爬取QQ音乐(讲解爬虫思路)
一、问题描述:
本次爬取的对象是QQmusic,为自己后面做django音乐网站的开发获取一些资源。
二、问题分析:
由于QQmusic和网易音乐的方式差不多,都是讲歌曲信息放入到播放界面播放,在其他界面没有media的资源,喜马拉雅的则不是这样的,可以参考我爬取喜马拉雅的blog与代码:https://www.cnblogs.com/future-dream/p/10347354.html。
1.由于上述原因,我们需要对网页进行分析:
获取歌曲菜单的id——>歌曲的所有id信息——>播放网站URL的构建,我们所有的一切都是为播放网站参数需要而努力,得到了对应的参数剩下的就很简单。
(1)歌曲菜单界面
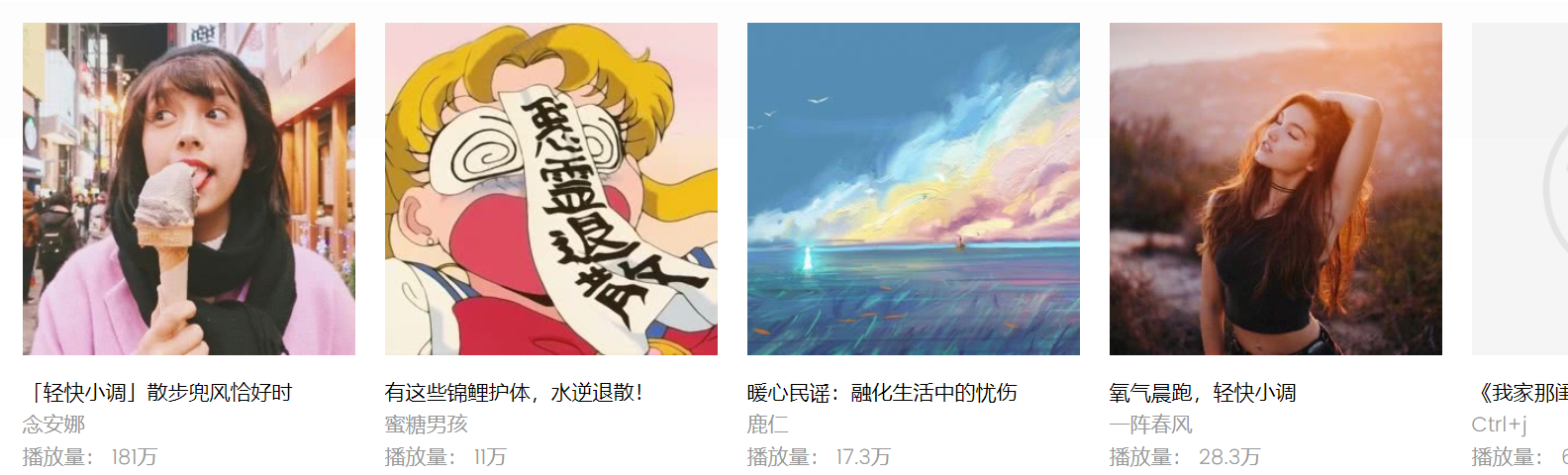
(2)歌曲id信息
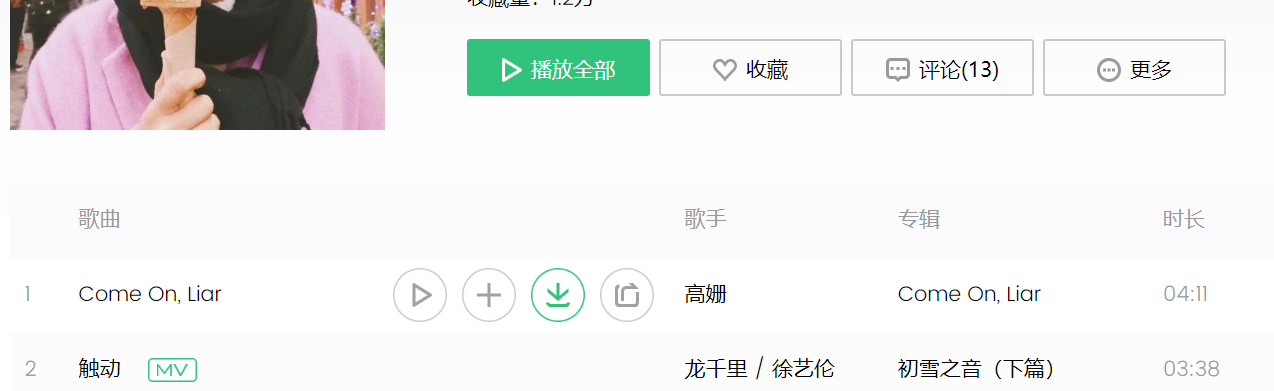
(3)播放网站的解析

三、实施步骤:
爬虫基本的思路都是倒序根据需要的信息一步一步往上推
1.播放界面的请求参数
(1)一个播放界面

(2)另一个播放界面

通过观察我们可以看到,只有vkey参数不一样,而我们的目的也是得到这个vkey参数,这样可以完成对歌曲内容的获取。
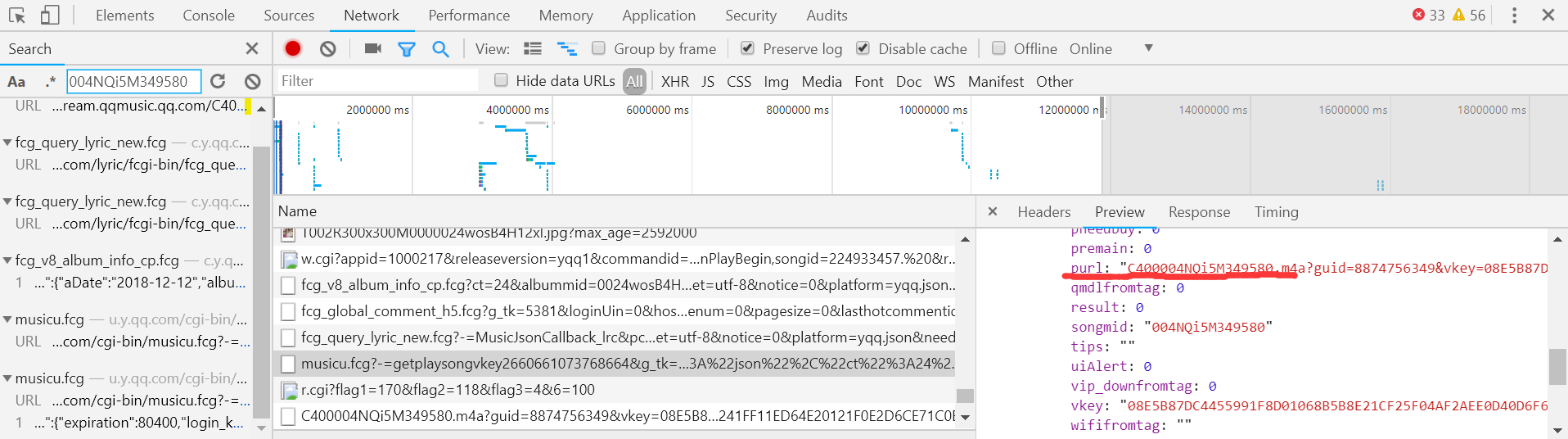
2.查看vkey所在的文件
(1)由于我们是在播放界面点出来的因此需要回到播放界面去查找信息,可以通过对id进行查询,可以看到如图灰色的响应,包含了所有关于歌曲信息的url信息。
