Java+Selenium爬取高德POI边界坐标
一、写在前面
关于爬取高德兴趣点边界坐标网上有几篇文章介绍实现方式,总的来说就是通过https://www.amap.com/detail/get/detail传入POI的ID值获取数据,BUT,如果实际操作过就会发现,然并卵。
二、主角出场
这里提供一个思路具体怎么应用大家自己把握。Selenium作为Web应用程序自动化测试工具,通过WebDriver实现多种浏览器(包括Chrome、Firefox、IE、Edge等)访问网页、设置代理、设置缓存、切换选项卡,而且还能通过findElement方法类似WebMagic的文档操作功能。
Selenium使用方法分三步
1、引入pom依赖:
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
2、Web浏览器,目前支持的浏览器如图:
3、下载Web浏览器对应的WebDriver;
三、三部曲之谷歌浏览器
1)安装谷歌浏览器,最好使用安装版的,用便携版可能会出现org.openqa.selenium.WebDriverException: unknown error: cannot find Chrome binary错误,需要设置谷歌浏览器主程序路径,代码如下:
ChromeOptions options = new ChromeOptions();
options.setBinary("Chrome的启动文件路径");
WebDriver driver = new ChromeDriver(options);
2)下载谷歌浏览器对应的WebDriver浏览器驱动程序,需要下载与谷歌浏览器版本对应的驱动程序,下载地址:https://chromedriver.storage.googleapis.com/index.html
3)测试代码:
public class SeleniumChromeTest {
public static void main(String args[]) throws Exception {
ChromeDriver driver = null;
try {
//设置chrome浏览器驱动的所在位置
// 可以设置系统环境变量省略此代码
System.setProperty("webdriver.chrome.driver","C:\\Users\\chromedriver\\chromedriver.exe");
ChromeOptions options = new ChromeOptions();
// 设置IP代理
Proxy proxy = new Proxy();
proxy.setHttpProxy("ip:port");
options.setProxy(proxy);
// Chrome浏览器驱动
driver = new ChromeDriver(options);
// 清理所有cookie
driver.manage().deleteAllCookies();
// 请求POI页面
driver.get("https://www.amap.com/place/B001B0IZY1");
// 跳转到POI边界坐标资源请求接口
driver.navigate().to("https://www.amap.com/detail/get/detail?id=B001B0IZY1&smToken=token&smSign=undefined");
// 打印网页源代码
System.out.println(driver.getPageSource());
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}
测试谷歌浏览器发现即使采用代理IP方式访问,每次都会弹出机器人效验,而且效验一直通过不了,可能浏览器本身发送了自动化测试程序的信息到服务端。
四、三部曲之Edge
换一个”单纯“一点的浏览器。
1)Win10系统自带Edge浏览器,不用额外安装,Win10以下的同学请跳过这段;
2)下载Edge浏览器驱动程序,下载地址https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/,这里有一点要注意Edge内核分为Chromium和EdgeHTML,内核不一样驱动程序也是不一样的,另外根据官方描述:
Microsoft WebDriver for Microsoft Edge version 18 is a Windows Feature on Demand.
To install run the following in an elevated command prompt:
DISM.exe /Online /Add-Capability /CapabilityName:Microsoft.WebDriver~~~~0.0.1.0
For builds prior to 18, download the approriate driver for your installed version of Microsoft
EdgeHTML18的版本不用额外下载驱动程序,直接在CMD中执行如下命令方式安装驱动程序,并且程序中不用设置环境变量
DISM.exe /Online /Add-Capability /CapabilityName:Microsoft.WebDriver~~~~0.0.1.0
3)测试代码参考谷歌浏览器实现。
测试结果,Edge浏览器驱动程序设置IP代理会报错,这是因为Edge的IP代理就是Windows的代理,无法单独对Edge进行代理设置。错误信息如下:
org.openqa.selenium.InvalidArgumentException: The specified arguments passed to the command are invalid.
Edge Chromium内核的没有测试过设置IP代理,有兴趣的同学可以测试一下。
五、三部曲之IE
谷歌和Edge测试完以后发现都有缺陷,最后只能尝试IE浏览器。
1)Windows自带了IE浏览器;
2)下载IE浏览器驱动程序,下载地址:https://selenium-release.storage.googleapis.com/index.html,版本和Selenium版本对应版本选择32为驱动程序,即使是64位操作系统也要选择32位驱动程序,否则会出现指令执行不成功(例如无法获取cookie)等问题,如图:
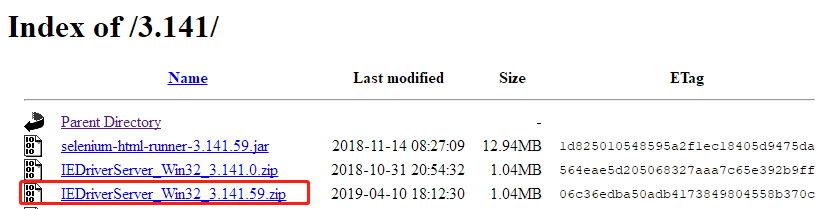
3)测试代码参考谷歌浏览器实现。
测试发现IE浏览器也有个问题,跳转到https://www.amap.com/detail/get/detail页面后IE不会再网页显示JSON数据,而是下提供JSON文件下载。
以上是使用Selenium爬取POI边界坐标的测试过程,如需交流可以发站内信给我。
Java+Selenium爬取高德POI边界坐标的更多相关文章
- java selenium爬取验证图片是否加载完成
爬虫任务里发现有部分图片没有加载完成就进行文件流上传,导致有一些图片是空白,需要判断一下: 首选获取image标签元素: WebElement image = driver.findElement(B ...
