params)
return response.text def get_vkey_data(songmid,strMediaMid,name):
url = 'https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg'
strMediaMid1 = 'C400'+strMediaMid+'.m4a'
data = {
'g_tk': 5381,
'jsonpCallback': "MusicJsonCallback4327043425715609",
'loginUin': 0,
'hostUin': 0,
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': 0,
'platform': 'yqq',
'needNewCode': 0,
'cid': 205361747,
'callback': 'MusicJsonCallback4327043425715609',
'uin': 0,
'songmid': songmid,
'filename': strMediaMid1,
'guid': 4428680404,
}
response = requests.get(url,headers=headers,params=data).text
try:
patt = re.compile('\"vkey\":\"(.*?)\"')
vkey = re.findall(patt,response)[0]
patt = re.compile('\"filename\":\"(.*?)\"')
filename = re.findall(patt, response)[0]
url1 = 'http://dl.stream.qqmusic.qq.com/' + filename + '?vkey=' + vkey + '&guid=4428680404&uin=0&fromtag=66'
yingyue = requests.get(url1,headers=headers).content
with open(zuozhe[0]+'/'+name+'.m4a','wb') as f:
f.write(yingyue)
f.close()
print('下载完成《'+name+'》')
except Exception as e:
print(e)
pass def get_detail_html(html):
if html:
patt = re.compile('data\":{\"list\":(.*?),\"singer_id',re.S)
json_html = re.findall(patt,html)[0]
data_html = json.loads(json_html)
for data in data_html:
name = data['musicData']['songname']
songmid = data['musicData']['songmid']
strMediaMid = data['musicData']['strMediaMid']
print('正在下载《' + name + '》......')
get_vkey_data(songmid,strMediaMid,name) def main():
# 获取 singermid
singermid = get_singermid()
html = get_page_html(singermid)
get_detail_html(html) if __name__ == '__main__':
main()
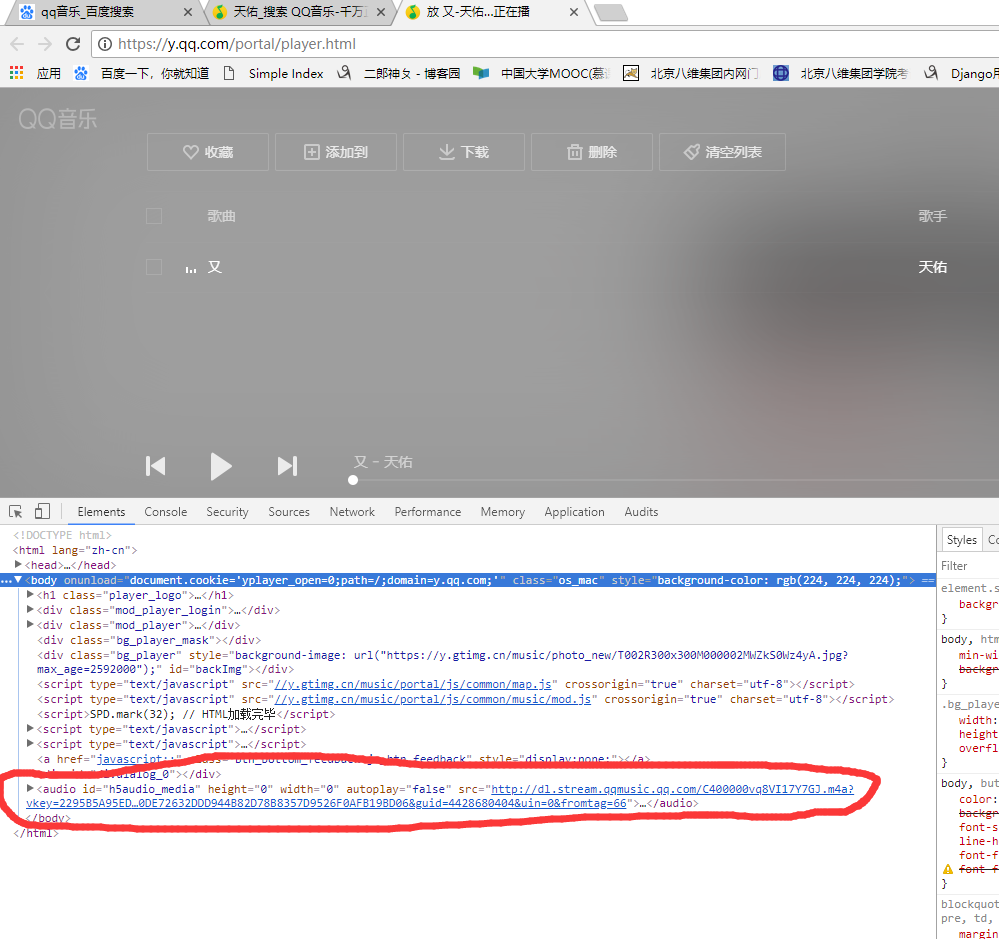

爬取qq音乐首先得找到'http://dl.stream.qqmusic.qq.com/' + filename + '?vkey=' + vkey + '&guid=4428680404&uin=0&fromtag=66'这个链接 然后其中只有filename 和vkey 在变化 然后就在列表页寻找这两个参数,找到以后拼接到这个url,然后请求就可以了 。
代码在上面只供参考
python3 可以直接复制然后运行
python3 爬取qq音乐作者所有单曲 并且下载歌曲的更多相关文章
- Python爬虫实战一之爬取QQ音乐
一.前言 前段时间尝试爬取了网易云音乐的歌曲,这次打算爬取QQ音乐的歌曲信息.网易云音乐歌曲列表是通过iframe展示的,可以借助Selenium获取到iframe的页面元素, 而QQ音乐采用的是 ...