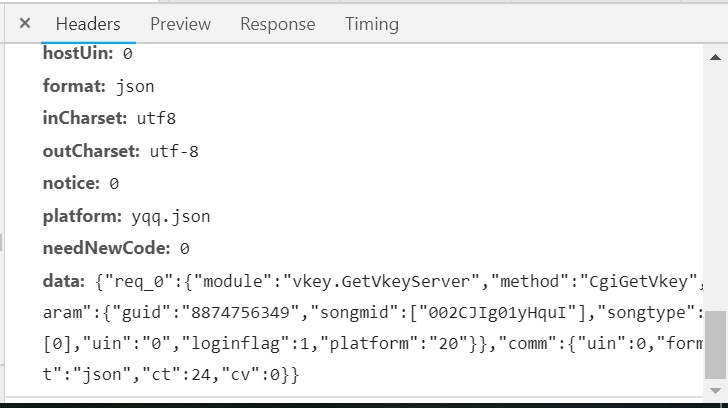
(2)查看参数可以知道我们需要的参数,注意:第一个参数是可有可无的,因此就省去这个参数。
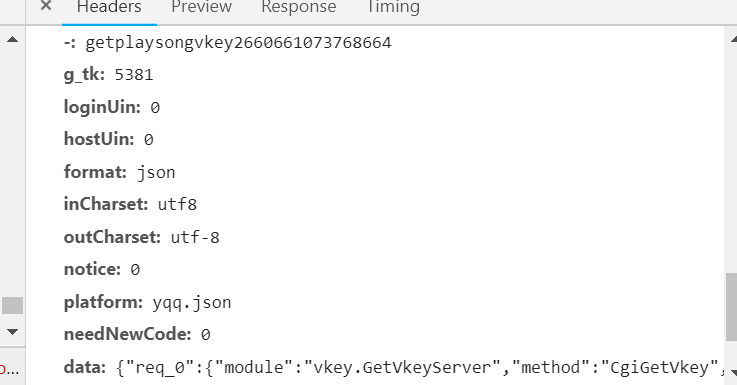
(3)对比参数,查看变量参数,可以看到只有songmid不一样因此在解析的时候只需要songmid需要改变。

3.获取songmid
(1)我们根据响应可以知道我们是通过歌单的信息获取歌曲的列表,在通过歌曲的列表获取歌曲的songmid。
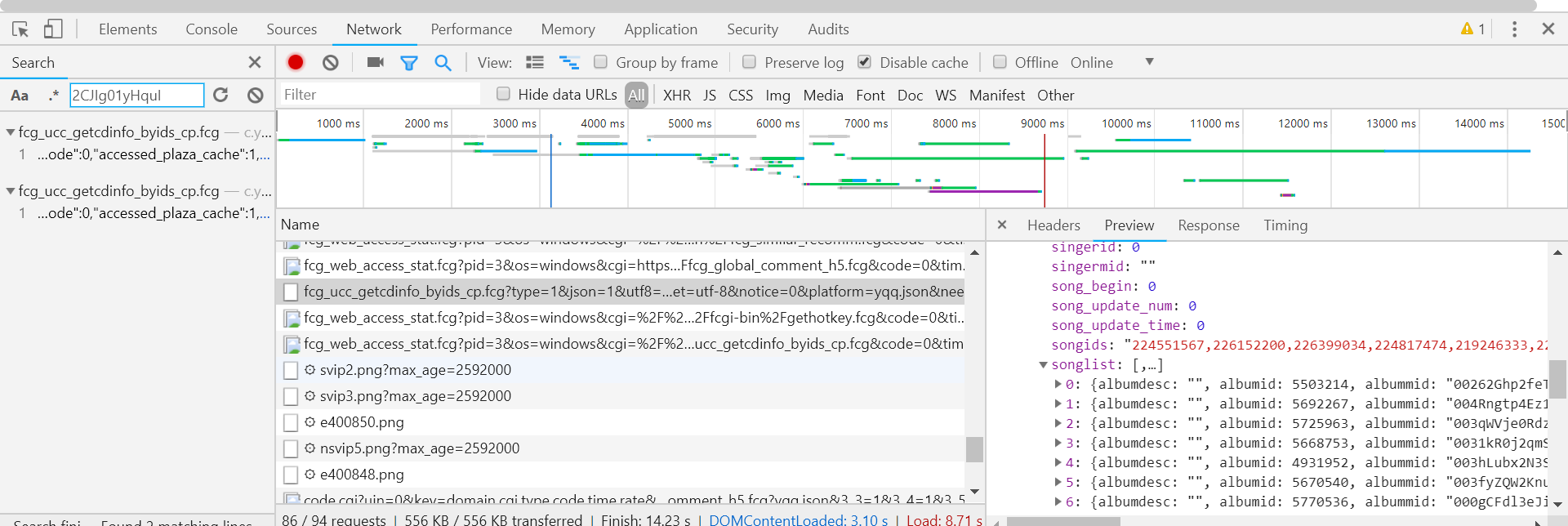
(2)通过获取的song_list获取到songmid

