Java+Selenium爬取高德POI边界坐标
一、写在前面
关于爬取高德兴趣点边界坐标网上有几篇文章介绍实现方式,总的来说就是通过https://www.amap.com/detail/get/detail传入POI的ID值获取数据,BUT,如果实际操作过就会发现,然并卵。
二、主角出场
这里提供一个思路具体怎么应用大家自己把握。Selenium作为Web应用程序自动化测试工具,通过WebDriver实现多种浏览器(包括Chrome、Firefox、IE、Edge等)访问网页、设置代理、设置缓存、切换选项卡,而且还能通过findElement方法类似WebMagic的文档操作功能。
Selenium使用方法分三步
1、引入pom依赖:
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
2、Web浏览器,目前支持的浏览器如图:
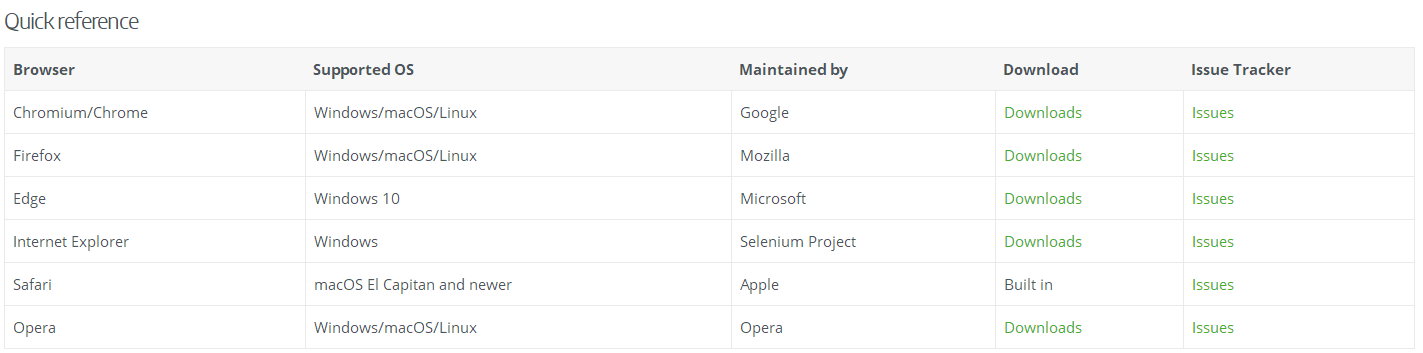
3、下载Web浏览器对应的WebDriver;
三、三部曲之谷歌浏览器
1)安装谷歌浏览器,最好使用安装版的,用便携版可能会出现org.openqa.selenium.WebDriverException: unknown error: cannot find Chrome binary错误,需要设置谷歌浏览器主程序路径,代码如下:
ChromeOptions options = new ChromeOptions();
options.setBinary("Chrome的启动文件路径");
WebDriver driver = new ChromeDriver(options);
2)下载谷歌浏览器对应的WebDriver浏览器驱动程序,需要下载与谷歌浏览器版本对应的驱动程序,下载地址:https://chromedriver.storage.googleapis.com/index.html
3)测试代码:
public class SeleniumChromeTest {
public static void main(String args[]) throws Exception {
ChromeDriver driver = null;
try {
//设置chrome浏览器驱动的所在位置
// 可以设置系统环境变量省略此代码
System.setProperty("webdriver.chrome.driver","C:\\Users\\chromedriver\\chromedriver.exe");
ChromeOptions options = new ChromeOptions();
// 设置IP代理
Proxy proxy = new Proxy();
proxy.setHttpProxy("ip:port");
options.setProxy(proxy);
// Chrome浏览器驱动
driver = new ChromeDriver(options);
// 清理所有cookie
driver.manage().deleteAllCookies();
// 请求POI页面
driver.get("https://www.amap.com/place/B001B0IZY1");
// 跳转到POI边界坐标资源请求接口
driver.navigate().to("https://www.amap.com/detail/get/detail?id=B001B0IZY1&smToken=token&smSign=undefined");
// 打印网页源代码
System.out.println(driver.getPageSource());
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}
测试谷歌浏览器发现即使采用代理IP方式访问,每次都会弹出机器人效验,而且效验一直通过不了,可能浏览器本身发送了自动化测试程序的信息到服务端。
四、三部曲之Edge
换一个”单纯“一点的浏览器。
1)Win10系统自带Edge浏览器,不用额外安装,Win10以下的同学请跳过这段;
2)下载Edge浏览器驱动程序,下载地址https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/,这里有一点要注意Edge内核分为Chromium和EdgeHTML,内核不一样驱动程序也是不一样的,另外根据官方描述:
Microsoft WebDriver for Microsoft Edge version 18 is a Windows Feature on Demand.
To install run the following in an elevated command prompt:
DISM.exe /Online /Add-Capability /CapabilityName:Microsoft.WebDriver~~~~0.0.1.0
For builds prior to 18, download the approriate driver for your installed version of Microsoft
EdgeHTML18的版本不用额外下载驱动程序,直接在CMD中执行如下命令方式安装驱动程序,并且程序中不用设置环境变量
DISM.exe /Online /Add-Capability /CapabilityName:Microsoft.WebDriver~~~~0.0.1.0
3)测试代码参考谷歌浏览器实现。
测试结果,Edge浏览器驱动程序设置IP代理会报错,这是因为Edge的IP代理就是Windows的代理,无法单独对Edge进行代理设置。错误信息如下:
org.openqa.selenium.InvalidArgumentException: The specified arguments passed to the command are invalid.