- 爬取QQ音乐歌手的歌单
import requests# 引用requests库res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search ...
- 爬取QQ音乐(讲解爬虫思路)
一.问题描述: 本次爬取的对象是QQmusic,为自己后面做django音乐网站的开发获取一些资源. 二.问题分析: 由于QQmusic和网易音乐的方式差不多,都是讲歌曲信息放入到播放界面播放,在其他 ...
- python3爬取咪咕音乐榜信息(附源代码)
参照上一篇爬虫小猪短租的思路https://www.cnblogs.com/aby321/p/9946831.html,继续熟悉基础爬虫方法,本次爬取的是咪咕音乐的排名 咪咕音乐榜首页http://m ...
- 爬取qq音乐巅峰榜---内地音乐的榜单
import requestsimport jsonimport sys for i in range(0,10): url = "https://szc.y.qq.com/v8/fcg-b ...
- python3 爬去QQ音乐
import requests import re import json import os def get_name(singer): url = 'https://c.y.qq.com/soso ...
- 手把手教你使用Python抓取QQ音乐数据(第一弹)
[一.项目目标] 获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 由浅入深,层层递进,非常适合刚入门的同学练手. [二.需要的库] 主要涉及的库有:requests.json ...
- 手把手教你使用Python抓取QQ音乐数据(第二弹)
[一.项目目标] 通过Python爬取QQ音乐数据(一)我们实现了获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 此次我们在之前的基础上获取QQ音乐指定歌曲的歌词及前15个精 ...
- python3爬取全民K歌
Python3爬取全民k歌 环境 python3.5 + requests 1.通过歌曲主页链接爬取 首先打开歌曲主页,打开开发者工具(F12). 选择Network,点击播放,会发现有一个请求返回的 ...
随机推荐
- 开源库BaseRecyclerViewAdapterHelper
相信大家RecyclerView应该不会陌生,大多数开发者应该都使用上它了,它也是google推荐替换ListView的控件,但是用过它的同学应该都知道它在某些方面并没有ListView使用起来方便, ...
- mysql进阶(十九)SQL语句如何精准查找某一时间段的数据
SQL语句如何精准查找某一时间段的数据 在项目开发过程中,自己需要查询出一定时间段内的交易.故需要在sql查询语句中加入日期时间要素,sql语句如何实现? SELECT * FROM lmapp.lm ...
- java工具类(二)之java正则表达式表单验证
java正则表达式表单验证类工具类(验证邮箱.手机号码.qq号码等) 这篇文章主要介绍了java使用正则表达式进行表单验证工具类,可以验证邮箱.手机号码.qq号码等方法,需要的朋友可以参考下. jav ...
- 【一天一道LeetCode】#39. Combination Sum
一天一道LeetCode系列 (一)题目 Given a set of candidate numbers (C) and a target number (T), find all unique c ...
- "《算法导论》之‘字符串’":字符串匹配
本文主要叙述用于字符串匹配的KMP算法. 阮一峰的博文“字符串匹配的KMP算法"将该算法讲述得非常形象,可参考之. 字符串‘部分匹配值’计算 KMP算法重要的一步在于部分匹配值的计算.模仿& ...
- 《万能数据库查询分析器》实现使用SQL语句直接高效地访问文本文件
<万能数据库查询分析器>实现使用SQL语句直接高效地访问文本文件 马根峰 (广东联合电子服务股份有限公司, 广州 510300) 摘要 用SQL语句来直接访问文本文件?是在做梦吗? ...
- ubuntu 输入用户名密码又回到登陆界面
问题描述: 输入正确的用户名密码,登陆后又返回登陆界面,重复出现. 问题解决: 环境变量出错,重新配置环境变量. 1.进入命令行模式Ctrl+Alt+F*,然后输入用户名密码: 2.登进去之后,以管理 ...
- OVS 中的哈希表: shash
shash出现在OVS的代码中,定义如下: struct hmap_node { size_t hash; struct hmap_node * next; }; struct ...
- Cookie、sessionStorage、localStorage的区别
共同点:都是保存在浏览器端,且同源的.区别:cookie数据始终在同源的http请求中携带(即使不需要),即cookie在浏览器和服务器间来回传递.而sessionStorage和localStora ...
- C++——虚函数问题小集
学习C++ 不可避免地会遇到虚函数的问题,下面几个问题在学习初期或多或少会存在一些疑惑,所以便将其总结了下来. 1.为什么静态成员函数.构造函数不能定义为虚函数? 因为静态成员函数是一个大家共享的一个 ...