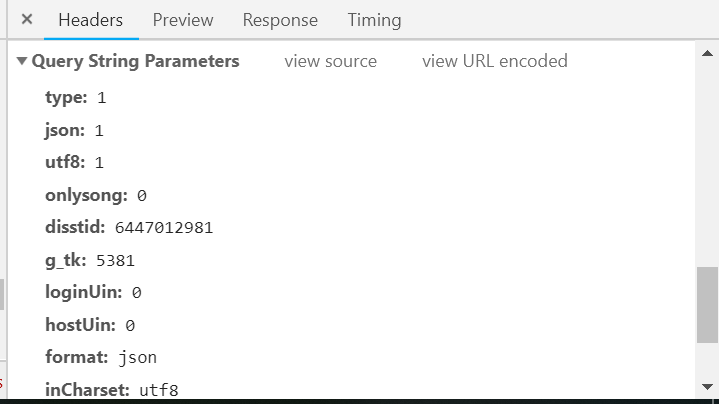
(3)查看请求头的信息,观察变化的参数
1.一个请求头的信息
2.另一个请求头的信息
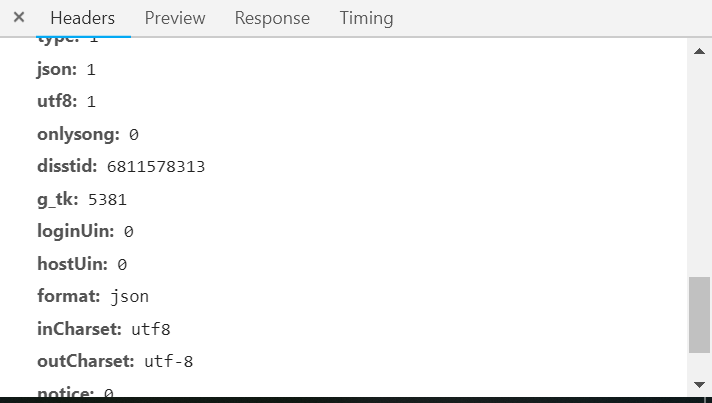
通过请求头都分析我们只需要改变disstid的参数就可以获取到所有的歌曲信息。
4.获取disstid的信息
(1)首先查看disstid在那个文件中
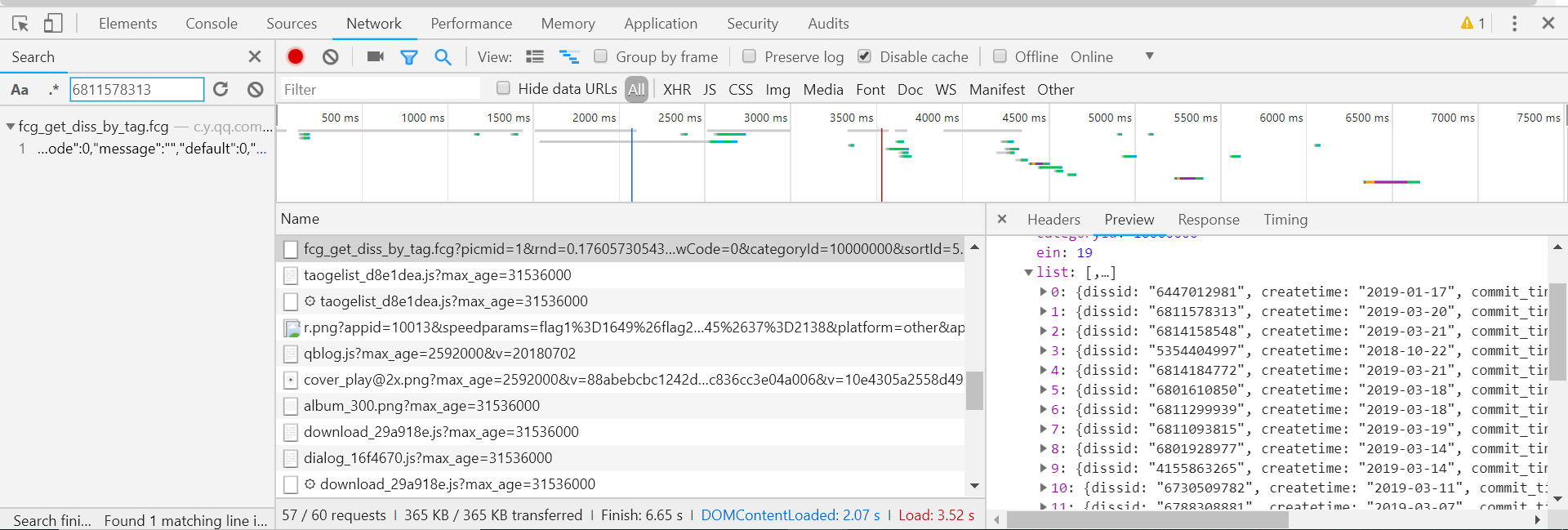
(2)查看请求头,其中rnd的信息可以不要为空就可以了。
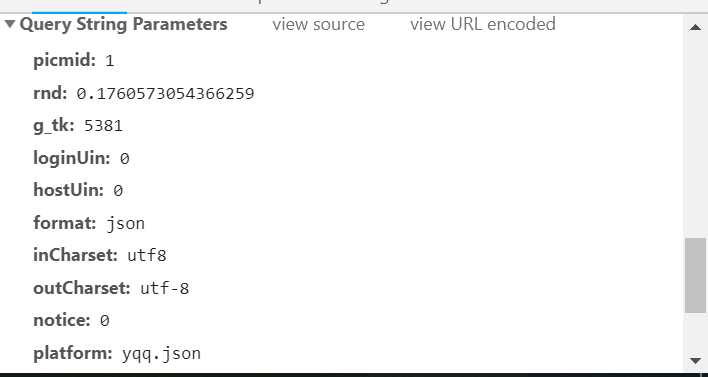
(3)获取disstid
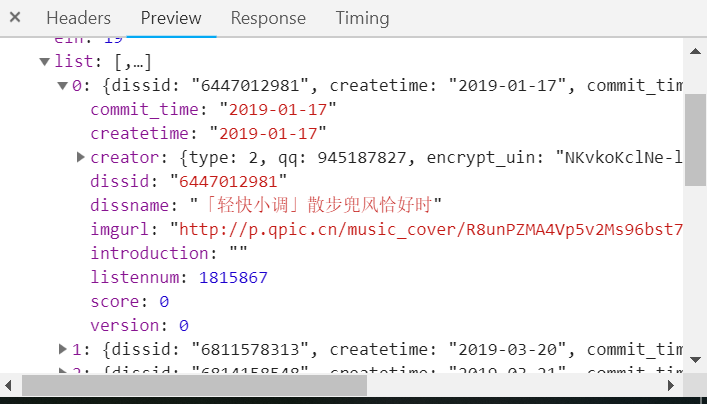