Edge Chromium内核的没有测试过设置IP代理,有兴趣的同学可以测试一下。
五、三部曲之IE
谷歌和Edge测试完以后发现都有缺陷,最后只能尝试IE浏览器。
1)Windows自带了IE浏览器;
2)下载IE浏览器驱动程序,下载地址:https://selenium-release.storage.googleapis.com/index.html,版本和Selenium版本对应版本选择32为驱动程序,即使是64位操作系统也要选择32位驱动程序,否则会出现指令执行不成功(例如无法获取cookie)等问题,如图:
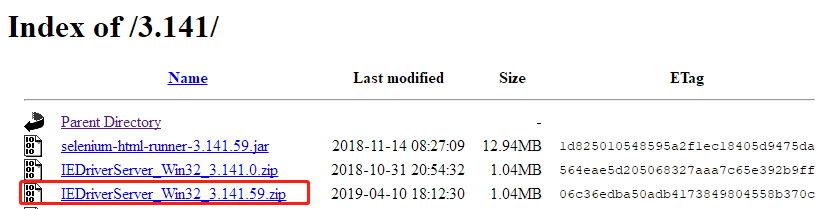
3)测试代码参考谷歌浏览器实现。
测试发现IE浏览器也有个问题,跳转到https://www.amap.com/detail/get/detail页面后IE不会再网页显示JSON数据,而是下提供JSON文件下载。
以上是使用Selenium爬取POI边界坐标的测试过程,如需交流可以发站内信给我。
Java+Selenium爬取高德POI边界坐标的更多相关文章
- java selenium爬取验证图片是否加载完成
爬虫任务里发现有部分图片没有加载完成就进行文件流上传,导致有一些图片是空白,需要判断一下: 首选获取image标签元素: WebElement image = driver.findElement(B ...
- C# HtmlAgilityPack+Selenium爬取需要拉动滚动条的页面内容
现在大多数网站都是随着滚动条的滑动加载页面内容的,因此单纯获得静态页面的Html是无法获得全部的页面内容的.使用Selenium就可以模拟浏览器拉动滑动条来加载所有页面内容. 前情提要 C#HtmlA ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- Scrapy 框架 使用 selenium 爬取动态加载内容
使用 selenium 爬取动态加载内容 开启中间件 DOWNLOADER_MIDDLEWARES = { 'wangyiPro.middlewares.WangyiproDownloaderMidd ...
- 使用selenium爬取网站动态数据
处理页面动态加载的爬取 selenium selenium是python的一个第三方库,可以实现让浏览器完成自动化的操作,比如说点击按钮拖动滚轮等 环境搭建: 安装:pip install selen ...
- scrapy框架 + selenium 爬取豆瓣电影top250......
废话不说,直接上代码..... 目录结构 items.py import scrapy class DoubanCrawlerItem(scrapy.Item): # 电影名称 movieName = ...
随机推荐
- WPF实现类似ChatGPT的逐字打印效果
背景 前一段时间ChatGPT类的应用十分火爆,这类应用在回答用户的问题时逐字打印输出,像极了真人打字回复消息.出于对这个效果的兴趣,决定用WPF模拟这个效果. 真实的ChatGPT逐字输出效果涉及其 ...
- 图加速数据湖分析-GeaFlow和Apache Hudi集成
表模型现状与问题 关系模型自1970年由埃德加·科德提出来以后被广泛应用于数据库和数仓等数据处理系统的数据建模.关系模型以表作为基本的数据结构来定义数据模型,表为二维数据结构,本身缺乏关系的表达能力, ...
- 使用MediatR实现CQRS
CQRS和中介者模式 MediatR库主要是为了帮助开发者快速实现两种软件架构模式:CQRS和Mediator.这两种架构模式看上去似乎差不多,但还是有很多区别的. CQRS CQRS是Command ...
- 《小白WEB安全入门》02. 开发篇
@ 目录 初识HTML潜在漏洞 初识CSS潜在漏洞 初识JS潜在漏洞 初识后端潜在漏洞 后端能做什么 后端种类 后端框架 潜在漏洞 本系列文章只叙述一些超级基础理论知识,极少有实践部分 本文涉及到的语 ...
- API接口的设计思路
API接口设计是软件开发中非常重要的一环,良好的设计规范能够提高开发效率.减少问题和错误,并增强系统的可维护性和可扩展性.本文从程序员的视角,讨论一些常见的API接口设计规范. 一.遵循RESTf ...
- 如何将项目打包上传到NuGet服务器?
作者:西瓜程序猿 主页传送门:https://www.cnblogs.com/kimiliucn 前言 在我写[在.NET Framework中使用RocketMQ(阿里云版)]这篇博客的时候,因为封 ...
- 拓展kmp
Smiling & Weeping ---- 我从不觉得暗恋是苦涩的, 对一个人的喜欢藏在眼睛里, 透过它, 世界都变得更好看了. 题目:P5410 [模板]扩展 KMP(Z 函数) - 洛谷 ...
- DAY005_异或运算
运算规则 二进制:相同为0 相异为1 十进制:相同为0 任何数字和0异或都是它本身 不利用额外变量交换两个数 数组中一种数字出现了奇数次,其他数都出现了偶数次,怎么得到这个出现了奇数次的数 将所有的数 ...
- Three.js中实现一个OBBHelper
1. 引言 Three.js中,Box3对象指的是AABB式的包围盒,这种包围盒会随物体的旋转而变换大小,精度较差 Three.js中还有OBB对象,这是一种能表现物体主要特征的.不随物体的旋转而变换 ...
- IPv6的基本认识
IPv6 1.IPv6的基本认识 IPv4 位数是 32位,4字节,能够提供的IP地址大约是42亿,但你知道的,如今一个人都不止一个IP地址,看看如今设备的数量及发展速度就知道,所以有了IPv6,IP ...