K-means聚类的Python实现
生物信息学原理作业第五弹:K-means聚类的实现。
转载请保留出处!
原理参考:K-means聚类(上)
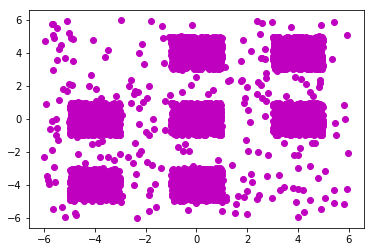
数据是老师给的,二维,2 * 3800的数据。plot一下可以看到有7类。
怎么确定分类个数我正在学习,这个脚本就直接给了初始分类了,等我学会了再发。
下面贴上Python代码,版本为Python3.6。
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 6 16:01:17 2017 @author: zxzhu
"""
import numpy as np
import matplotlib.pyplot as plt
from numpy import random def Distance(x):
def Dis(y):
return np.sqrt(sum((x-y)**2)) #欧式距离
return Dis def init_k_means(k):
k_means = {}
for i in range(k):
k_means[i] = []
return k_means def cal_seed(k_mean): #重新计算种子点
k_mean = np.array(k_mean)
new_seed = np.mean(k_mean,axis=0) #各维度均值
return new_seed def K_means(data,seed_k,k_means):
for i in data:
f = Distance(i)
dis = list(map(f,seed_k)) #某一点距所有种子点的距离
index = dis.index(min(dis))
k_means[index].append(i) new_seed = [] #存储新种子
for i in range(len(seed_k)):
new_seed.append(cal_seed(k_means[i]))
new_seed = np.array(new_seed)
return k_means,new_seed def run_K_means(data,k):
seed_k = data[random.randint(len(data),size=k)] #随机产生种子点
k_means = init_k_means(k) #初始化每一类
result = K_means(data,seed_k,k_means)
count = 0
while not (result[1] == seed_k).all(): #种子点改变,继续聚类
count+=1
seed_k = result[1]
k_means = init_k_means(k=7)
result = K_means(data,seed_k,k_means)
print('Done')
#print(result[1])
print(count)
plt.figure(figsize=(8,8))
Color = 'rbgyckm'
for i in range(k):
mydata = np.array(result[0][i])
plt.scatter(mydata[:,0],mydata[:,1],color = Color[i])
return result[0] data = np.loadtxt('K-means_data')
run_K_means(data,k=7)
附上结果图:
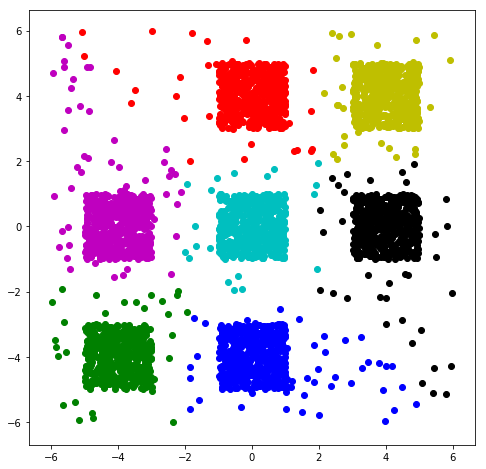
这个算法太依赖于初始种子点的选取了,随机选点很有可能会得到局部最优的结果,所以下一步学习一下怎么设置初始种子点以及分类数目。
K-means聚类的Python实现的更多相关文章
- Python实现kMeans(k均值聚类)
Python实现kMeans(k均值聚类) 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=> ...
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
机器学习算法与Python实践这个系列主要是参考<机器学习实战>这本书.因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学 ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
- 机器学习之路:python k均值聚类 KMeans 手写数字
python3 学习使用api 使用了网上的数据集,我把他下载到了本地 可以到我的git中下载数据集: https://github.com/linyi0604/MachineLearning 代码: ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- K-means聚类 的 Python 实现
K-means聚类 的 Python 实现 K-means聚类是一个聚类算法用来将 n 个点分成 k 个集群. 算法有3步: 1.初始化– K 个初始质心会被随机生成 2.分配 – K 集群通过关联到 ...
- (转) K-Means聚类的Python实践
本文转自: http://python.jobbole.com/87343/ K-Means聚类的Python实践 2017/02/11 · 实践项目 · K-means, 机器学习 分享到:1 原文 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- Kmeans 聚类 及其python实现
主要参考 K-means 聚类算法及 python 代码实现 还有 <机器学习实战> 这本书,当然前面那个链接的也是参考这本书,懂原理,会用就行了. 1.概述 K-means ...
随机推荐
- hbase性能调优_表设计案例
hbase性能调优案例 1.人员-角色 人员有多个角色 角色优先级 角色有多个人员 人员 删除添加角色 角色 可以添加删除人员 人员 角色 删除添加 设计思路 person表 ...
- LNMP环境的搭建
http://blog.csdn.net/wzy_1988/article/details/8438355#
- ADO.NET复习总结(6)-断开式数据操作
一.基础知识 主要类及成员(和数据库无关的)(1)类DataSet:数据集,对应着库,属性Tables表示所有的表(2)类DataTable:数据表,对应着表,属性Rows表示所有的行(3)类Data ...
- React版本更新及升级须知(持续更新)
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; text-align: center; font: 18.0px "PingFang SC Semibold& ...
- ntp 时钟同步
注意: 如果你无法和外部网络的时钟同步,请检查UDP端口时候被封.
- python_8_字典
什么是字典? --key -value 的数据类型,找到key就可以找到对应的值 --字典形式:{key1:value1,key2:value2,......} #!/usr/bin/python3 ...
- javascript 类数组对象
原文:https://segmentfault.com/a/1190000000415572 定义: 拥有length属性,其他属性(索引)为非负整数(对象中的所有会被当做字符串来处理,这里你可以当做 ...
- web、pc、wap、app的区别
通常情况下web=pc,wap=app,前者指电脑用的程序,后者指手机用的程序. 更深层的区别是,pc电脑上软件,web电脑上的网页,wap手机上的网页,app手机用软件
- elasticsearch聚合查询
作者注:本文系作者自己的理解.希望大家多多交流指正 官网java API term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词,所以我们的搜索词必须是文档分词集合中的一个 TermsB ...
- Servlet--HttpServlet类
HttpServlet类 定义 public class HttpServlet extends GenericServlet implements Serializable 这是一个抽象类,用来简化 ...