通过倒推的方法,可以成功解析歌曲的信息,剩下的就是代码实现。
四、成果展示与总结:
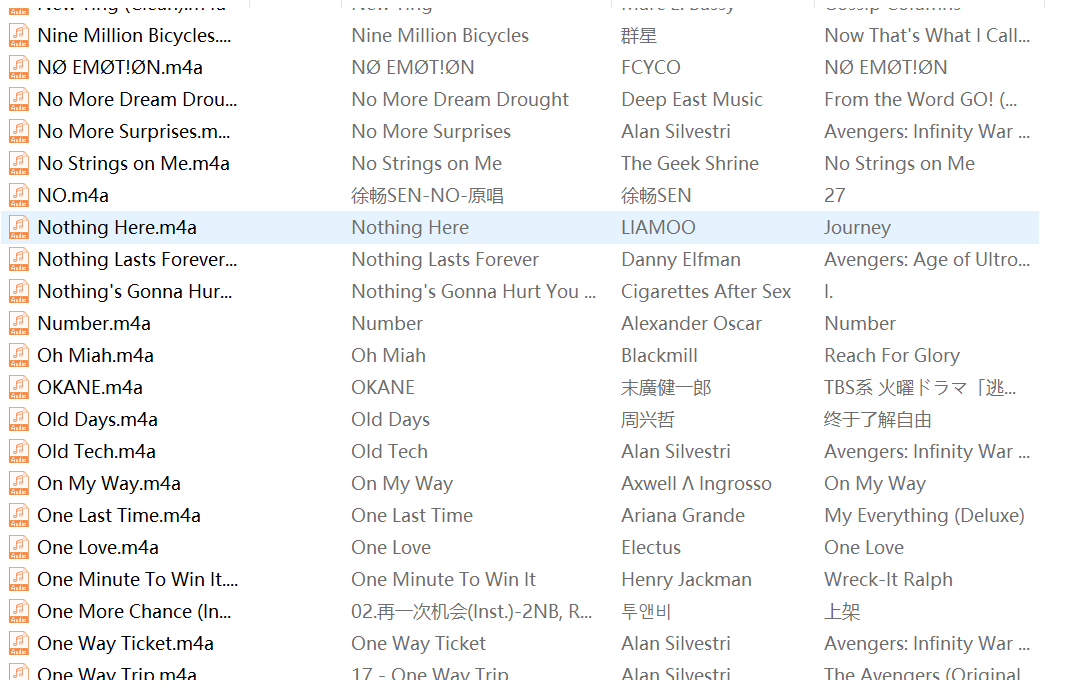
1.展示
2.总结
一步步分析,在解析vkey的时候第一个很奇怪的参数就可以省略,在进行爬虫爬取的时候也要注意这些问题,有时候的参数是可以省略的,因此在构造请求信息的时候就可以省略
参数的信息,由于QQmusic采取的都是json格式的文件,所以在解析的时候比较简单,也很快速,这也是结构化数据的信息的特点。
五、源码:
https://github.com/pzq7025/Spider
爬取QQ音乐(讲解爬虫思路)的更多相关文章
- Python爬虫实战一之爬取QQ音乐
一.前言 前段时间尝试爬取了网易云音乐的歌曲,这次打算爬取QQ音乐的歌曲信息.网易云音乐歌曲列表是通过iframe展示的,可以借助Selenium获取到iframe的页面元素, 而QQ音乐采用的是 ...
- python3 爬取qq音乐作者所有单曲 并且下载歌曲
1 import requests import re import json import os # 便于存放作者的姓名 zuozhe = [] headers = {'User-Agent': ' ...
- 爬取QQ音乐歌手的歌单
import requests# 引用requests库res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search ...