- C# HtmlAgilityPack+Selenium爬取需要拉动滚动条的页面内容
现在大多数网站都是随着滚动条的滑动加载页面内容的,因此单纯获得静态页面的Html是无法获得全部的页面内容的.使用Selenium就可以模拟浏览器拉动滑动条来加载所有页面内容. 前情提要 C#HtmlA ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- Scrapy 框架 使用 selenium 爬取动态加载内容
使用 selenium 爬取动态加载内容 开启中间件 DOWNLOADER_MIDDLEWARES = { 'wangyiPro.middlewares.WangyiproDownloaderMidd ...
- 使用selenium爬取网站动态数据
处理页面动态加载的爬取 selenium selenium是python的一个第三方库,可以实现让浏览器完成自动化的操作,比如说点击按钮拖动滚轮等 环境搭建: 安装:pip install selen ...
- scrapy框架 + selenium 爬取豆瓣电影top250......
废话不说,直接上代码..... 目录结构 items.py import scrapy class DoubanCrawlerItem(scrapy.Item): # 电影名称 movieName = ...
随机推荐
- SpringBoot3分库分表
标签:ShardingSphere5.分库.分表: 一.简介 分库分表的设计和实现方式,在之前的内容中总结过很多,本文基于SpringBoot3和ShardingSphere5框架实现数据分库分表的能 ...
- mall :rabbit项目源码解析
目录 一.mall开源项目 1.1 来源 1.2 项目转移 1.3 项目克隆 二.RabbitMQ 消息中间件 2.1 rabbit简介 2.2 分布式后端项目的使用流程 2.3 分布式后端项目的使用 ...
- 【爬虫实战】用python爬豆瓣电影《热烈》短评
目录 一.爬虫对象-豆瓣电影短评 二.爬取结果 三.爬虫代码讲解 三.演示视频 四.获取完整源码 一.爬虫对象-豆瓣电影短评 您好!我是@马哥python说,一名10年程序猿. 今天分享一期爬虫案例, ...
- Note -「SOS DP」高维前缀和
本文差不多算是翻译了一遍 CF blog?id=45223 就是抄了一遍,看不懂可以去原文. 当然我的翻译并不是完全遵从原文的. Part. 1 Introduction 平时我们怎么求高维前缀和?容 ...
- Solution -「ZJOI 2014」力
Descrption Link. 对于每一个 \(i\),求出: \[\sum_{j=1}^{i-1}\frac{a_{j}}{(i-j)^{2}}-\sum_{j=i+1}^{n}\frac{a_{ ...
- 使用Triton部署chatglm2-6b模型
一.技术介绍 NVIDIA Triton Inference Server是一个针对CPU和GPU进行优化的云端和推理的解决方案. 支持的模型类型包括TensorRT.TensorFlow.PyTor ...
- Vue2系列(lqz)——Vue生命期钩子、组件
文章目录 Vue声明期钩子 组件 1 fetch和axios 1.1 fetche使用 1.2 axios的使用 2 计算属性 2.1 通过计算属性实现名字首字母大写 2.2 通过计算属性重写过滤案例 ...
- 【最佳实践】MongoDB导入数据时重建索引
MongoDB一个广为诟病的问题是,大量数据resotore时索引重建非常缓慢,实测5000万的集合如果有3个以上的索引需要恢复,几乎没法成功,而且resotore时如果选择创建索引也会存在索引不生效 ...
- 双数组字典树 (Double-array Trie) -- 代码 + 图文,看不懂你来打我
目录 Trie 字典树 双数组Trie树 构建 字符编码 计算规则 构建 Base Array.Check Array 处理字典首字 处理字典二层字 处理字典三层字 处理字典四层字 叶子节点处理 核心 ...
- 2D物理引擎 Box2D for javascript Games 第五章 碰撞处理
2D物理引擎 Box2D for javascript Games 第五章 碰撞处理 碰撞处理 考虑到 Box2D 世界和在世界中移动的刚体之间迟早会发生碰撞. 而物理游戏的大多数功能则依赖于碰撞.在 ...