- 爬取qq音乐巅峰榜---内地音乐的榜单
import requestsimport jsonimport sys for i in range(0,10): url = "https://szc.y.qq.com/v8/fcg-b ...
- 手把手教你使用Python抓取QQ音乐数据(第二弹)
[一.项目目标] 通过Python爬取QQ音乐数据(一)我们实现了获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 此次我们在之前的基础上获取QQ音乐指定歌曲的歌词及前15个精 ...
- 手把手教你使用Python抓取QQ音乐数据(第一弹)
[一.项目目标] 获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 由浅入深,层层递进,非常适合刚入门的同学练手. [二.需要的库] 主要涉及的库有:requests.json ...
- 【个人】爬虫实践,利用xpath方式爬取数据之爬取虾米音乐排行榜
实验网站:虾米音乐排行榜 网站地址:http://www.xiami.com/chart 难度系数:★☆☆☆☆ 依赖库:request.lxml的etree (安装lxml:pip install ...
- python+selenium+requests爬取qq空间相册时遇到的问题及解决思路
最近研究了下用python爬取qq空间相册的问题,遇到的问题及解决思路如下: 1.qq空间相册的访问需要qq登录并且需是好友,requests模块模拟qq登录略显麻烦,所以采用selenium的dri ...
- Python爬虫使用selenium爬取qq群的成员信息(全自动实现自动登陆)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: python小爬虫 PS:如有需要Python学习资料的小伙伴可以 ...
随机推荐
- 阿里云 RDS for MySQL 物理备份文件恢复到自建数据库
想把阿里云的Mysql 生成的RAS 文件.tar文件 恢复到本地自建mysql, 遇到的坑.希望帮助大家 阿里云提供的地址 https://help.aliyun.com/knowledge_det ...
- vue Element学习和问题处理
1. resetForm内容没有完全被重置在使用resetForm时,会还原数据到初始化data时的值,有时会出现值已修改,但页面无刷新变化.添加: this.$nextTick(() => { ...
- linux系统下常用的命令(吐血自己整理,且用且珍惜)
1)linux命令太多,有时候记不起来是哪个,为了方便大家查询,自己吐血整理了以下这些,转载时请标明出处,珍惜原创成果 吐血自己整理,且用且珍惜) 吐血自己整理,且用且珍惜) 吐血自己整理,且用且珍惜 ...
- 自学PHP的正确方法与经验
我是2015年开始接触认识到PHP编程方面的知识,2012年我还是一名刚毕业的大学生开始踏入社会从事自己一份学校推荐的自动化职业,自动化工作枯燥无味,每天基本上3点一线,食堂-公司机器-宿舍,做了3年 ...
- 需要转义的java字符(转)
特别字符 说明 $ 匹配输入字符串的结尾位置.如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n' 或‘\r'.要匹配 $ 字符本身,请使用 \$. ( ) 标记一个子 ...
- Harbor私有镜像仓库(上)
上图配置为工作环境 特别注意:win10现在不允许使用私有ca证书,到时登录浏览器会失败,可以选用火狐浏览器. 创建自己的CA证书 openssl req -newkey rsa:4096 -node ...
- 解决Oracle数据库空间不足问题
//查询表空间的大小以及文件路径地址select tablespace_name, file_id, file_name,round(bytes/(1024*1024),0) total_space ...
- openal在vs2010中的配置
下载openal开发工具:相关资料可以在OpenAL官网http://connect.creativelabs.com/openal/default.aspx上获得.这里下载的SDK为OpenAL11 ...
- L2-025 分而治之(并查集)
分而治之,各个击破是兵家常用的策略之一.在战争中,我们希望首先攻下敌方的部分城市,使其剩余的城市变成孤立无援,然后再分头各个击破.为此参谋部提供了若干打击方案.本题就请你编写程序,判断每个方案的可行性 ...
- golang 安装tensorflow
TF_TYPE="cpu" # Change to "gpu" for GPU support //设置环境变量 TARGET_DIRECTORY='/u ...